From 3afa7bc7f1e4f8b903d5a52f4eab5b23cb4fcae3 Mon Sep 17 00:00:00 2001
From: Pasha0909 <73825639+Pasha0909@users.noreply.github.com>
Date: Wed, 22 Dec 2021 15:00:57 +0500
Subject: [PATCH 1/4] =?UTF-8?q?Create=20=D0=BE=D1=82=D1=87=D0=B5=D1=82.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
"\320\276\321\202\321\207\320\265\321\202.md" | 26 +++++++++++++++++++
1 file changed, 26 insertions(+)
create mode 100644 "\320\276\321\202\321\207\320\265\321\202.md"
diff --git "a/\320\276\321\202\321\207\320\265\321\202.md" "b/\320\276\321\202\321\207\320\265\321\202.md"
new file mode 100644
index 0000000..764b3fe
--- /dev/null
+++ "b/\320\276\321\202\321\207\320\265\321\202.md"
@@ -0,0 +1,26 @@
+# 1 Общее количество записей в датасете:
+
+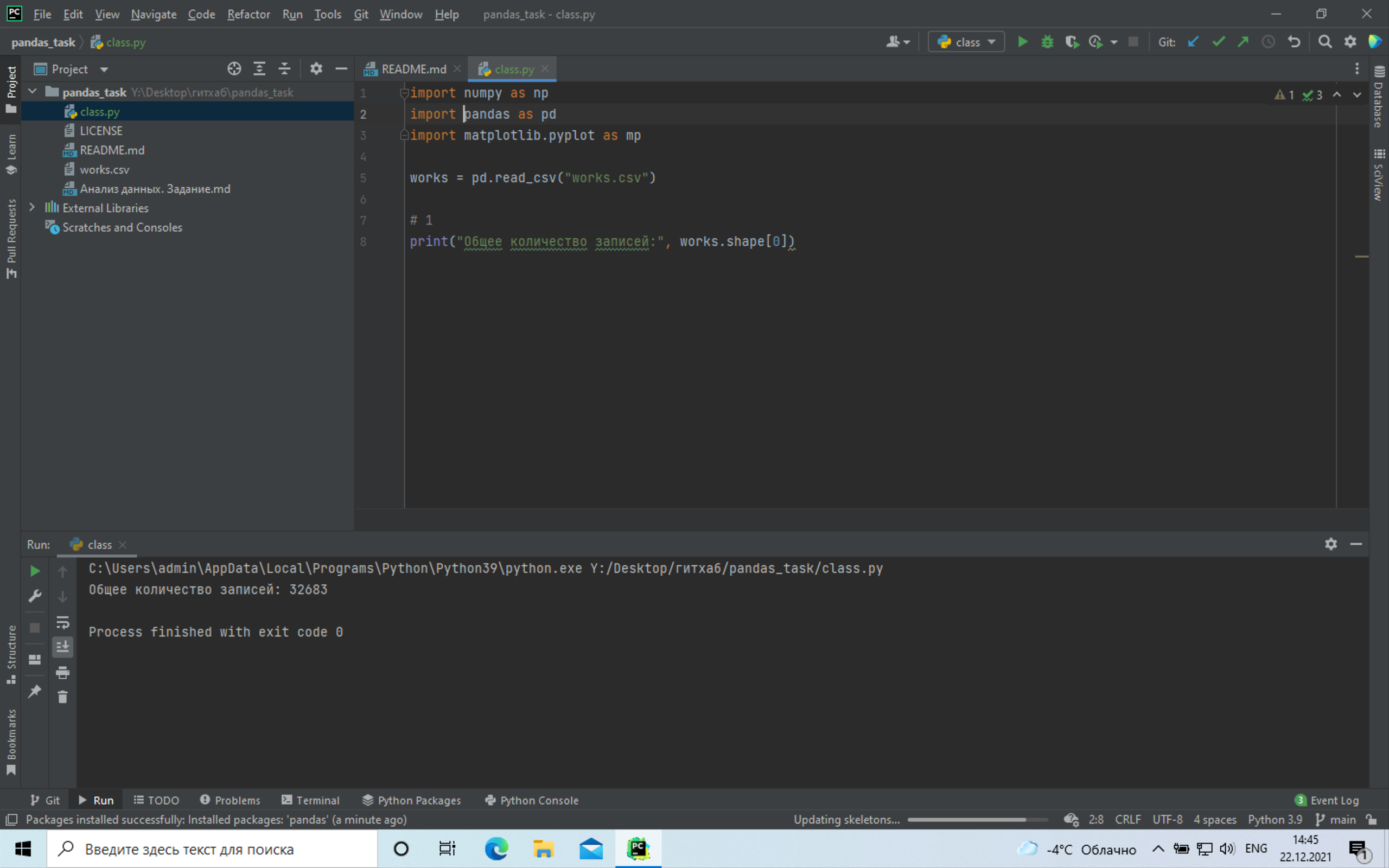 +
+# 2 Количество мужчин и женщин в датасете:
+
+
+
+# 2 Количество мужчин и женщин в датасете:
+
+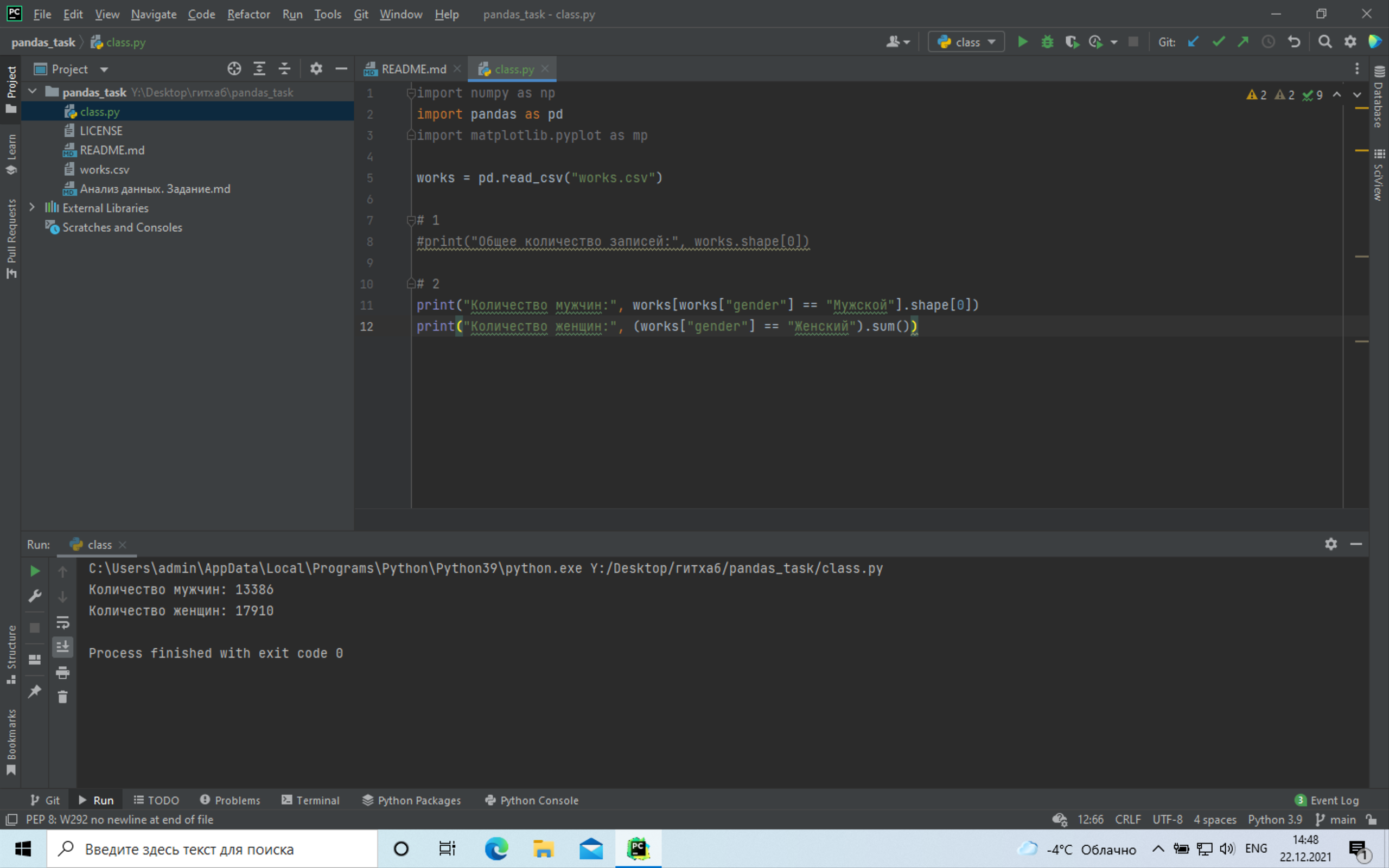 +
+# 3 Сколько значений в столбце skills не NAN:
+
+
+
+# 3 Сколько значений в столбце skills не NAN:
+
+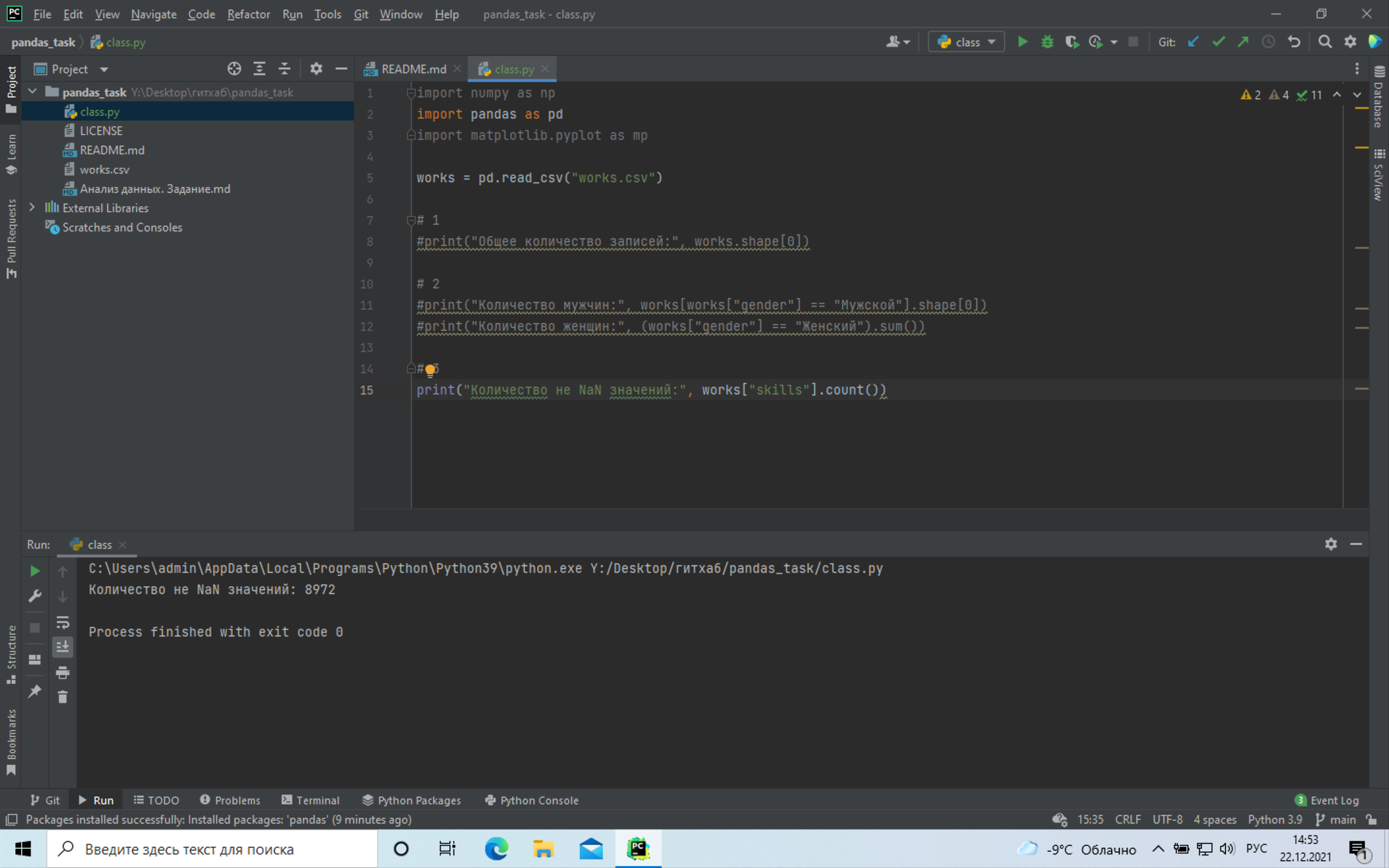 +
+# 4 Все заполненные скиллы:
+
+
+
+# 4 Все заполненные скиллы:
+
+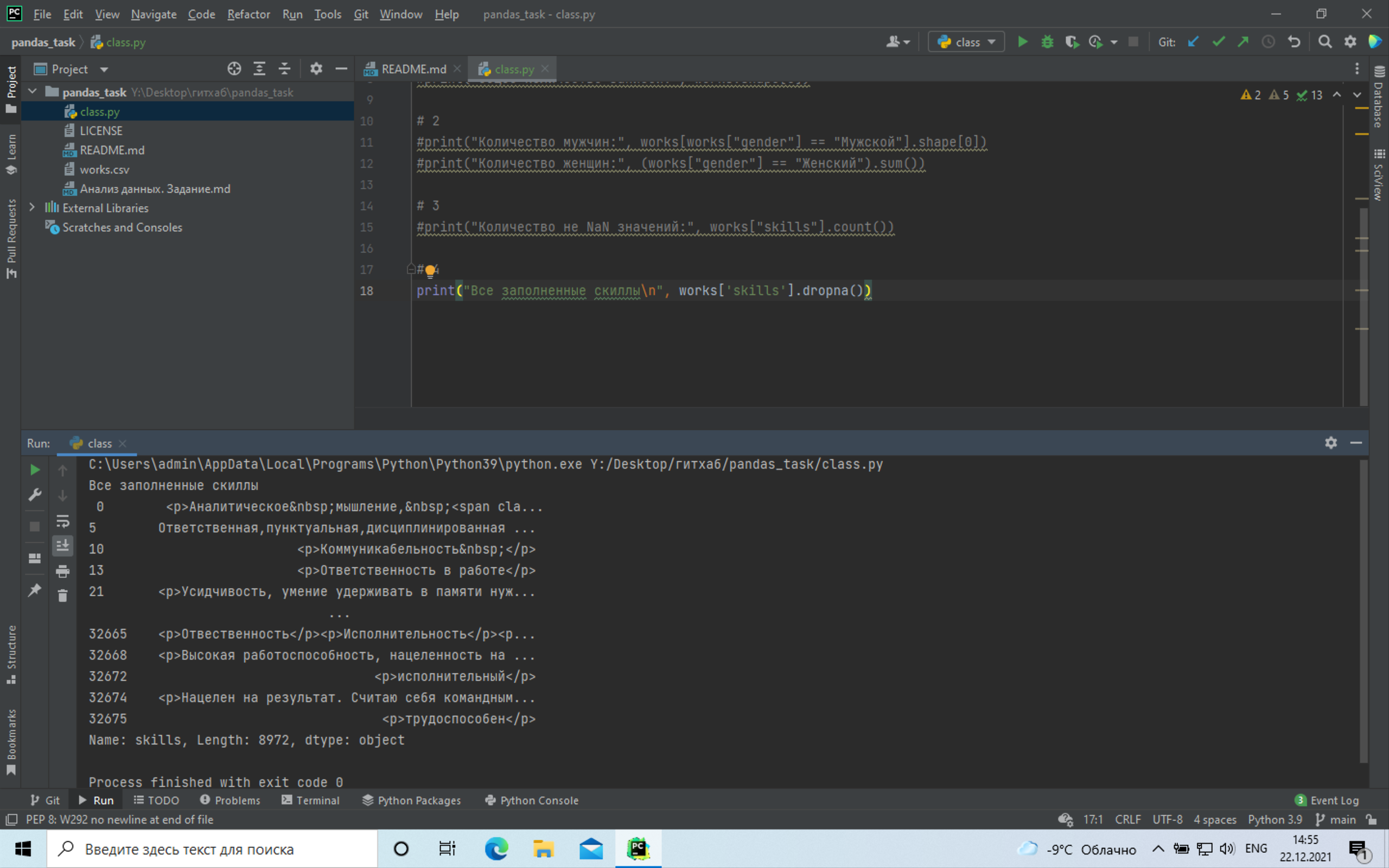 +
+# 5 Вывести зарплату только у тех, у которых в скиллах есть Python (Питон):
+
+
+
+# 5 Вывести зарплату только у тех, у которых в скиллах есть Python (Питон):
+
+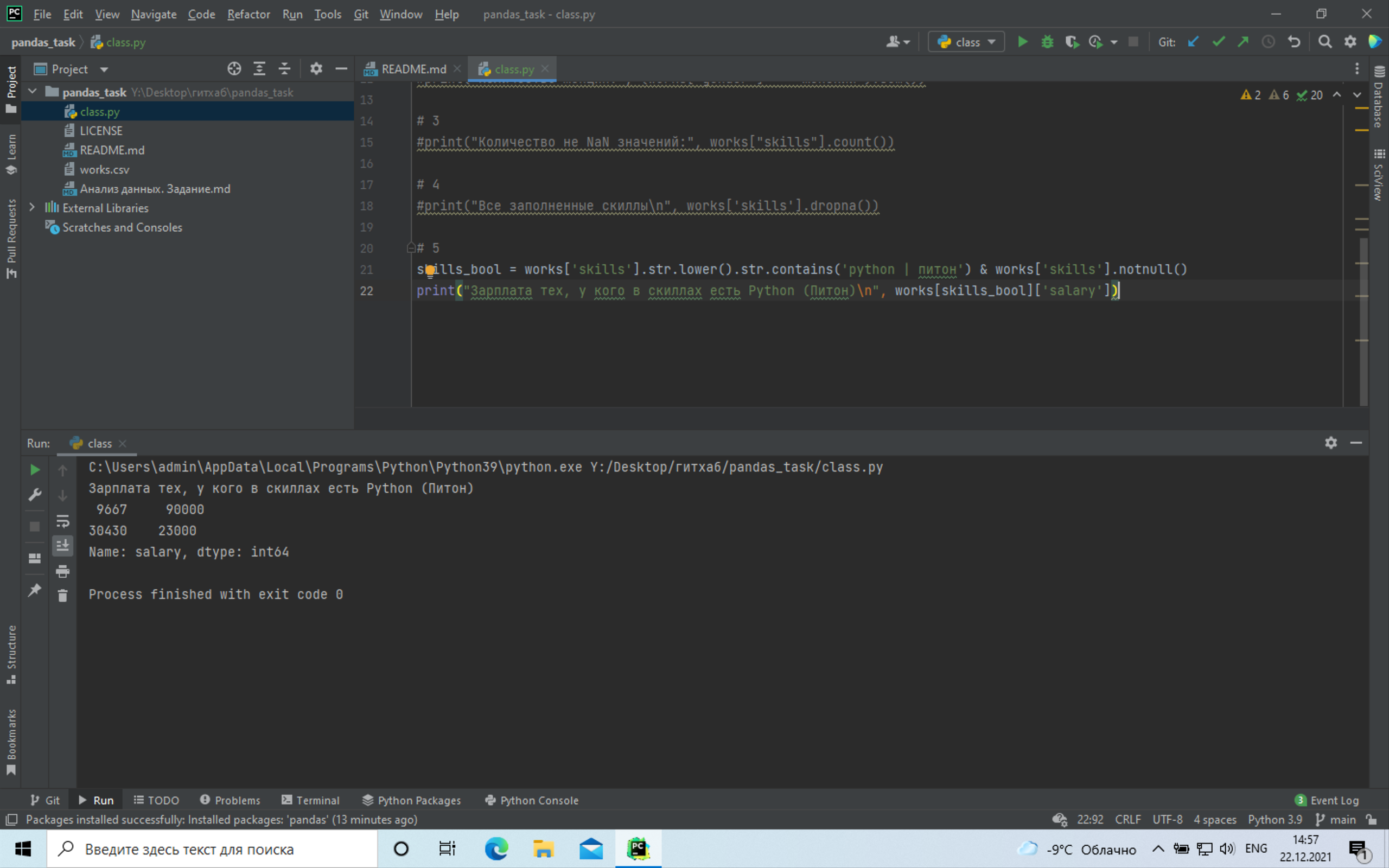 +
+# 6 Построить перцентили по заработной плате у мужчин и женщин:
+
+
+
+# 6 Построить перцентили по заработной плате у мужчин и женщин:
+
+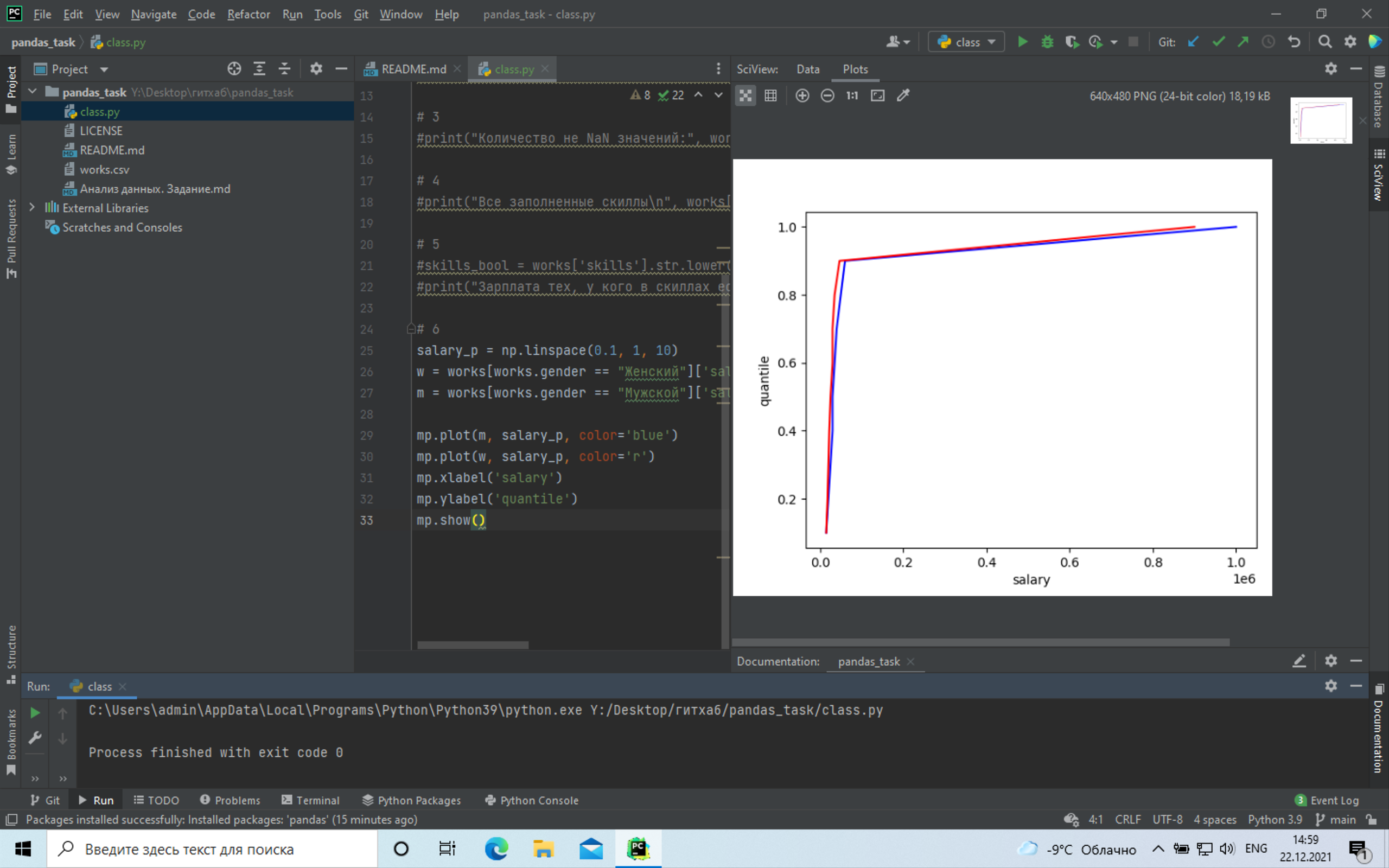 +
