NLTK (Natural Language Toolkit) contains libraries and programs for applied mathematics language process. It's one amongst the foremost powerful IP libraries, that contains packages to form machines perceive human language and reply there to with an acceptable response.
It helps practitioners by providing easy-to-use interfaces to over fifty lexical and corpora resources, with text process libraries for classification, tokenization, tagging, stemming, parsing, and linguistics reasoning, wrappers for industrial-grade NLP libraries. The corpora of information comprises data from numerous applications over the internet; for text analytics, we are able to get knowledge. By analyzing tweets on Twitter, we are able to realize trending news and people’s reactions to a selected event. Amazon will perceive user feedback or review on the particular product. BookMyShow will discover people’s reviews regarding the pic, which may be each positive or negative. Youtube may also analyze and perceive people’s viewpoints on a video.
Language could be a technique of communication with the assistance of that we are able to speak, scan and write. tongue process (NLP) is that the sub field of engineering science particularly computer science (AI) that's involved regarding enabling computers to grasp and method human language. we've numerous ASCII text file NLP tools however NLTK (Natural Language Toolkit) scores terribly high once it involves the benefit of use and rationalization of the idea. the educational curve of Python is extremely quick and NLTK is written in Python therefore NLTK is additionally having excellent learning kit. NLTK has incorporated most of the tasks like tokenization, stemming, Lemmatization, Punctuation, Character Count, and Word count. it's terribly elegant and simple to figure with.
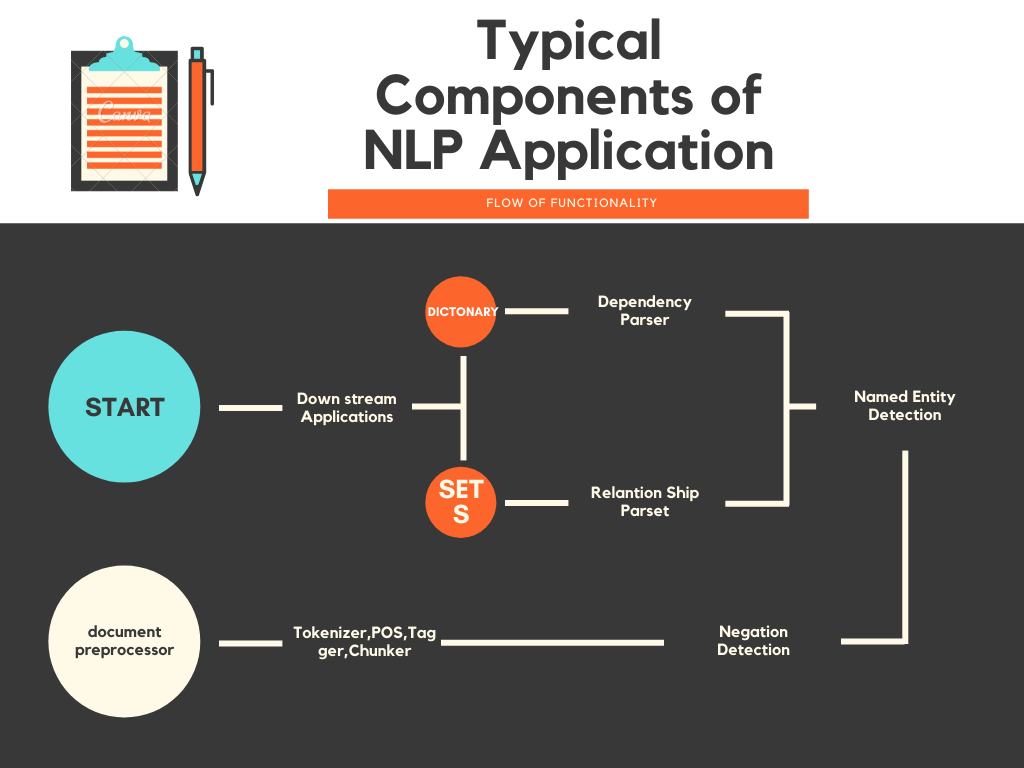
( Image source: https://www.canva.com/design/DAEjzaeq5lY/IsSR8NNIgHgrGLhL80rD-w/edit?layoutQuery=Flowchart# )
Among the above-named natural language processing tool, NLTK scores terribly high once it involves the convenience of use and rationalization of the idea. The learning curve of Python is extremely quick and NLTK is written in Python thus NLTK is additionally having excellent learning kit. NLTK has incorporated most of the tasks like tokenization, stemming, Lemmatization, Punctuation, Character Count, and Word count and is terribly elegant and simple to figure with.
The Natural language toolkit (NLTK) could be a assortment of Python libraries designed particularly for distinguishing and tag components of speech found within the text of natural language like English.The natural language Toolkit (NLTK) could be a platform used for building Python programs that job with human language information for applying in applied mathematics tongue process (NLP). It contains text process libraries for tokenization, parsing, classification, stemming, tagging and linguistics reasoning.
NLTK (Natural Language Toolkit) is a suite that contains libraries and programs for applied mathematics language process. it's one amongst the foremost powerful natural language processing libraries, that contains packages to create machines perceive human language and reply theret o with an acceptable response.
