The goal of this part is to adapt the code of minGPT from Karpathy to incorporate Low-Rank Adaptation (LoRA) for fine-tuning.
This blog post by Rajan Ghimire is a concise introduction to LoRA. The original paper is Hu et al., 2021.
It is perfectly fine to solve the exercises in the Jupyter notebook and then copy-paste your code in the python files lora.py and demo_sort_lora.py.
Standard fine-tuning updates all
where
At inference time the correction
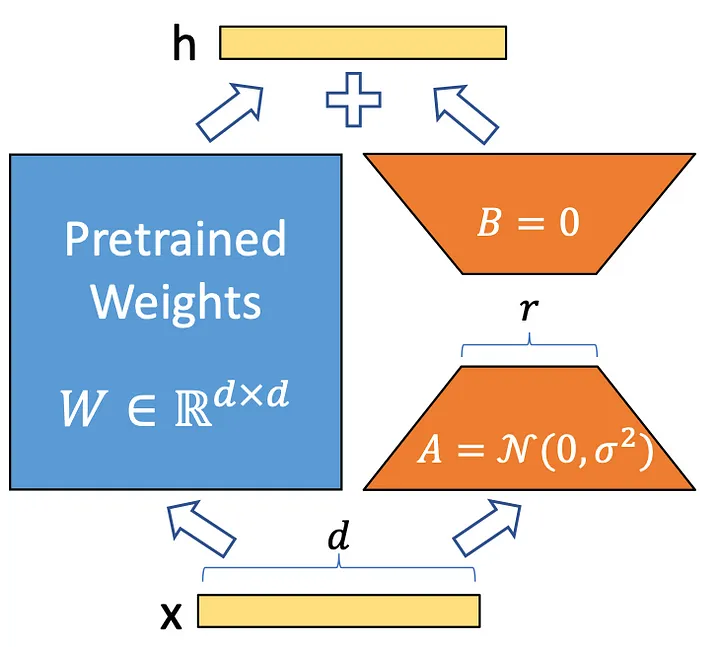
LoRALinear subclasses nn.Linear and adds the LoRA adapter. All four methods below must be completed in lora.py.
Initialise the LoRA matrices:
-
lora_A: Kaiming uniform witha=sqrt(5)(identical tonn.Linear's weight init). -
lora_B: zeros, so the adapter output is$0$ at the start of training.
Also call nn.Linear.reset_parameters(self) to reset the base weight and bias.
The standard linear pass x = Wx + b is computed by nn.Linear.forward. When weights have not been merged and lora_rank > 0, add the LoRA correction:
Use F.linear for both the has_weights_merged is True the correction is already baked into W, so nothing extra is needed.
When switching back to training mode (mode=True), de-merge if the weights were previously merged:
When switching to eval mode, merge the LoRA correction into W so that inference requires no extra computation:
Test: Call .eval() then .train() and verify the output is unchanged — merging then de-merging must be an exact round-trip.
Call super().__init__(config) (which builds the standard attention layer), then replace self.c_attn and self.c_proj with LoRALinear instances, passing lora_rank and lora_alpha from config:
self.c_attn = LoRALinear(
in_features=config.n_embd,
out_features=3 * config.n_embd,
lora_rank=config.lora_rank,
lora_alpha=config.lora_alpha,
)
self.c_proj = LoRALinear(
in_features=config.n_embd,
out_features=config.n_embd,
lora_rank=config.lora_rank,
lora_alpha=config.lora_alpha,
)Block_LoRA and GPT_LoRA.__init__ are already provided: they substitute Block_LoRA (which uses CausalSelfAttention_LoRA) wherever the base classes used Block.
When lora_rank > 0, skip the full decay/no-decay parameter grouping from the base GPT class and simply return a AdamW optimizer. Because get_lora_model has already frozen all non-LoRA parameters, only the LoRA matrices will receive gradient updates.
We use the sorting task from Karpathy's demo as a testbed in the demo_sort_lora.py file.
Train GPT_LoRA (with lora_rank=8, lora_alpha=32) on SortDataset(split='train', length=6) for 1000 iterations at learning rate 5e-4. Evaluate on both the train and test splits using greedy decoding and report accuracy (fraction of sequences sorted correctly).
Evaluate the pre-trained model — without any fine-tuning — on SortDataset(length=10). The model was trained on length-6 sequences, so performance on length-10 will be lower.
Call get_lora_model(model) to freeze the pre-trained weights and then fine-tune only the LoRA parameters on SortDataset(length=10) for 2000 iterations. Re-evaluate on both splits and report the recovered accuracy.