+# 7 Построить графики распределения по заработной плате мужчин и женщин в зависимости от высшего образования:
+
From b60e50a51d9874126a51de64eb2ca5519b6e9309 Mon Sep 17 00:00:00 2001
From: Pasha0909 <73825639+Pasha0909@users.noreply.github.com>
Date: Thu, 23 Dec 2021 20:49:40 +0500
Subject: [PATCH 2/4] =?UTF-8?q?Update=20and=20rename=20=D0=BE=D1=82=D1=87?=
=?UTF-8?q?=D0=B5=D1=82.md=20to=20=D0=BE=D1=82=D1=87=D0=B5=D1=82=5Fclass.m?=
=?UTF-8?q?d?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...02.md" => "\320\276\321\202\321\207\320\265\321\202_class.md" | 1 +
1 file changed, 1 insertion(+)
rename "\320\276\321\202\321\207\320\265\321\202.md" => "\320\276\321\202\321\207\320\265\321\202_class.md" (91%)
diff --git "a/\320\276\321\202\321\207\320\265\321\202.md" "b/\320\276\321\202\321\207\320\265\321\202_class.md"
similarity index 91%
rename from "\320\276\321\202\321\207\320\265\321\202.md"
rename to "\320\276\321\202\321\207\320\265\321\202_class.md"
index 764b3fe..d2cefa5 100644
--- "a/\320\276\321\202\321\207\320\265\321\202.md"
+++ "b/\320\276\321\202\321\207\320\265\321\202_class.md"
@@ -24,3 +24,4 @@
# 7 Построить графики распределения по заработной плате мужчин и женщин в зависимости от высшего образования:
+
+
+# 7 Построить графики распределения по заработной плате мужчин и женщин в зависимости от высшего образования:
+
From b60e50a51d9874126a51de64eb2ca5519b6e9309 Mon Sep 17 00:00:00 2001
From: Pasha0909 <73825639+Pasha0909@users.noreply.github.com>
Date: Thu, 23 Dec 2021 20:49:40 +0500
Subject: [PATCH 2/4] =?UTF-8?q?Update=20and=20rename=20=D0=BE=D1=82=D1=87?=
