NLTK (Natural Language Toolkit) contains libraries and programs for applied mathematics language process. It's one amongst the foremost powerful IP libraries, that contains packages to form machines perceive human language and reply there to with an acceptable response.
It helps practitioners by providing easy-to-use interfaces to over fifty lexical and corpora resources, with text process libraries for classification, tokenization, tagging, stemming, parsing, and linguistics reasoning, wrappers for industrial-grade NLP libraries. The corpora of information comprises data from numerous applications over the internet; for text analytics, we are able to get knowledge. By analyzing tweets on Twitter, we are able to realize trending news and people’s reactions to a selected event. Amazon will perceive user feedback or review on the particular product. BookMyShow will discover people’s reviews regarding the pic, which may be each positive or negative. Youtube may also analyze and perceive people’s viewpoints on a video.
1.) Tokenization
2.) Stemming
3.) Lemmatization
4.) POS tagging
5.) Chunking
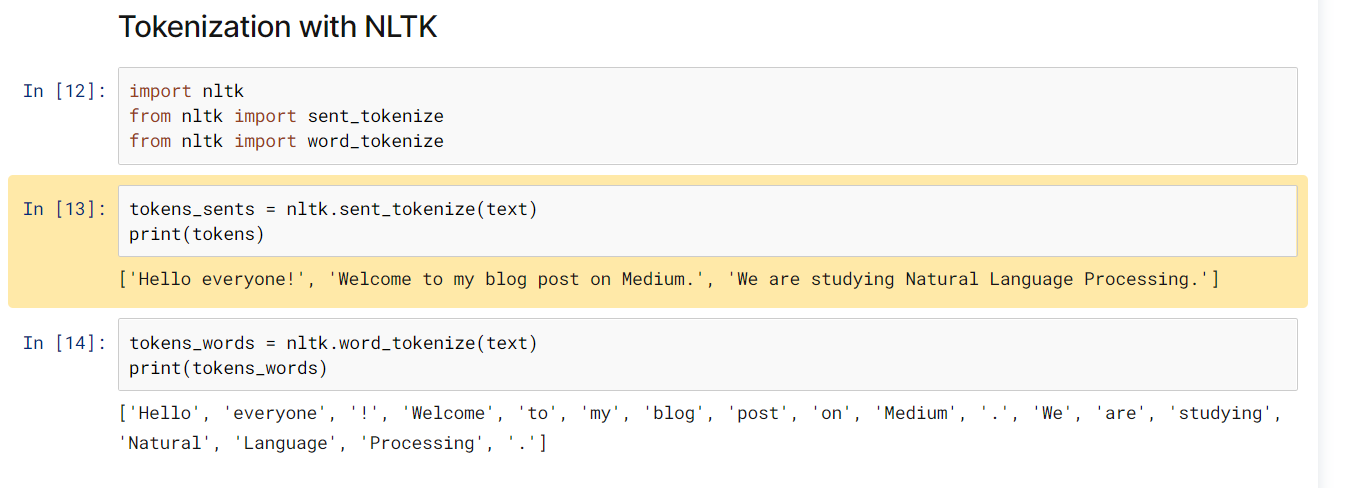
Tokenization is essentially splitting a phrase, sentence, paragraph, or an entire text document into smaller units, such as individual words or terms. Each of these smaller units are called tokens.

