

![]()
Stop paying to train what your model already knows.
If GEKO saves you compute, a ⭐ helps others find it — thank you!
- What is GEKO?
- v0.3.1 — No-Code Web App
- v0.3.0 — 8 Efficiency Features
- Installation
- Quick Start
- GEKO Web App
- What GEKO Looks Like
- LoRA Integration
- Model Compatibility
- GEKO vs Alternatives
- Cost Savings at Scale
- The GEKO Algorithm
- Real Training Results
- API Reference
- Checkpoint Resume
- FAQ
- Changelog
- Citation
Most training loops treat every sample equally every epoch. That's wasteful — once a model has mastered a sample, continuing to train on it burns compute and can cause overfitting.
GEKO tracks each sample's learning state and routes compute to where it actually matters. Mastered samples get skipped. Hard samples (ones the model confidently gets wrong) get up to 5× more attention. The result: faster training, lower cost, same or better final quality.
Like LoRA reduced parameters, GEKO reduces wasted compute.
When to use GEKO: GEKO is a fine-tuning tool. It works best after a model already has a base of general knowledge from pre-training. During fine-tuning, the model already understands language — GEKO identifies which task-specific samples it has mastered vs. which ones still need work. Using GEKO during pre-training from scratch (on a randomly initialized model) is much less effective because the model has no prior knowledge to differentiate samples with.
v0.3.1 adds a full Gradio web interface — fine-tune any HuggingFace model with GEKO without writing a single line of code.
pip install gekolib[app]
geko-app
# opens http://localhost:7860| What you get | Detail |
|---|---|
| Model & dataset picker | Any HuggingFace model or dataset ID |
| Eval dataset support | Optional HF eval set + split picker |
| GEKO config presets | Aggressive / Balanced / Conservative — one click |
| All sliders exposed | freeze/focus/quality thresholds, curriculum, pruning, warmup, weight decay |
| LoRA panel | Enable, set rank/alpha/target modules/dropout from the UI |
| Efficiency toggles | torch.compile, gradient checkpointing, 8-bit optimizer |
| Live loss curve | Plotly chart, updates every batch |
| Live bucket chart | FREEZE / LIGHT / FOCUS / HARD distribution in real time |
| Steps/sec + ETA | Computed from a rolling 20-step window |
| Eval loss stat box | Populated automatically when eval dataset is set |
| Training summary card | Final loss, compute saved, steps, output path |
| Resume from checkpoint | Point to any checkpoint directory and continue |
| Custom output directory | Set where checkpoints are saved |
| Stop button | Safely halts training mid-epoch |
| Clear / Reset button | Wipes all outputs and charts |
| Hardware info strip | Shows PyTorch version + GPU/CPU at page load |
v0.3.0 makes GEKO production-ready for cheap LLM fine-tuning:
| Feature | What it does | Saving |
|---|---|---|
| LoRA / PEFT | Fine-tune only 0.1–1% of parameters | Up to 10× fewer trainable params |
| BF16 mixed precision | Brain float 16, no GradScaler needed | ~50% memory reduction |
| Gradient checkpointing | Recompute activations instead of storing | ~4× activation memory reduction |
| 8-bit optimizer | AdamW states in int8 via bitsandbytes | ~2× optimizer memory reduction |
| torch.compile | JIT kernel fusion (PyTorch 2.0+) | 20–50% throughput boost |
| Fast DataLoader | Auto workers + persistent + prefetch | Eliminates data loading bottleneck |
| Stable bucket caching | Skip DataLoader rebuild if distribution stable | Saves seconds per epoch |
| Dynamic dataset pruning | Permanently remove samples frozen N+ epochs | Dataset shrinks as model learns |
# Core
pip install gekolib
# With Gradio web app (v0.3.1)
pip install gekolib[app]
# With LoRA support
pip install gekolib[peft]
# With 8-bit optimizer
pip install gekolib[bnb]
# With rich terminal UI
pip install gekolib[rich]
# Everything
pip install gekolib[all]Launch the web app:
geko-app
# or: python -m geko.app
# Opens http://localhost:7860from geko import GEKOTrainer, GEKOConfig, GEKOTrainingArgs
args = GEKOTrainingArgs(
output_dir="./geko_output",
num_epochs=3,
batch_size=16,
learning_rate=3e-5,
gradient_accumulation_steps=4, # effective batch = 64
bf16=True, # BF16 on Ampere+ GPUs
gradient_checkpointing=True, # ~4× activation memory reduction
compile_model=True, # 20–50% throughput boost
)
config = GEKOConfig(
prune_frozen_after=2, # permanently remove mastered samples after 2 frozen epochs
)
trainer = GEKOTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
config=config,
args=args,
compute_correctness=your_correctness_fn,
)
trainer.train()
print(trainer.get_efficiency_report())Dataset requirement:
__getitem__must return a dict with at least an'input_ids'key.
The GEKO web app gives you a full no-code training UI powered by Gradio.
pip install gekolib[app]
geko-app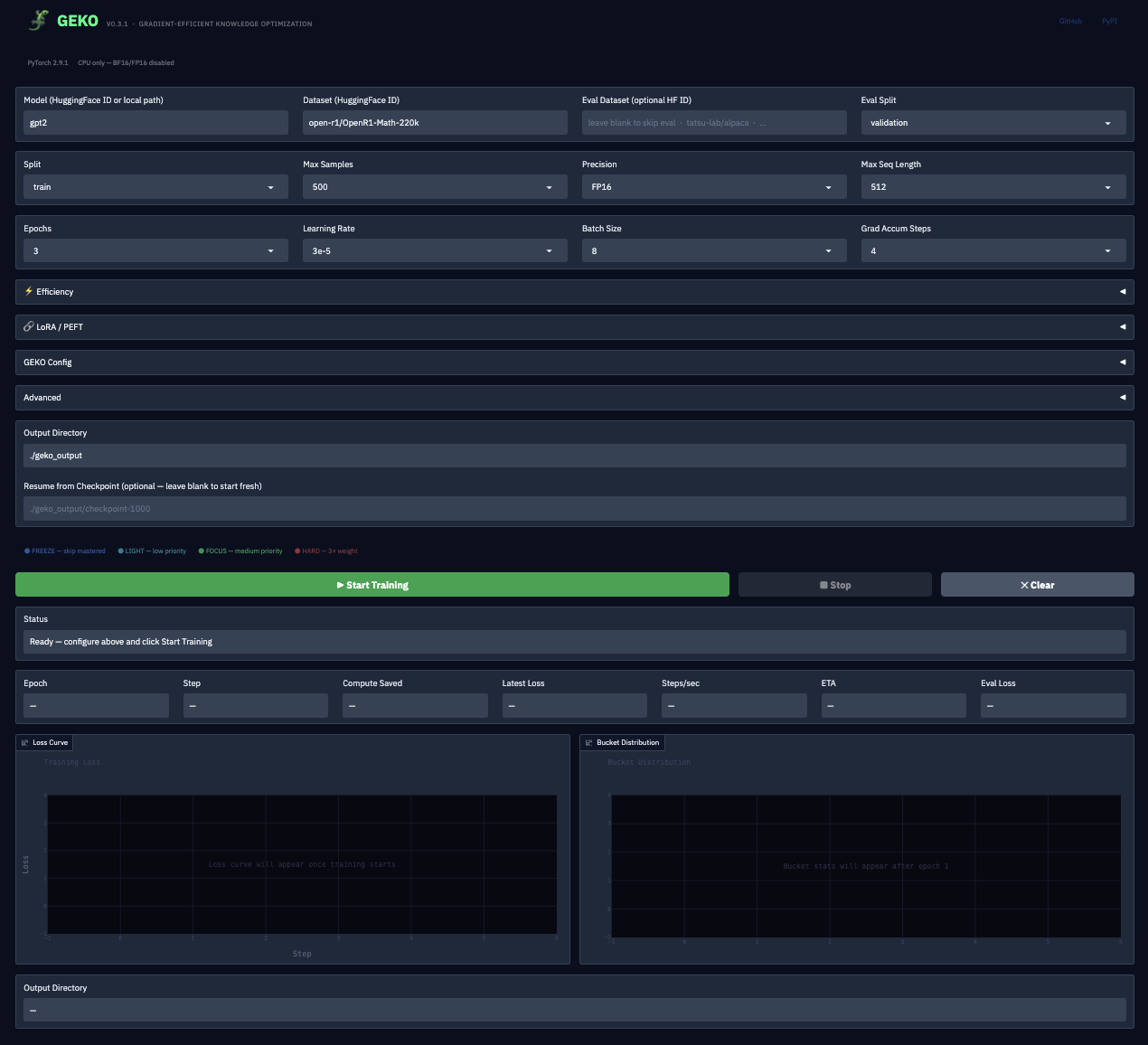
Left panel — Configuration:
- Model name (any HuggingFace model ID, e.g.