=?UTF-8?q?=D0=B5=D1=82.md=20to=20=D0=BE=D1=82=D1=87=D0=B5=D1=82=5Fclass.m?=
=?UTF-8?q?d?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...02.md" => "\320\276\321\202\321\207\320\265\321\202_class.md" | 1 +
1 file changed, 1 insertion(+)
rename "\320\276\321\202\321\207\320\265\321\202.md" => "\320\276\321\202\321\207\320\265\321\202_class.md" (91%)
diff --git "a/\320\276\321\202\321\207\320\265\321\202.md" "b/\320\276\321\202\321\207\320\265\321\202_class.md"
similarity index 91%
rename from "\320\276\321\202\321\207\320\265\321\202.md"
rename to "\320\276\321\202\321\207\320\265\321\202_class.md"
index 764b3fe..d2cefa5 100644
--- "a/\320\276\321\202\321\207\320\265\321\202.md"
+++ "b/\320\276\321\202\321\207\320\265\321\202_class.md"
@@ -24,3 +24,4 @@
# 7 Построить графики распределения по заработной плате мужчин и женщин в зависимости от высшего образования:
+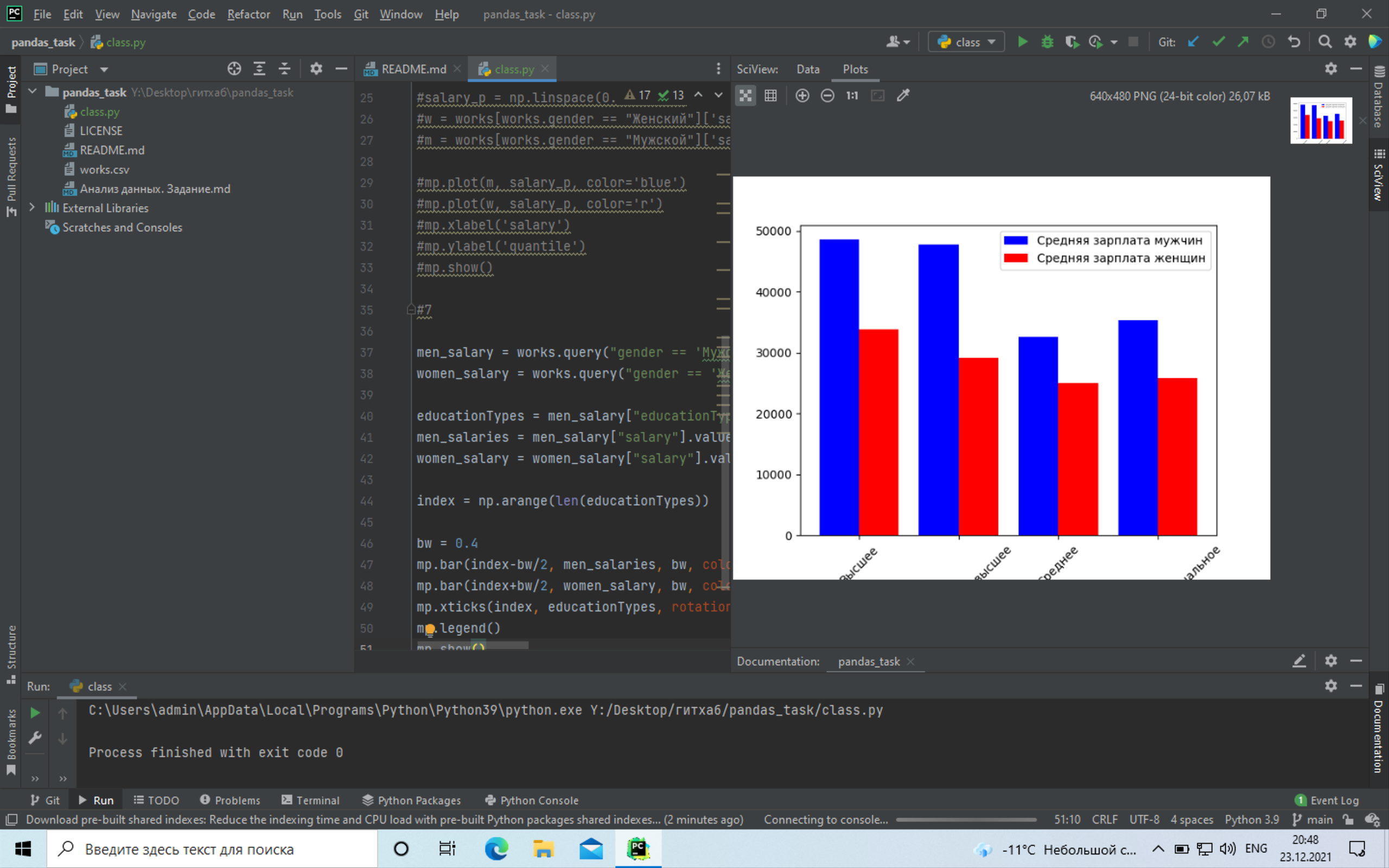 From e3fdf62f652af5b06a8379263672de02af2f6aa7 Mon Sep 17 00:00:00 2001
From: Pasha0909 <73825639+Pasha0909@users.noreply.github.com>
Date: Thu, 23 Dec 2021 20:59:37 +0500
Subject: [PATCH 3/4] class task
---
class.py | 51 +++++++++++++++++++++++++++++++++++++++++++++++++++
1 file changed, 51 insertions(+)
create mode 100644 class.py
diff --git a/class.py b/class.py
new file mode 100644
index 0000000..1479c92
--- /dev/null
+++ b/class.py
@@ -0,0 +1,51 @@
+import numpy as np
+import pandas as pd
+import matplotlib.pyplot as mp
+
+works = pd.read_csv("works.csv")
+
+# 1
+#print("Общее количество записей:", works.shape[0])
+
+# 2
+#print("Количество мужчин:", works[works["gender"] == "Мужской"].shape[0])
