-
Concept Summary - taken directly from references
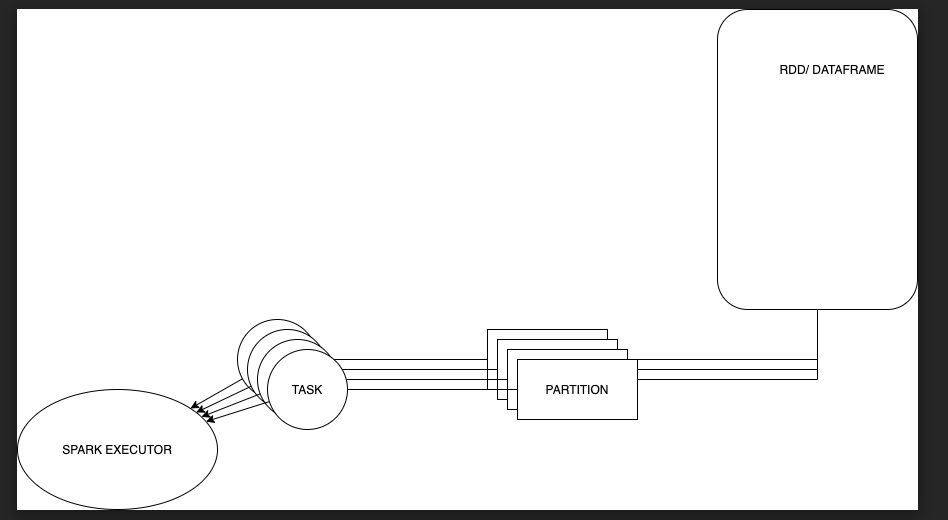
- Spark RDD/DF
- Spark spawns a single Task for a single partition, which will run inside the executor JVM.
- Spark single partition is located in a single machine
- A Stage is a combination of transformations which does not cause any shuffling, pipelining as many narrow transformations (eg: map, filter etc) as possible.
- Each stage contains as many tasks as partitions of the RDD
- Based on other resource this seems to refer that 1 spark task can have multiple transfomations in it filter->map
- Spark book author stackoverflow
- Says If you use ...filter().map(), they will be executed in the same task for each partition, analogous to chaining "mappers" in MapReduce.
- RDDs are not mapped to executors. Multiple partitions from an RDD may be served by multiple tasks which may belong to multiple executors.
-
My draw.io scheme on How Dataframes and RDDs comprise of partitions which is the parallelization unit in Spark
-
References
- From my understanding it seems that both sort merge join and shuffle hash join 1. partition the data but in 2. step the shuffle join creates an hash table (For 1 partition) where shuffle join relies on sorted lists and merging the data. Mostly sorts merge join is preferred
- Databricks video explanation on Spark join optimization
- Medium articles about Spark joins
- Spark join examples 1
- Spark join examples 2
- Spark join optimization
- Sort merge join More thorough explantaion
- Shuffle Hash join, More thorough explanation
- Broadcast Hash join
- Different join stategies