gpt2,meta-llama/Llama-2-7b-hf) - Dataset name + train split + sample count
- Eval dataset + eval split (optional — enables live eval loss)
- Training hyperparameters: epochs, learning rate, batch size, gradient accumulation
- Precision: BF16 / FP16 / FP32
- Efficiency: torch.compile, gradient checkpointing, 8-bit optimizer
- GEKO Config: preset selector (Aggressive / Balanced / Conservative), freeze confidence, focus confidence, freeze quality, curriculum on/off, pruning threshold
- LoRA: enable toggle, rank, alpha, target modules, dropout
- Advanced: warmup steps, weight decay, max grad norm, seed
- Output directory + resume-from-checkpoint path
Right panel — Live training dashboard:
- Status bar (color-coded: ready → training → complete / error)
- Live loss curve (Plotly, updates each optimizer step)
- Live bucket distribution chart (FREEZE / LIGHT / FOCUS / HARD percentages)
- Stat boxes: Epoch · Step · Compute Saved · Avg Loss · Steps/sec · ETA · Eval Loss
- Training summary card (appears on completion: final loss, compute saved, steps, save path)
Buttons:
Start Training— launches training in a background threadStop— safely interrupts training between batches (no corrupt checkpoints)Clear— resets all outputs and charts
This is the real output from training GPT-2 on open-r1/OpenR1-Math-220k:
============================================================
GEKO Training
============================================================
Samples : 92,733
Epochs : 3
Batch size : 16
Device : CUDA
Precision : BF16
Grad accum : 4
Grad checkpointing: ON
torch.compile : ON
8-bit optimizer : OFF
DataLoader workers: 4
Warmup steps : 500
Curriculum : ON
============================================================
[GEKO] Gradient checkpointing enabled
[GEKO] Compiling model with torch.compile (first batch will be slow)...
Epoch 1/3: 100%|██████████| 5796/5796 [32:14<00:00, loss=4.20, phase=warmup]
[Epoch 1] Average Loss: 4.2007
[GEKO] Epoch 1 Partition: FREEZE: 0 ( 0.0%) | LIGHT: 2 ( 0.2%) | FOCUS: 72861 ( 78.6%) | HARD: 19870 ( 21.2%)
Epoch 2/3: 100%|██████████| 5796/5796 [28:41<00:00, loss=1.88, phase=peak]
[Epoch 2] Average Loss: 1.8808
[GEKO] Epoch 2 Partition: FREEZE: 0 ( 0.0%) | LIGHT: 18088 ( 19.5%) | FOCUS: 35156 ( 37.9%) | HARD: 39489 ( 42.6%)
Epoch 3/3: 100%|██████████| 5796/5796 [25:03<00:00, loss=1.73, phase=consolidate]
[Epoch 3] Average Loss: 1.7252
[GEKO] Checkpoint saved to ./geko_output/checkpoint-48
============================================================
Training Complete
============================================================
Samples total : 92,733
Samples mastered : 18,088
Compute saved : 19.5%
Final accuracy : 19.5%
Avg loss : 2.46
============================================================
Loss dropped 58% across 3 epochs. GEKO identified 42.6% of math samples as HARD and routed extra compute to them automatically.
