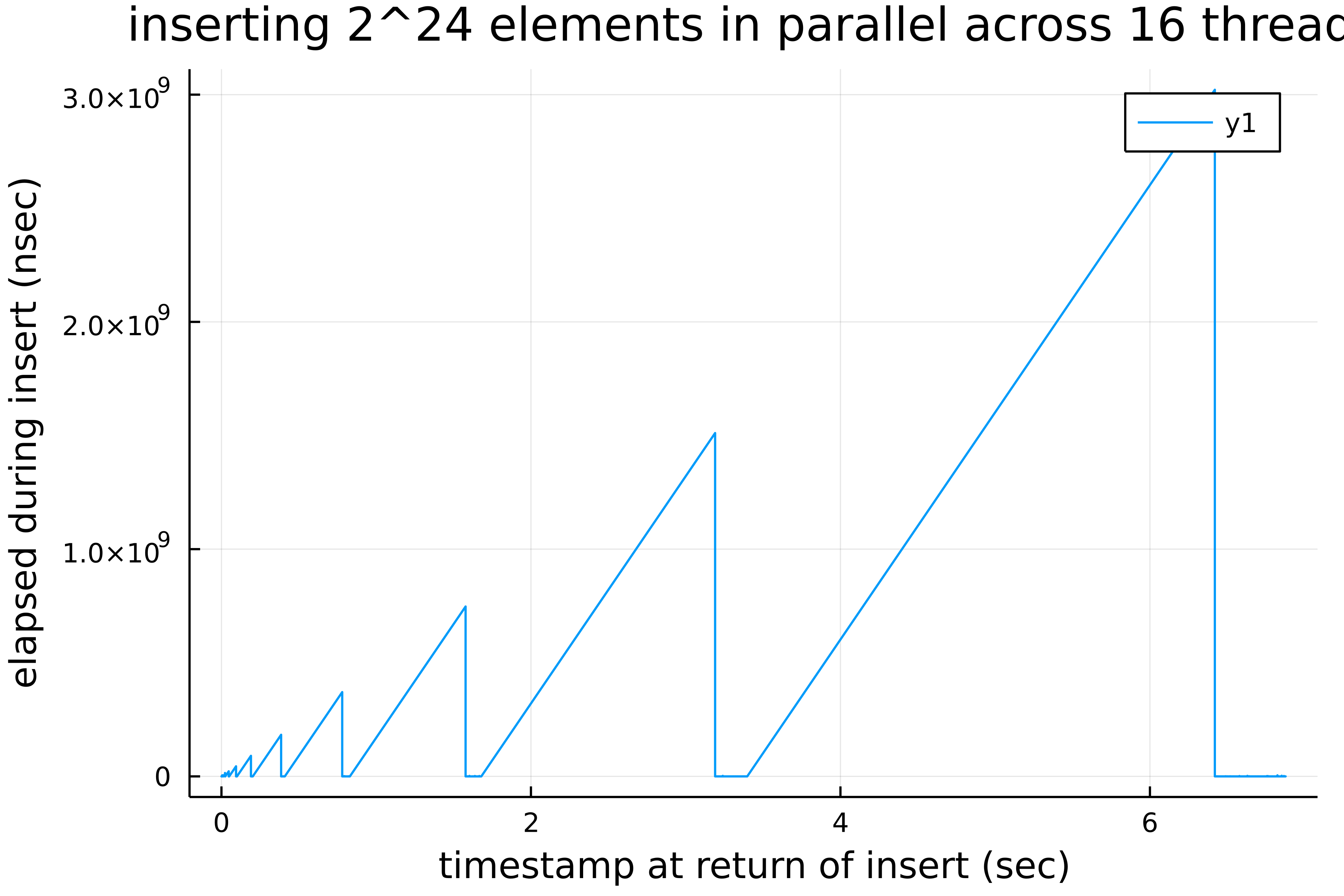
Parallel insertion workloads have some significant latency spikes when a rehashing into a new BucketArray is triggered. This is likely because rehashing will block all insertion threads when it happens, and the work to be done is duplicated between all threads, resulting in a high degree of contention. The following plot shows the big latency spikes induced by rehashing for a unique-key-only insertion workload, spread across 16 CPUs on a 16 CPU system:
Possible solutions to address this might include:
- Have rehashing threads start at random offsets into the bucket array. This will reduce thread contention probabilistically, but there remains the same amount of work to be done
- Come up with some kind of scheme to evenly split work between the threads. I don't like this, because I think it will require explicit synchronization between threads that otherwise have no knowledge of each other
- Rehash incrementally. This means there is no latency spike at all for any thread, at the cost of some lookup performance
What would rehashing incrementally look like? Let's assume that we never shrink the hash table. This would mean that:
- Each bucket array is twice the size of the previous
- If we never delete a bucket array (I would like to not do this), there are no more than O(log2(N)) bucket arrays per hash table
- If we bound the probe depth to some constant factor C (4 should be plenty more than enough) and rehash on probe depth getting too long, we can guarantee lookups are O(C log2(N)), or alternatively O(log2(N))
The biggest risk that I see here will be, how do we run garbage collection on those old tables? When can we remove all references to them, and how do we do that without causing a memory error?
Parallel insertion workloads have some significant latency spikes when a rehashing into a new
BucketArrayis triggered. This is likely because rehashing will block all insertion threads when it happens, and the work to be done is duplicated between all threads, resulting in a high degree of contention. The following plot shows the big latency spikes induced by rehashing for a unique-key-only insertion workload, spread across 16 CPUs on a 16 CPU system:Possible solutions to address this might include:
What would rehashing incrementally look like? Let's assume that we never shrink the hash table. This would mean that:
The biggest risk that I see here will be, how do we run garbage collection on those old tables? When can we remove all references to them, and how do we do that without causing a memory error?