+#print("Количество женщин:", (works["gender"] == "Женский").sum())
+
+# 3
+#print("Количество не NaN значений:", works["skills"].count())
+
+# 4
+#print("Все заполненные скиллы\n", works['skills'].dropna())
+
+# 5
+#skills_bool = works['skills'].str.lower().str.contains('python | питон') & works['skills'].notnull()
+#print("Зарплата тех, у кого в скиллах есть Python (Питон)\n", works[skills_bool]['salary'])
+
+# 6
+#salary_p = np.linspace(0.1, 1, 10)
+#w = works[works.gender == "Женский"]['salary'].quantile(salary_p)
+#m = works[works.gender == "Мужской"]['salary'].quantile(salary_p)
+
+#mp.plot(m, salary_p, color='blue')
+#mp.plot(w, salary_p, color='r')
+#mp.xlabel('salary')
+#mp.ylabel('quantile')
+#mp.show()
+
+#7
+
+men_salary = works.query("gender == 'Мужской'").groupby("educationType").agg("mean").reset_index()
+women_salary = works.query("gender == 'Женский'").groupby("educationType").agg("mean").reset_index()
+
+educationTypes = men_salary["educationType"].values
+men_salaries = men_salary["salary"].values
+women_salary = women_salary["salary"].values
+
+index = np.arange(len(educationTypes))
+
+bw = 0.4
+mp.bar(index-bw/2, men_salaries, bw, color="b", label="Средняя зарплата мужчин")
+mp.bar(index+bw/2, women_salary, bw, color="r", label="Средняя зарплата женщин")
+mp.xticks(index, educationTypes, rotation=45)
+mp.legend()
+mp.show()
\ No newline at end of file
From 7bcd6b59efc64bfd541a685aa12da17ccd0d455d Mon Sep 17 00:00:00 2001
From: Pasha0909 <73825639+Pasha0909@users.noreply.github.com>
Date: Thu, 23 Dec 2021 21:00:13 +0500
Subject: [PATCH 4/4] HomeWork