image source: https://www.canva.com/design/DAEkntkEywI/mP1tK9cN0WTbgNa3idxcJw/edit
What do you think will happen after we perform tokenization on this string? We get
There are numerous uses of doing this. We can use this tokenized form to:
- Count the number of words in the text
- Count the frequency of the word, that is, the number of times a particular word is present
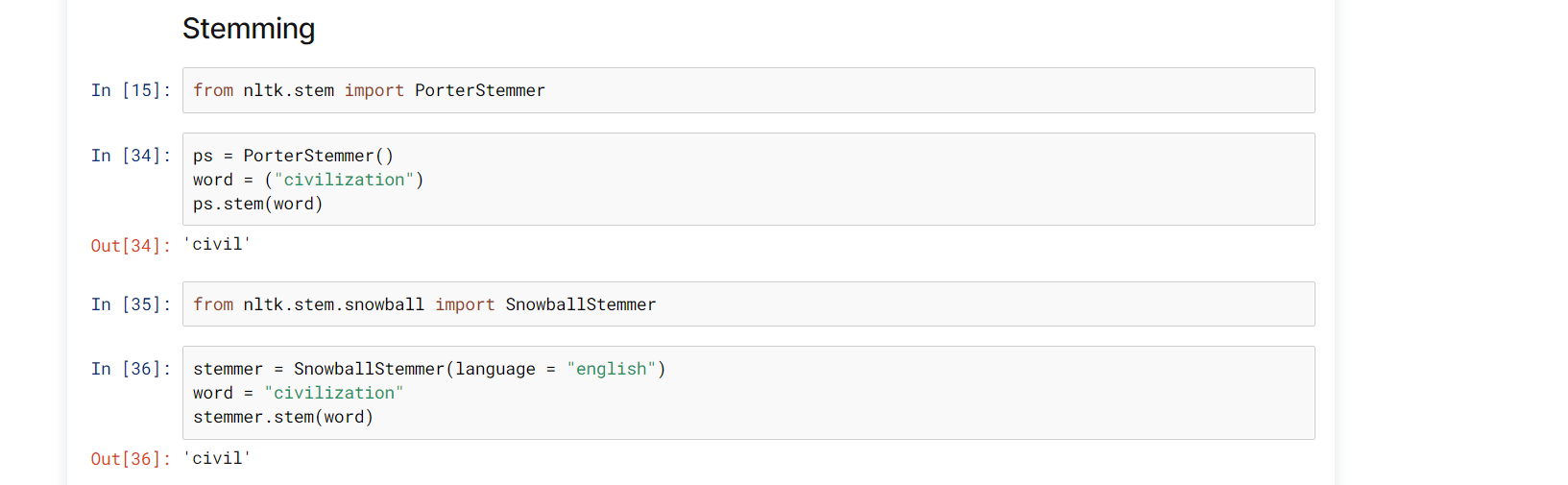
Stemming is the process of producing morphological variants of a root/base word. Stemming programs are commonly referred to as stemming algorithms or stemmers. A stemming algorithm reduces the words “chocolates”, “chocolatey”, “choco” to the root word, “chocolate” and “retrieval”, “retrieved”, “retrieves” reduce to the stem “retrieve”. Stemming is an important part of the pipelining process in Natural language processing. The input to the stemmer is tokenized words. How do we get these tokenized words? Well, tokenization involves breaking down the document into different words. To know in detail about tokenization and its working refer the article :
- "likes"
- "liked"
- "likely"
- "liking"
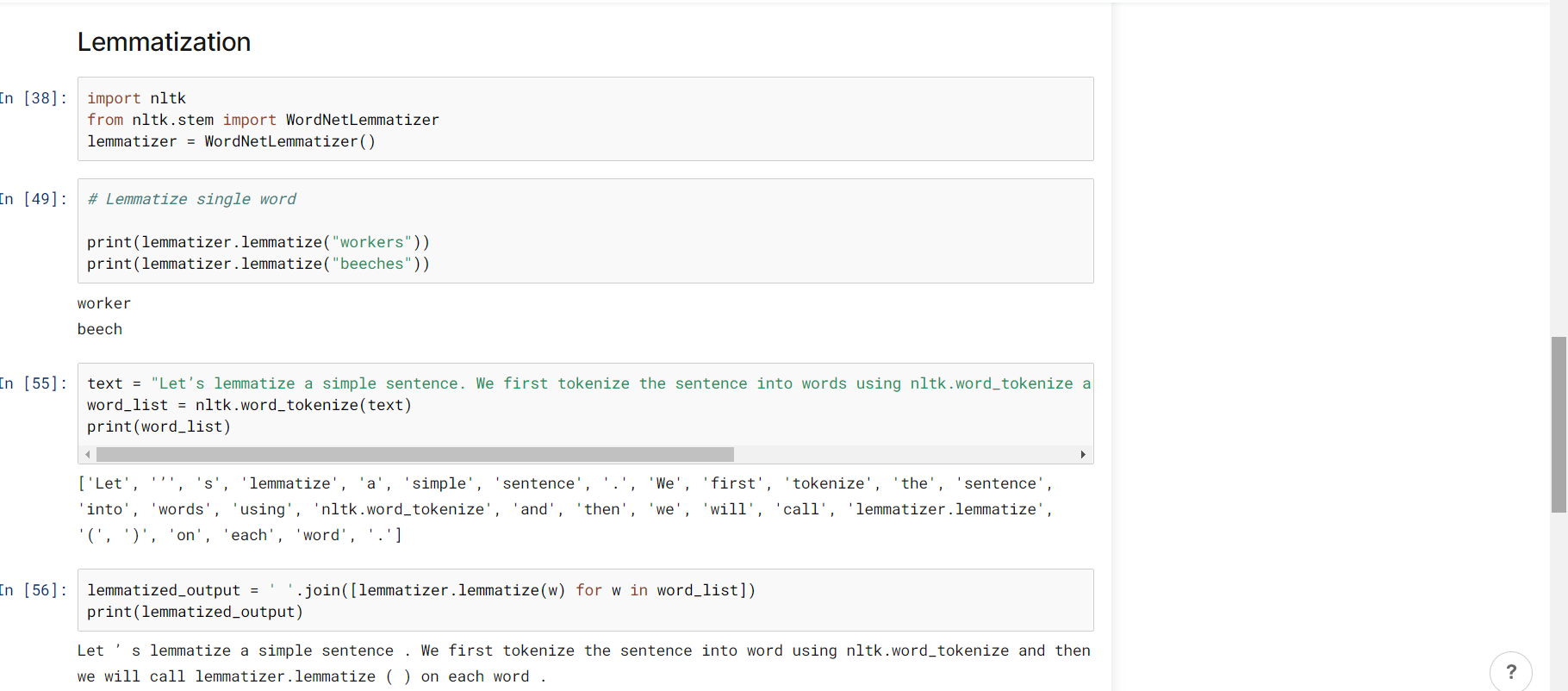
Lemmatization technique is like stemming. The output we will get after lemmatization is called ‘lemma’, which is a root word rather than root stem, the output of stemming. After lemmatization, we will be getting a valid word that means the same thing.
