The goal of caching the Key (K) and Value (V) states is to speedup the inference of autoregressive decoder like GPT.
During the practical, we started to adapt the code of minGPT from Karpathy in order to incorporate KV-caching. The goal of the first part of this homework is to finish the practical by completing kv_cache.py and running a small benchmark. We will only need the two main files model.py and trainer.py from Karpathy's repo. You will find these files in the mingpt folder (no changes are needed for these files).
Using Named Tensor Notation, we write (see the paper by Chiang, Rush and Barak)
During inference, when we compute the attention for the
where
For the computation at time
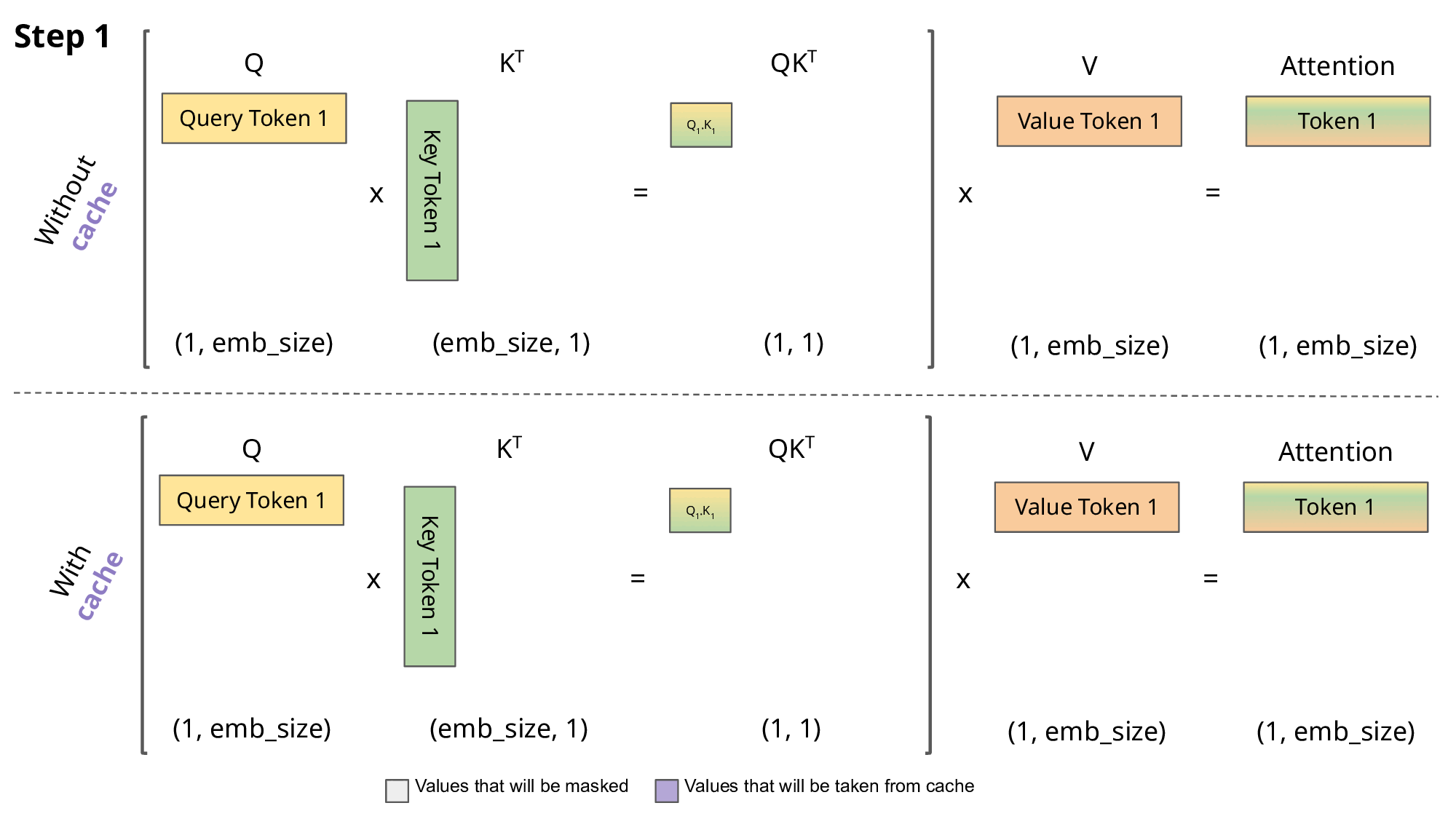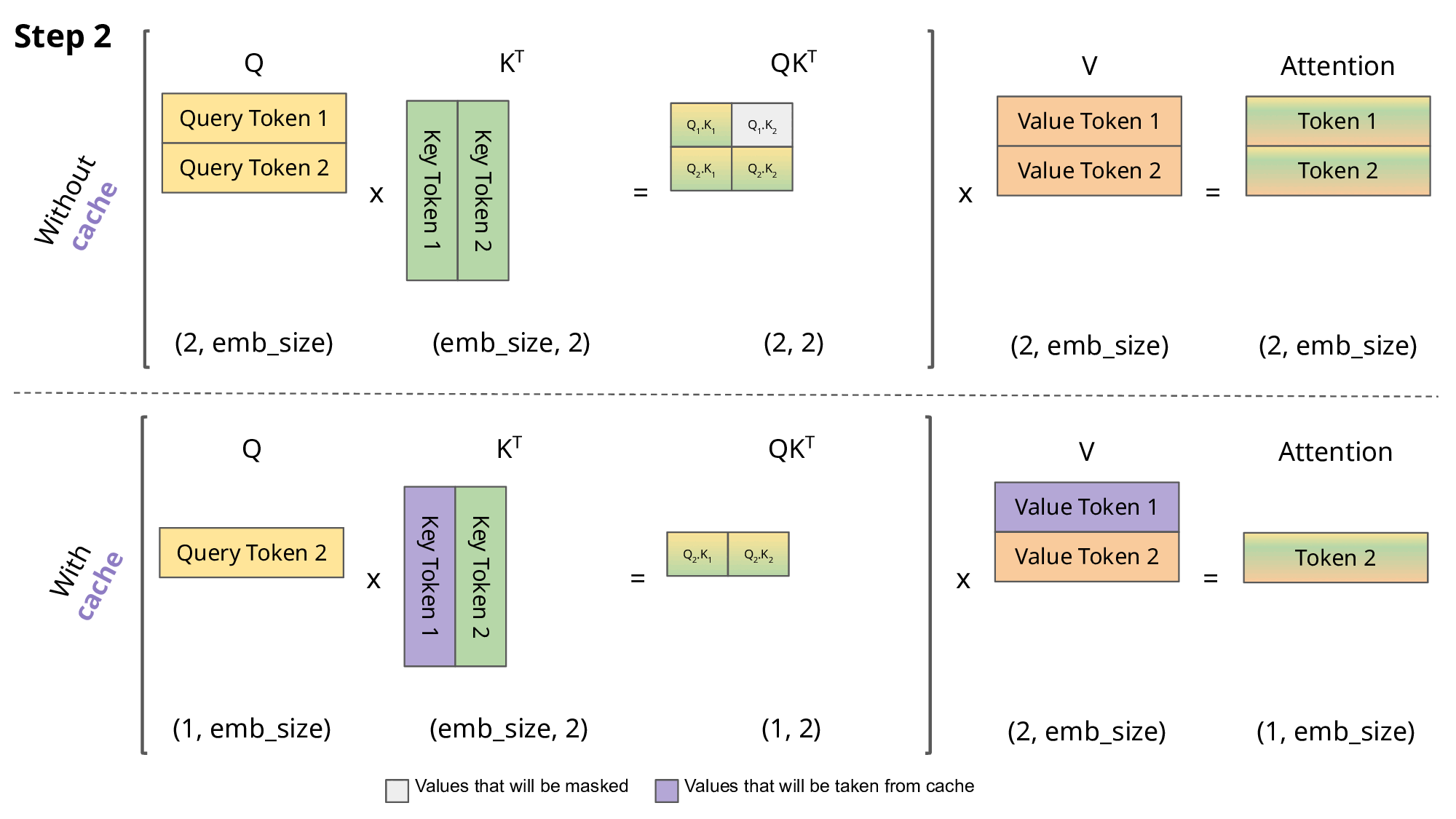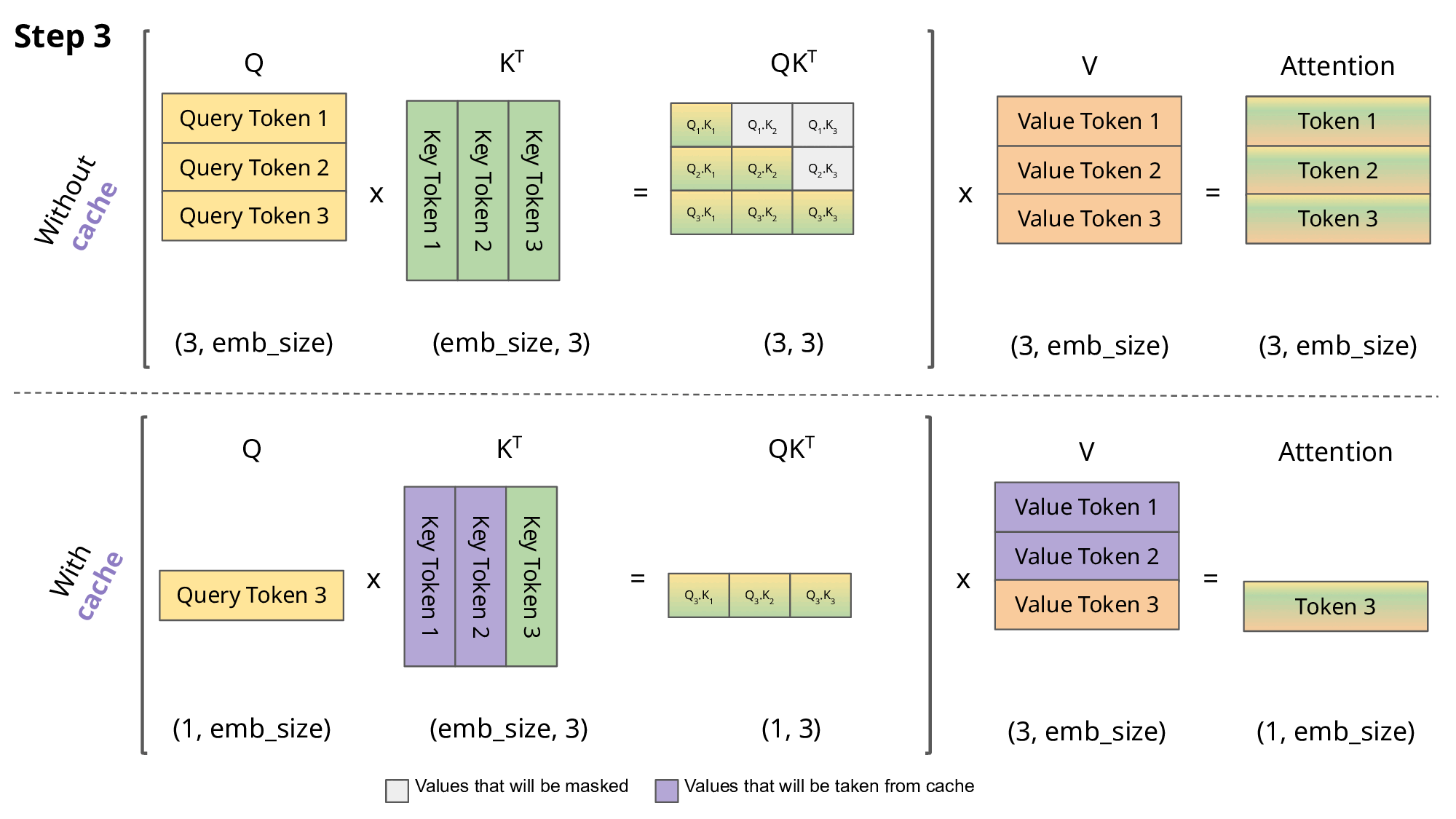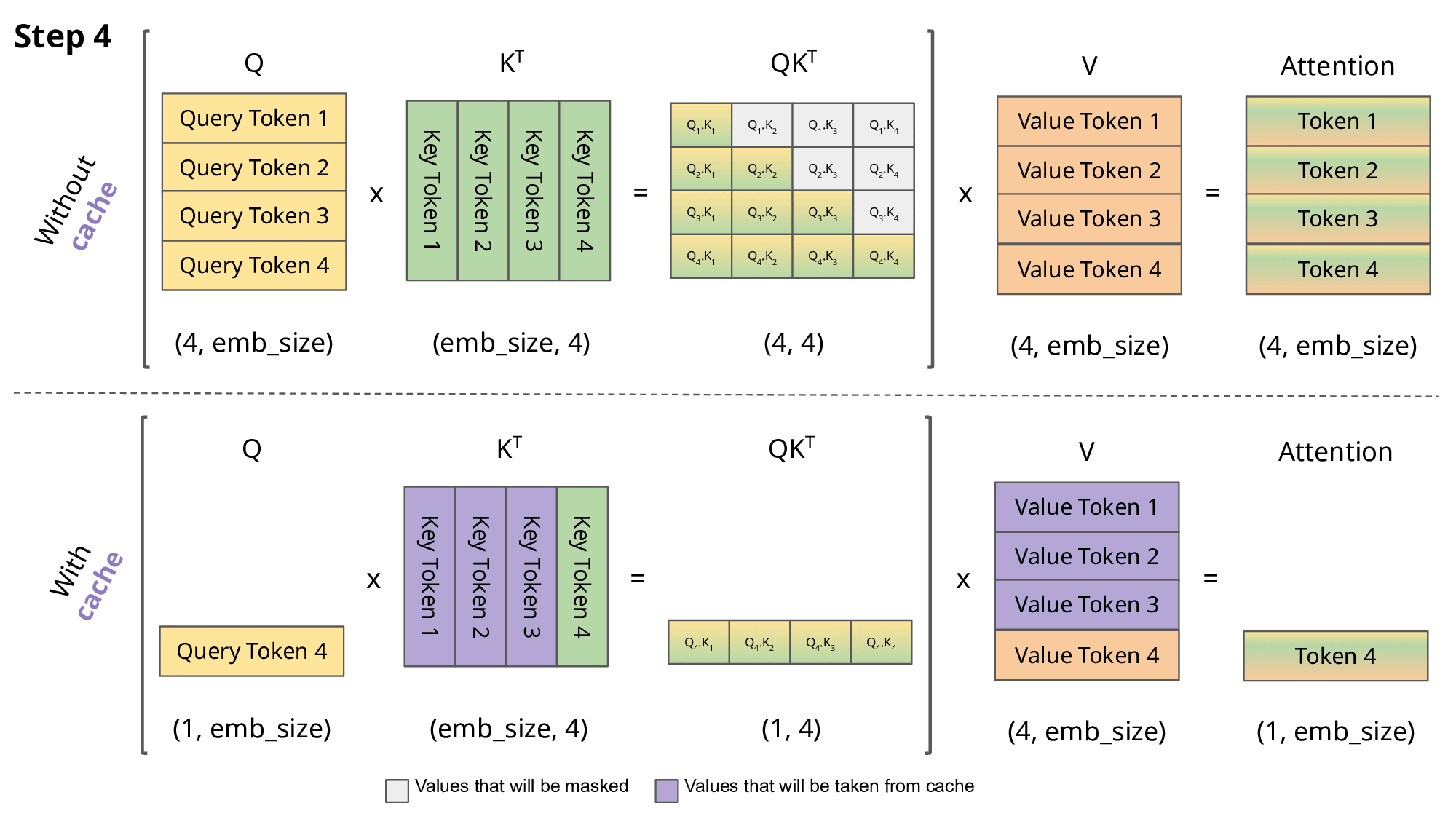
It is perfectly fine to solve exercises 1-3 in the Jupyter notebook and then copy-paste your code in the python file kv_cache.py.
The class CausalSelfAttention_kv inherits the same architecture as Karpathy's original, but its forward method must accept and return a KV cache.