---
HW-8.py | 35 +++++++++++++++++++++++++++++++++++
homework8.txt | 17 +++++++++++++++++
2 files changed, 52 insertions(+)
create mode 100644 HW-8.py
create mode 100644 homework8.txt
diff --git a/HW-8.py b/HW-8.py
new file mode 100644
index 0000000..906c033
--- /dev/null
+++ b/HW-8.py
@@ -0,0 +1,35 @@
+#8
+import pandas as pd
+
+def non_matches(firs_param, second_param, data):
+ count = 0
+ for (f1, f2) in zip(data[firs_param], data[second_param]):
+ if not is_contains(f1, f2) and not is_contains(f2, f1):
+ count += 1
+ return count
+
+def is_contains(first_field, second_field):
+ for word in first_field.lower().replace('-', ' ').split():
+ if word in second_field.lower():
+ return True
+ return False
+
+def get_top(size, data, search_field, return_field, word_to_search):
+ return data[data[search_field].str.lower().str.contains(word_to_search[:-2])][return_field]\
+ .str\
+ .lower()\
+ .value_counts()\
+ .head(size)
+
+works = pd.read_csv("works.csv").dropna()
+not_matches_count = non_matches("jobTitle", "qualification", works)
+managers = get_top(5, works, "jobTitle", "qualification", "менеджер")
+engineers = get_top(5, works, "qualification", "jobTitle", "инженер")
+output_string = f"Всего записей {works.shape[0]} из них не совпадают {not_matches_count}\n\n" \
+ f"Топ - 5 образовний менеджеров\n" \
+ f"{managers}\n\n" \
+ f"Топ - 5 должностей инженеров\n" \
+ f"{engineers}"
+
+with open('homework8.txt', 'w', encoding='utf-8') as file:
+ file.write(output_string)
\ No newline at end of file
diff --git a/homework8.txt b/homework8.txt
new file mode 100644
index 0000000..cab673c