NLTK provides WordNetLemmatizer class which is a thin wrapper around the wordnet corpus. This class uses morphy() function to the WordNet CorpusReader class to find a lemma. Let us understand it with an example
-
import nltk
-
nltk.download('wordnet')
-
from nltk.stem import WordNetLemmatizer
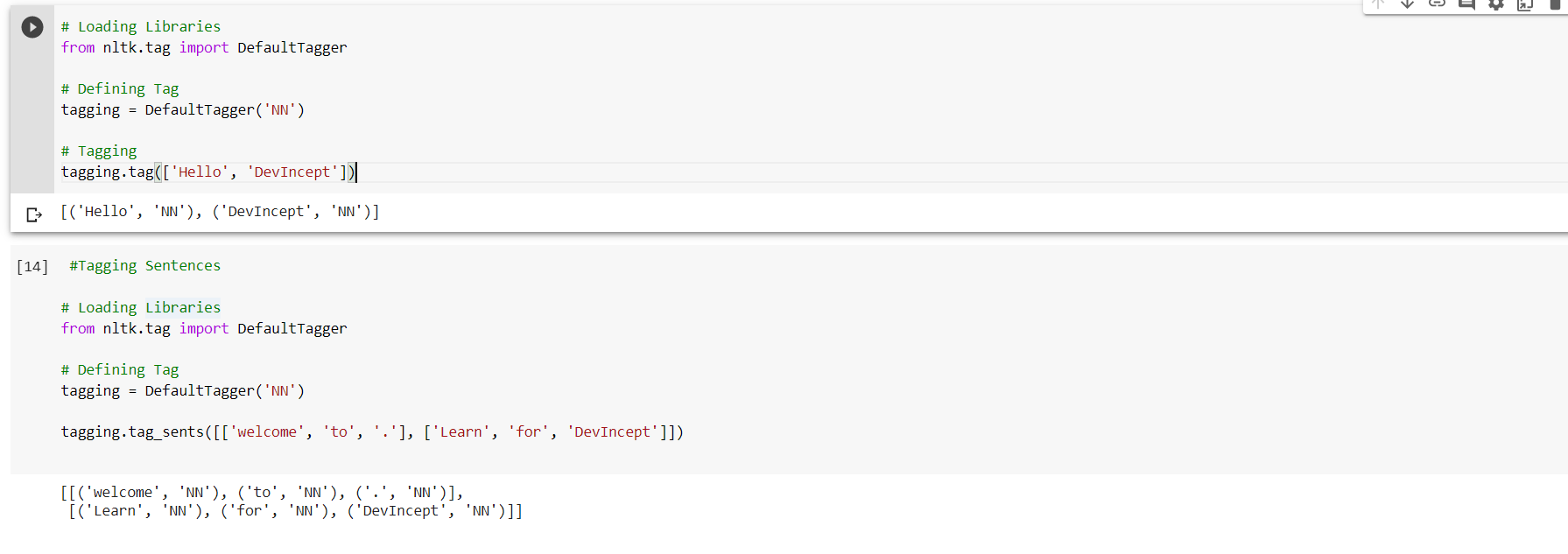
The primary target of Part-of-Speech(POS) tagging is to identify the grammatical group of a given word. Whether it is a NOUN, PRONOUN, ADJECTIVE, VERB, ADVERBS, etc. based on the context. POS Tagging looks for relationships within the sentence and assigns a corresponding tag to the word.
POS Tagging POS Tagging (Parts of Speech Tagging) is a process to mark up the words in text format for a particular part of a speech based on its definition and context. It is responsible for text reading in a language and assigning some specific token (Parts of Speech) to each word. It is also called grammatical tagging.
Input: Everything to permit us.
Output: [('Everything', NN),('to', TO), ('permit', VB), ('us', PRP)]
Steps Involved in the POS tagging example:
- Tokenize text (word_tokenize)
- apply pos_tag to above step that is nltk.pos_tag(tokenize_text)

image source : https://www.learntek.org/blog/categorizing-pos-tagging-nltk-python/
Abbreviation Meaning
- CC - coordinating conjunction
- CD - cardinal digit
- DT - determiner
- EX - existential there
