import tensorflow as tf
import numpy as np
x_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=np.float32)
y_data = np.array([[0], [1], [1], [0]], dtype=np.float32)
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
W = tf.Variable(tf.random_normal([2, 1]), name="weight")
b = tf.Variable(tf.random_normal([1]), name="bias")
hypothesis = tf.sigmoid(tf.matmul(X, W) + b)
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) * tf.log(1 - hypothesis))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(10001):
sess.run(train, feed_dict={X: x_data, Y: y_data})
if step % 100 == 0:
print(step, sess.run(cost, feed_dict={X: x_data, Y: y_data}), sess.run((W)))
h, c, a = sess.run([hypothesis, predicted, accuracy], feed_dict={X: x_data, Y: y_data})
print("\nHypothesis: ", h, "\nCorrect (Y): ", c, "\nAccuarcy: ", a)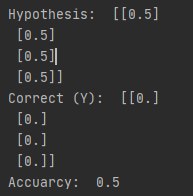
위와 같이 원하는 결과가 나오지 않게됨
import tensorflow as tf
import numpy as np
x_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=np.float32)
y_data = np.array([[0], [1], [1], [0]], dtype=np.float32)
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# layer를 하나더 쌓음
W1 = tf.Variable(tf.random_normal([2, 2]), name="weight1")
b1 = tf.Variable(tf.random_normal([2]), name="bias1")
layer1 = tf.sigmoid(tf.matmul(X, W1) + b1)
W2 = tf.Variable(tf.random_normal([2, 1]), name="weight2")
b2 = tf.Variable(tf.random_normal([1]), name="bias2")
# 10개의 출력(더 넓은 범위)
# W1 = tf.Variable(tf.random_normal([2, 10]), name="weight1")
# b1 = tf.Variable(tf.random_normal([10]), name="bias1")
# layer1 = tf.sigmoid(tf.matmul(X, W1) + b1)
# W2 = tf.Variable(tf.random_normal([10, 1]), name="weight2")
# b2 = tf.Variable(tf.random_normal([1]), name="bias2")
# hypothesis = tf.sigmoid(tf.matmul(layer1, W2) + b2)
# 4개의 layer
# W1 = tf.Variable(tf.random_normal([2, 10]), name="weight1")
# b1 = tf.Variable(tf.random_normal([10]), name="bias1")
# layer1 = tf.sigmoid(tf.matmul(X, W1) + b1)
# W2 = tf.Variable(tf.random_normal([10, 10]), name="weight2")
# b2 = tf.Variable(tf.random_normal([10]), name="bias2")
# layer2 = tf.sigmoid(tf.matmul(layer1, W2) + b2)
# W3 = tf.Variable(tf.random_normal([10, 10]), name="weight3")
# b3 = tf.Variable(tf.random_normal([10]), name="bias3")
# layer3 = tf.sigmoid(tf.matmul(layer2, W3) + b3)
# W4 = tf.Variable(tf.random_normal([10, 1]), name="weight4")
# b4 = tf.Variable(tf.random_normal([1]), name="bias4")
# hypothesis = tf.sigmoid(tf.matmul(layer3, W4) + b4)
hypothesis = tf.sigmoid(tf.matmul(layer1, W2) + b2)
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) * tf.log(1 - hypothesis))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(10001):
sess.run(train, feed_dict={X: x_data, Y: y_data})
if step % 100 == 0:
print(step, sess.run(cost, feed_dict={X: x_data, Y: y_data}), sess.run((W2)))
h, c, a = sess.run([hypothesis, predicted, accuracy], feed_dict={X: x_data, Y: y_data})
print("\nHypothesis: ", h, "\nCorrect (Y): ", c, "\nAccuarcy: ", a)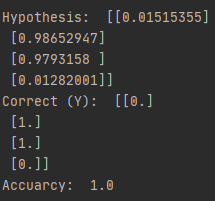
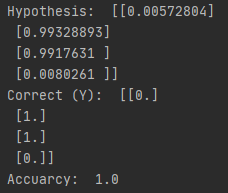
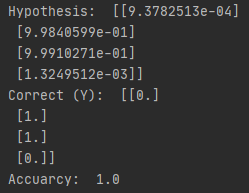
위의 결과들로 layer를 늘림으로써 모두 원하는 결과가 잘 나오는 것을 볼 수 있고 layer가 많거나 출력이 큰 경우에는 좀 더 학습이 잘되는 것을 볼 수 있음