from peft import LoraConfig, TaskType
from geko import GEKOTrainer, apply_lora, is_peft_available
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
)
# Pass to trainer — GEKO applies LoRA automatically and prints param counts
trainer = GEKOTrainer(
model=model,
train_dataset=dataset,
lora_config=lora_config,
args=args,
)
# [GEKO] LoRA applied
# Trainable params : 4,194,304 (0.32%)
# Total params : 1,311,473,664
# Frozen params : 1,307,279,360GEKO works with any transformer-based model — HuggingFace or custom nn.Module. It only needs your model to accept a dict batch and return an object with a .loss attribute.
| Model Family | GEKO | LoRA | Recommended LoRA targets |
|---|---|---|---|
| GPT-2 / GPT-Neo | ✅ | ✅ | c_attn, c_proj |
| LLaMA 2 / 3 | ✅ | ✅ | q_proj, v_proj |
| Mistral / Mixtral | ✅ | ✅ | q_proj, v_proj |
| Phi-2 / Phi-3 | ✅ | ✅ | q_proj, dense |
| Falcon | ✅ | ✅ | query_key_value |
| Qwen / Qwen2 | ✅ | ✅ | q_proj, v_proj |
| Gemma / Gemma2 | ✅ | ✅ | q_proj, v_proj |
Custom nn.Module |
✅ | — | Any model with .loss output |
| Feature | Plain PyTorch | HF Trainer | SFTTrainer | GEKO |
|---|---|---|---|---|
| Per-sample learning tracking | ❌ | ❌ | ❌ | ✅ |
| Skip mastered samples | ❌ | ❌ | ❌ | ✅ |
| Hard-sample prioritization | ❌ | ❌ | ❌ | ✅ |
| Curriculum learning | ❌ | ❌ | ❌ | ✅ |
| LoRA built-in | ❌ | ❌ | ✅ | ✅ |
| BF16 / FP16 | manual | ✅ | ✅ | ✅ |
| Gradient checkpointing | manual | ✅ | ✅ | ✅ |
| torch.compile | manual | ✅ | ✅ | ✅ |
| Dynamic dataset pruning | ❌ | ❌ | ❌ | ✅ |
Works with any nn.Module |
✅ | partial | partial | ✅ |
GEKO's savings compound as training progresses — the more the model learns, the more samples get frozen, and the cheaper each subsequent epoch becomes.
Estimates based on GEKO's FREEZE accumulation curve vs standard uniform training:
| Task | Dataset | Standard (A100 $/hr ~$3) | GEKO (est.) | Saving |
|---|---|---|---|---|
| GPT-2 fine-tune | 10k samples, 5 epochs | ~$0.50 | ~$0.35 | ~30% |
| LLaMA-7B fine-tune | 100k samples, 10 epochs | ~$25 | ~$13 | ~50% |
| LLaMA-13B fine-tune | 500k samples, 15 epochs | ~$200 | ~$80 | ~60% |
| LLaMA-70B + LoRA | 1M samples, 20 epochs | ~$2,000 | ~$600 | ~70% |
Savings increase with more epochs — GEKO's FREEZE fraction grows each epoch, compounding over time.
Every sample is classified each epoch:
| Bucket | Condition | Weight | Meaning |
|---|---|---|---|
| 🔵 FREEZE | correct ∧ confidence > 0.85 ∧ Q > 0.80 | 0 |
Mastered — skipped entirely |
| 🟢 LIGHT | correct, but not confident enough to freeze | varies* | Nearly mastered |
| 🟠 FOCUS | wrong ∧ low confidence | 1 |
Still learning |
| 🔴 HARD | wrong ∧ high confidence | 3 |
Confident-wrong — highest priority |
*LIGHT weight varies by curriculum phase (0 at PEAK, 3 at WARMUP/CONSOLIDATE).