Signature:
def forward(self, x, kv_cache=None) -> (y, kv_cache):The kv_cache is a list [k, v] where both tensors have shape (B, seq_l, C) — that is, they are stored before head splitting and transposition.
Here is Karpathy's original Block:
class Block(nn.Module):
""" an unassuming Transformer block """
def __init__(self, config):
super().__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = CausalSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = nn.ModuleDict(dict(
c_fc = nn.Linear(config.n_embd, 4 * config.n_embd),
c_proj = nn.Linear(4 * config.n_embd, config.n_embd),
act = NewGELU(),
dropout = nn.Dropout(config.resid_pdrop),
))
m = self.mlp
self.mlpf = lambda x: m.dropout(m.c_proj(m.act(m.c_fc(x)))) # MLP forward
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlpf(self.ln_2(x))
return xWhat to implement in Block_kv.forward(self, x, kv_cache=None):
Thread the kv_cache argument through self.attn, collect the returned updated cache, and return both the block output x and the new kv_cache.
The __init__ of GPT_kv has already been modified to use Block_kv instead of Block. You need to override forward and implement generate_kv.
Here is Karpathy's original GPT.forward and GPT.generate for reference:
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.block_size, f"Cannot forward sequence of length {t}, block size is only {self.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device).unsqueeze(0) # shape (1, t)
# forward the GPT model itself
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (1, t, n_embd)
x = self.transformer.drop(tok_emb + pos_emb)
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
logits = self.lm_head(x)
# if we are given some desired targets also calculate the loss
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
return logits, loss
@torch.no_grad()
def generate(self, idx, max_new_tokens, temperature=1.0, do_sample=False, top_k=None):
"""
Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and complete
the sequence max_new_tokens times, feeding the predictions back into the model each time.
Most likely you'll want to make sure to be in model.eval() mode of operation for this.
"""
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.block_size else idx[:, -self.block_size:]
# forward the model to get the logits for the index in the sequence
logits, _ = self(idx_cond)
# pluck the logits at the final step and scale by desired temperature
logits = logits[:, -1, :] / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, top_k)
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
# either sample from the distribution or take the most likely element
if do_sample:
idx_next = torch.multinomial(probs, num_samples=1)
else:
_, idx_next = torch.topk(probs, k=1, dim=-1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
return idxSignature:
def forward(self, idx, targets=None, kv_cache=None, compute_first=False):kv_cacheis a list of lengthn_layer, where each element is the[k, v]cache for that layer (orNoneif that layer has not yet been populated).compute_firstis a flag used on the first call when a prompt is provided: whenTrue, the fullidxis processed even if a cache exists, in order to populate the cache from scratch.
Adapt the original generate loop to use the KV cache for efficient generation:
We use the demo to check that our code runs correctly. Run the demo_sort.py file (nothing to change in this file) to train the model on the sorting task and verify that generate_kv produces the same sequences as the original generate, then benchmark the two approaches.
Run the provided benchmark.py script, which compares the per-step latency of the baseline (no KV cache) against your GPT_kv implementation across two model sizes and several context lengths.
python benchmark.pyThe script saves results to benchmark_results.txt. Your output must follow this exact format:
device: <cpu|cuda|mps>
gpt-mini (X.XM params)
Context T no KV (ms) KV (ms) speedup
--------------------------------------------------
64 X.XX X.XX X.XXx
128 X.XX X.XX X.XXx
256 X.XX X.XX X.XXx
512 X.XX X.XX X.XXx
1024 X.XX X.XX X.XXx
1536 X.XX X.XX X.XXx
gpt2 (X.XM params)
Context T no KV (ms) KV (ms) speedup
--------------------------------------------------
64 X.XX X.XX X.XXx
128 X.XX X.XX X.XXx
256 X.XX X.XX X.XXx
512 X.XX X.XX X.XXx
1024 X.XX X.XX X.XXx
1536 X.XX X.XX X.XXx
Each row measures one generation step at the given context length
-
no KV: baseline
GPT.forwardre-encodes all$T$ tokens (attention cost $O(T^2)$). -
KV:
GPT_kv.forwardre-encodes only the one new token, with the previous$T-1$ token representations served from the cache (attention cost $O(T)$). -
speedup: Ratio
no KV / KV.