What this implies is it gets everything associated with a specific search question. Let’s say you would like to undertake to urge every bit of knowledge concerning the most well liked topic within the world nowadays, COVID-19 or Coronavirus, you'd specify thus within the “query” parameter within the on top of perform. The “from_param” parameter and “to” parameter within the on top of perform square measure the date parameters. it's asking you to specify the timeframe that you would like to urge results for the search question. Since i discussed, i would like to urge all results for a amount of thirty days that is that the most allowed timeframe for the free version, i'll specify the from_param because the day thirty days before today’s date. However, i want to put in writing this during a loop so I will guarantee i'm obtaining each day.
Collect and annotate training information that meets and exceeds trade quality standards due to multiple internal control ways and mechanisms accessible in Toloka.
Have any amounts of image, text, speech, audio or video information collected and labelled for you by variant skilled Toloka users across the world.
Save time and cash with this purposeful platform for handling large-scale information assortment and annotation comes, on demand 24/7, at your own worth and among your timeframe.
Build climbable and absolutely machine-controlled human-in-the-loop machine learning pipelines with a strong open API and Python library for simple integration.
NLTK is one of the leading platforms for building Python programs that can work with human language data. It presents a practical introduction to programming for language processing. NLTK comes with a host of text processing libraries for sentence detection, tokenization, lemmatization, stemming, parsing, chunking, and POS tagging.
NLTK provides easy-to-use interfaces to over 50 corpora and lexical resources. The tool has the essential functionalities required for almost all kinds of natural language processing tasks with Python.
- pip install nltk
.png)
.png)
- Stemming
- Recommendation
- Sentiment analysis
- Translation
Download NLTK – you can download NLTK with nltk.download()
You can import NLTK directly using import.
import nltk
Importing dataset from corpus Some simple operations with NLTK
Tokenizing means breaking down large words or sentences into smaller length form, which helps to clean the data for processing and classification.
To tokenize words means to break down a sentence into an array of words.
To tokenize sentences is to break down long sentences into parts that differ by breakpoints.
A part-of-speech tagger(POS-tagger) generally processes word-sequences; for each word, it attaches a part of speech. The tokenization concept should be used to achieve this. (Tokenization is the process of dividing the quantity of text into smaller pieces called tokens.)
Lemmatization technique is like stemming. The output we are going to get once lemmatization is named ‘lemma’, that could be a stem instead of root stem, the output of
stemming. once lemmatization, we are going to be obtaining a sound word which means a similar issue.
NLTK provides WordNetLemmatizer category that could be a skinny wrapper round the wordnet corpus. This category uses morphy() operate to the WordNet CorpusReader category to search out a lemma. allow us to are aware of it with Associate in Nursing example.
-
import nltk
-
nltk.download('wordnet')
-
from nltk.stem import WordNetLemmatizer
-
wnl = WordNetLemmatizer()
-
list1 = ['kites', 'babies', 'dogs', 'flying', 'smiling', 'driving', 'died', 'tried', 'feet']
-
for words in list1: print(words + " ---> " + wnl.lemmatize(words))