--- /dev/null
+++ b/homework8.txt
@@ -0,0 +1,17 @@
+Всего записей 1068 из них не совпадают 793
+
+Топ - 5 образовний менеджеров
+бакалавр 11
+менеджер 10
+специалист 6
+экономист 6
+экономист-менеджер 4
+Name: qualification, dtype: int64
+
+Топ - 5 должностей инженеров
+заместитель директора 3
+главный инженер 3
+ведущий инженер-конструктор 2
+инженер лесопользования 2
+директор 2
+Name: jobTitle, dtype: int64
\ No newline at end of file
From e3fdf62f652af5b06a8379263672de02af2f6aa7 Mon Sep 17 00:00:00 2001
From: Pasha0909 <73825639+Pasha0909@users.noreply.github.com>
Date: Thu, 23 Dec 2021 20:59:37 +0500
Subject: [PATCH 3/4] class task
---
class.py | 51 +++++++++++++++++++++++++++++++++++++++++++++++++++
1 file changed, 51 insertions(+)
create mode 100644 class.py
diff --git a/class.py b/class.py
new file mode 100644
index 0000000..1479c92
--- /dev/null
+++ b/class.py
@@ -0,0 +1,51 @@
+import numpy as np
+import pandas as pd
+import matplotlib.pyplot as mp
+
+works = pd.read_csv("works.csv")
+
+# 1
+#print("Общее количество записей:", works.shape[0])
+
+# 2
+#print("Количество мужчин:", works[works["gender"] == "Мужской"].shape[0])
+#print("Количество женщин:", (works["gender"] == "Женский").sum())
+
+# 3
+#print("Количество не NaN значений:", works["skills"].count())
+
+# 4
+#print("Все заполненные скиллы\n", works['skills'].dropna())
+
+# 5
+#skills_bool = works['skills'].str.lower().str.contains('python | питон') & works['skills'].notnull()
+#print("Зарплата тех, у кого в скиллах есть Python (Питон)\n", works[skills_bool]['salary'])
+
+# 6
+#salary_p = np.linspace(0.1, 1, 10)