- FW - foreign word
- IN - preposition/subordinating conjunction
- JJ - This NLTK POS Tag is an adjective (large)
- JJR - adjective, comparative (larger)
- JJS - adjective, superlative (largest)
- LS - list market
- MD - modal (could, will)
- NN - noun, singular (cat, tree)
- NNS - noun plural (desks)
- NNP - proper noun, singular (sarah)
- NNPS - proper noun, plural (indians or americans)
- PDT - predeterminer (all, both, half)
- POS - possessive ending (parent\ 's)
- PRP - personal pronoun (hers, herself, him,himself)
- PRP$ - possessive pronoun (her, his, mine, my, our )
- RB - adverb (occasionally, swiftly)
- RBR - adverb, comparative (greater)
- RBS - adverb, superlative (biggest)
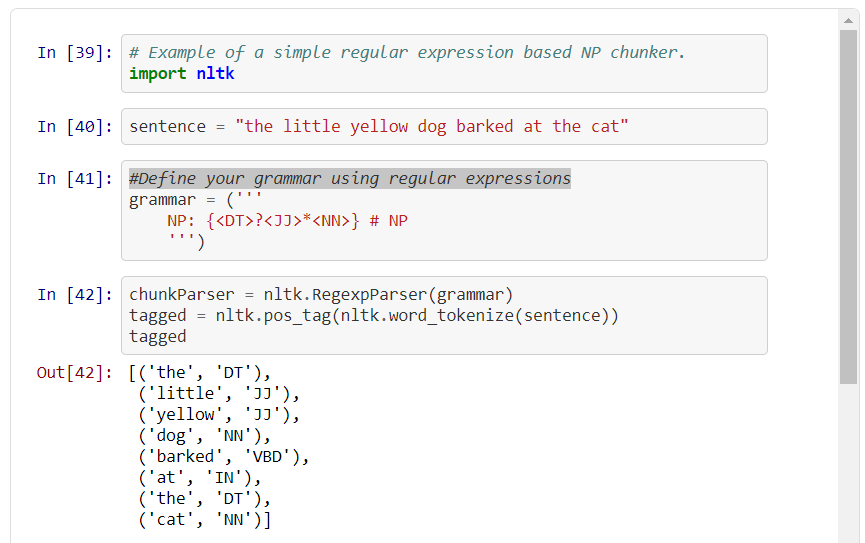
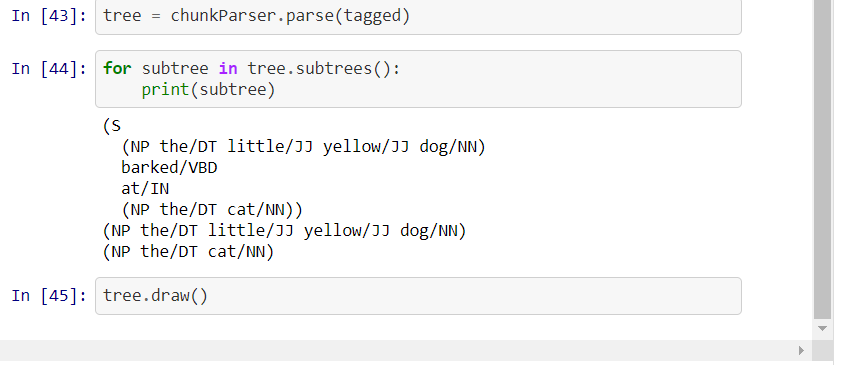
Chunking in NLP is a process to take small pieces of information and group them into large units. The primary use of Chunking is making groups of "noun phrases." It is used to add structure to the sentence by following POS tagging combined with regular expressions. The resulted group of words are called "chunks." It is also called shallow parsing. In shallow parsing, there is maximum one level between roots and leaves while deep parsing comprises of more than one level. Shallow parsing is also called light parsing or chunking.