It may be outlined as the method of breaking apart a chunk of text into smaller components, like sentences and words. These smaller components square measure referred to as tokens. for instance, a word is a token in an exceedingly sentence, and a sentence could be a token in an exceedingly paragraph.
As we all know that NLP is employed to make applications like sentiment analysis, QA systems, language translation, good chatbots, voice systems, etc., hence, so as to make them, it becomes important to grasp the pattern within the text. The tokens, mentioned higher than, square measure terribly helpful to find and understanding these patterns. we are able to take into account tokenization because the base step for different recipes like stemming and lemmatization.
nltk.tokenize is that the package provided by NLTK module to realize the method of tokenization.
Tokenizing sentences into words Splitting the sentence into words or making an inventory of words from a string is a vital a part of each text process activity. allow us to are aware of it with the assistance of varied functions/modules provided by nltk.tokenize package.
(a) Import the NLTK module and download the text resources needed for the examples.

(b) Take a sentence and tokenize into words. Then apply a part-of-speech tagger.

(c) From the tagged words, identify the proper names

(d) Get texts for corpus analysis

(e) Find words with similar concordance to a given word

(f) Plot where in the text certain words appear

(g) Print the identity of a text, the length of the text and its vocabulary

(h) Print some statistics of word occurrence in the text

Named entity recognition (NER), or named entity extraction is a keyword extraction technique that uses natural language processing (NLP) to automatically identify named entities within raw text and classify them into predetermined categories, like people, organizations, email addresses, locations, values, etc.
A simple example:

Using NER, you can automate endless tasks, with almost no human intervention.
MonkeyLearn is a SaaS platform with an array of pre-built NER tools and SaaS APIs in Python, like person extractor, company extractor, location extractor, and more.
The API tab shows how to integrate using your own Python code (or Ruby, PHP, Node, or Java). Start with performing NER with MonkeyLearn’s Python API on the pre-built company extractor. The API will access the extractor automatically:
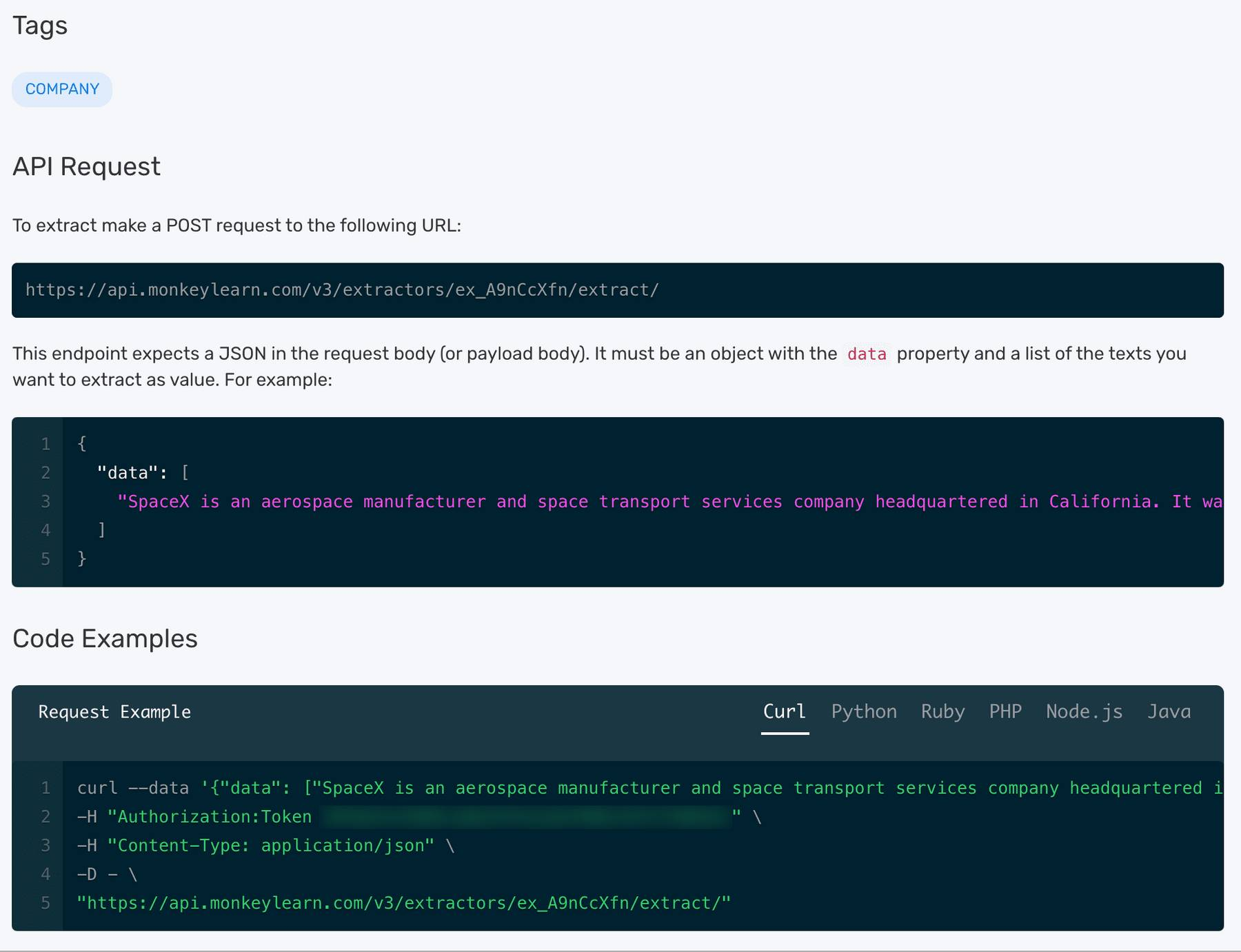
Plain requests can be sent to the MonkeyLearn API and JSON responses can be parsed yourself, but MonkeyLearn offers easy integration with SDKs in a number of languages.
Sign up to get your API key then download and install the Python SDK:
pip install monkeylearn
As now everything is set up, enter the below to start running MonkeyLearn’s NER analysis:
rom monkeylearn import MonkeyLearn
ml = MonkeyLearn('<<Your API key here>>')
model_id = 'ex_A9nCcXfn'
data = ['first text', {'text': 'DevIncept is An environment, where you not only have to read or watch videos but interactive modules where you can test your skills and compete with other participants. ', 'external_id': 'ANY_ID'}, '']
response = ml.extractors.extract(model_id, data=data)
print(response.body)
The result will is a Python dict generated from the JSON sent by MonkeyLearn – in the same order as the input text – and should look something like this:
[
{
'text': 'first text',
'external_id': None,
'error': False,
'extractions': []
}, {
'text': 'DevIncept is An environment, where you not only have to read or watch videos but interactive modules where you can test your skills and compete with other participants.',
'external_id': 'ANY_ID',
'error': False,
'extractions': [{
'tag_name': 'COMPANY',
'extracted_text': 'DevIncept',
'parsed_value': 'DevIncept',
'count': 1
}]
}, {
'text': '',
'external_id': None,
'error': True,
'error_detail': 'Invalid text, empty strings are not allowed',
'extractions': None
}
]
Now as everything is set up, we can perform NER automatically. You can change the models to try out something new or create your own model, then call it with Python.