+#w = works[works.gender == "Женский"]['salary'].quantile(salary_p)
+#m = works[works.gender == "Мужской"]['salary'].quantile(salary_p)
+
+#mp.plot(m, salary_p, color='blue')
+#mp.plot(w, salary_p, color='r')
+#mp.xlabel('salary')
+#mp.ylabel('quantile')
+#mp.show()
+
+#7
+
+men_salary = works.query("gender == 'Мужской'").groupby("educationType").agg("mean").reset_index()
+women_salary = works.query("gender == 'Женский'").groupby("educationType").agg("mean").reset_index()
+
+educationTypes = men_salary["educationType"].values
+men_salaries = men_salary["salary"].values
+women_salary = women_salary["salary"].values
+
+index = np.arange(len(educationTypes))
+
+bw = 0.4
+mp.bar(index-bw/2, men_salaries, bw, color="b", label="Средняя зарплата мужчин")
+mp.bar(index+bw/2, women_salary, bw, color="r", label="Средняя зарплата женщин")
+mp.xticks(index, educationTypes, rotation=45)
+mp.legend()
+mp.show()
\ No newline at end of file
From 7bcd6b59efc64bfd541a685aa12da17ccd0d455d Mon Sep 17 00:00:00 2001
From: Pasha0909 <73825639+Pasha0909@users.noreply.github.com>
Date: Thu, 23 Dec 2021 21:00:13 +0500
Subject: [PATCH 4/4] HomeWork
---
HW-8.py | 35 +++++++++++++++++++++++++++++++++++
homework8.txt | 17 +++++++++++++++++
2 files changed, 52 insertions(+)
create mode 100644 HW-8.py
create mode 100644 homework8.txt
diff --git a/HW-8.py b/HW-8.py
new file mode 100644
index 0000000..906c033
--- /dev/null
+++ b/HW-8.py
@@ -0,0 +1,35 @@
+#8
+import pandas as pd
+
+def non_matches(firs_param, second_param, data):
+ count = 0
+ for (f1, f2) in zip(data[firs_param], data[second_param]):