There are no pre-defined rules, but you can combine them according to need and requirement. For example, you need to tag Noun, verb (past tense), adjective, and coordinating junction from the sentence. You can use the rule as below
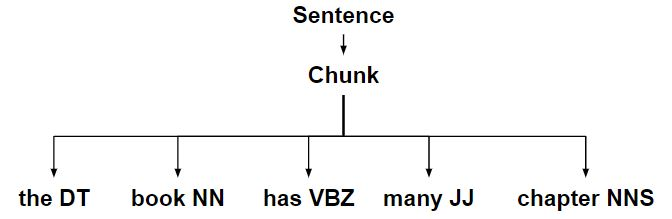
image Source : https://www.geeksforgeeks.org/nlp-chunking-rules/
POS Tagging in NLTK is a process to mark up the words in text format for a particular part of a speech based on its definition and context. Some NLTK POS tagging examples are: CC, CD, EX, JJ, MD, NNP, PDT, PRP$, TO, etc. POS tagger is used to assign grammatical information of each word of the sentence. Installing, Importing and downloading all the packages of Part of Speech tagging with NLTK is complete. Chunking in NLP is a process to take small pieces of information and group them into large units. There are no pre-defined rules, but you can combine them according to need and requirement. Chunking is used for entity detection. An entity is that part of the sentence by which machine get the value for any intention Chunking is used to categorize different tokens into the same chunk.
- https://medium.com/greyatom/learning-pos-tagging-chunking-in-nlp-85f7f811a8cb
- https://www.guru99.com/pos-tagging-chunking-nltk.html
- https://www.analyticsvidhya.com/blog/2019/07/how-get-started-nlp-6-unique-ways-perform-tokeniz
- https://www.datacamp.com/community/tutorials/text-analytics-beginners-nltk
- https://www.geeksforgeeks.org/nlp-part-of-speech-default-tagging/