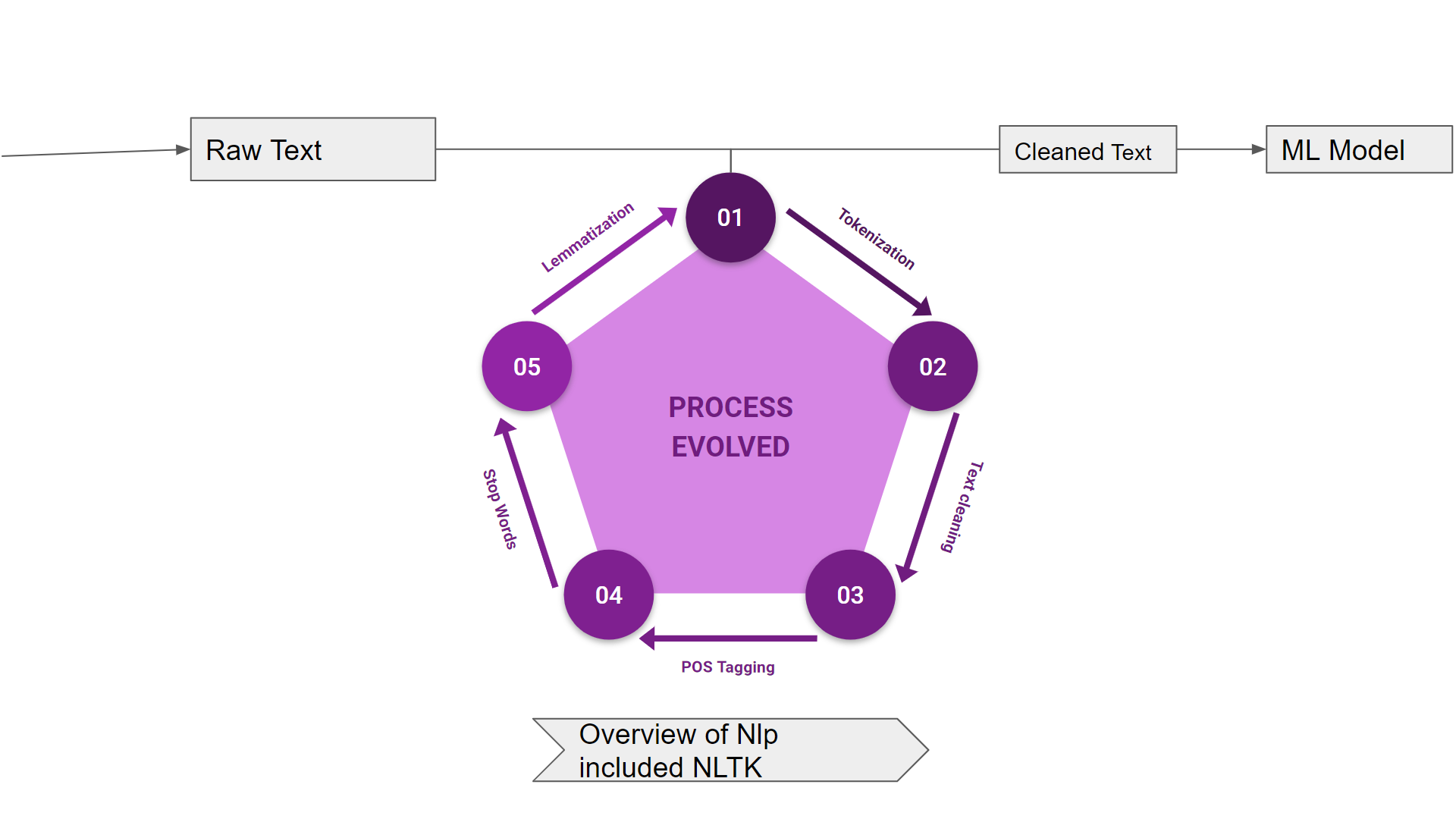
( Image source :https://medium.com/mlearning-ai/basic-steps-in-natural-language-processing-pipeline-763cd299dd99 )
-
Natural Language Toolkit
NLTK is a leading platform for building Python programs to figure with human language information. It provides easy-to-use interfaces to over fifty corpora and lexical
resources like WordNet, along side a set of text process libraries for classification, tokenization, stemming, tagging, parsing, and linguistics reasoning, wrappers for weapons-grade human language technology libraries, and an energetic discussion forum. -
Due to a active guide introducing programming fundamentals aboard topics in linguistics, and comprehensive API documentation, NLTK is appropriate for linguists, engineers, students, educators, researchers, and trade users alike. NLTK is offered for Windows, Mac OS X, and Linux. better of all, NLTK could be a free, open supply, community-driven project.
-
NLTK has been referred to as “a tremendous tool for teaching, and dealing in, linguistics exploitation Python,” and “an superb library to play with natural language”
-
Natural language process with Python provides a sensible introduction to programming for language process. Written by the creators of NLTK, it guides the reader through the basics of writing Python programs, operating with corpora, categorizing text, analyzing linguistic structure, and more. the web version of the book has been been updated for Python three and NLTK three.
[1] https://www.tutorialspoint.com/natural_language_processing/natural_language_processing_tutorial.pdf
[2] https://www.guru99.com/nltk-tutorial.html
[3] https://www.e2enetworks.com/introduction-to-nltk-and-text-analytics/
[4] https://colab.research.google.com/github/mhuckvale/pals0039/blob/master/Tutorial_NLTK.ipynb
[5] https://realpython.com/nltk-nlp-python/
[6] https://towardsdatascience.com/
[7] https://medium.com/mlearning-ai/basic-steps-in-natural-language-processing-pipeline-763cd299dd99
[8] https://www.canva.com/design/DAEjzaeq5lY/IsSR8NNIgHgrGLhL80rD-w/edit?layoutQuery=Flowchart
[9] https://www.sciencedirect.com/topics/mathematics/real-world-data