+ if not is_contains(f1, f2) and not is_contains(f2, f1):
+ count += 1
+ return count
+
+def is_contains(first_field, second_field):
+ for word in first_field.lower().replace('-', ' ').split():
+ if word in second_field.lower():
+ return True
+ return False
+
+def get_top(size, data, search_field, return_field, word_to_search):
+ return data[data[search_field].str.lower().str.contains(word_to_search[:-2])][return_field]\
+ .str\
+ .lower()\
+ .value_counts()\
+ .head(size)
+
+works = pd.read_csv("works.csv").dropna()
+not_matches_count = non_matches("jobTitle", "qualification", works)
+managers = get_top(5, works, "jobTitle", "qualification", "менеджер")
+engineers = get_top(5, works, "qualification", "jobTitle", "инженер")
+output_string = f"Всего записей {works.shape[0]} из них не совпадают {not_matches_count}\n\n" \
+ f"Топ - 5 образовний менеджеров\n" \
+ f"{managers}\n\n" \
+ f"Топ - 5 должностей инженеров\n" \
+ f"{engineers}"
+
+with open('homework8.txt', 'w', encoding='utf-8') as file:
+ file.write(output_string)
\ No newline at end of file
diff --git a/homework8.txt b/homework8.txt
new file mode 100644
index 0000000..cab673c
--- /dev/null
+++ b/homework8.txt
@@ -0,0 +1,17 @@
+Всего записей 1068 из них не совпадают 793
+
+Топ - 5 образовний менеджеров
+бакалавр 11
+менеджер 10
+специалист 6
+экономист 6
+экономист-менеджер 4
+Name: qualification, dtype: int64
+
+Топ - 5 должностей инженеров
+заместитель директора 3
+главный инженер 3
+ведущий инженер-конструктор 2
+инженер лесопользования 2
+директор 2
+Name: jobTitle, dtype: int64
\ No newline at end of file