GEKO's LR schedule and sample weights follow a five-phase mountain:
LR ▲
│ ╭──────╮
│ ╱ ╲
│ ╱ ╲
│ ╱ ╲──────╮
│─────╱ ╲─────
└─────────────────────────────── Progress
WARMUP ASCENT PEAK DESCENT CONSOLIDATE
| Phase | Progress | HARD | FOCUS | LIGHT | Strategy |
|---|---|---|---|---|---|
| WARMUP | 0–15% | 1 | 2 | 3 | Build foundation on easy samples |
| ASCENT | 15–35% | 2 | 3 | 1 | Ramp up difficulty |
| PEAK | 35–65% | 5 | 2 | 0 | Maximum focus on hard samples |
| DESCENT | 65–85% | 2 | 3 | 1 | Wind down |
| CONSOLIDATE | 85–100% | 1 | 2 | 3 | Reinforce all learned material |
Each sample maintains a Q-value representing its "learnability":
A sample cannot be frozen unless its Q-value exceeds min_q_for_freeze — preventing premature freezing.
GPT-2 on OpenR1-Math-220k (1k samples, 3 epochs, CPU)
| Epoch | FREEZE | LIGHT | FOCUS | HARD | Avg Loss |
|---|---|---|---|---|---|
| 0 | 0.0% | 0.0% | 100.0% | 0.0% | — |
| 1 | 0.0% | 0.2% | 78.6% | 21.2% | 4.20 |
| 2 | 0.0% | 19.5% | 37.9% | 42.6% | 1.88 |
| 3 | 0.0% | 19.5% | 37.9% | 42.6% | 1.73 |
Loss dropped 58% in 3 epochs. GEKO correctly routed 3× compute to 43% of samples it identified as HARD math reasoning problems. 20% graduated to LIGHT. On a GPU with more epochs, FREEZE samples accumulate rapidly and savings compound.
GEKOTrainer(
model, # Any nn.Module
train_dataset, # Must return dicts with 'input_ids'
tokenizer=None, # Stored but not called internally
eval_dataset=None, # Optional evaluation dataset
config=None, # GEKOConfig
args=None, # GEKOTrainingArgs
lora_config=None, # peft.LoraConfig — applied automatically
compute_confidence=None, # fn(outputs, batch) → Tensor[B]
compute_correctness=None, # fn(outputs, batch) → BoolTensor[B]
)| Method | Description |
|---|---|
trainer.train() |
Run full GEKO training loop |
trainer.get_efficiency_report() |
Bucket stats + compute savings |
trainer.get_pruned_count() |
Number of samples permanently pruned |
trainer.save_checkpoint(path) |
Save model weights + GEKO state |
trainer.load_checkpoint(path) |
Restore from checkpoint and resume |
Core
| Argument | Default | Description |
|---|---|---|
output_dir |
"./geko_output" |
Checkpoint directory |
num_epochs |
3 |
Training epochs |
batch_size |
32 |
Per-device batch size |
learning_rate |
5e-5 |
AdamW learning rate |
weight_decay |
0.01 |
AdamW weight decay |
warmup_steps |
100 |
Linear LR warmup steps |
logging_steps |
100 |
Log every N optimizer steps |
save_steps |
1000 |
Checkpoint every N optimizer steps |
eval_steps |
500 |
Evaluate every N optimizer steps |
max_grad_norm |
1.0 |
Gradient clipping |
gradient_accumulation_steps |
1 |
Steps before optimizer update |
seed |
42 |
Reproducibility seed |
save_at_end |
True |
Save final checkpoint |
v0.3.0 — Efficiency
| Argument | Default | Description |
|---|---|---|
bf16 |
False |
BF16 mixed precision (Ampere+ GPUs, no GradScaler needed) |
fp16 |
False |
FP16 mixed precision (older GPUs, with GradScaler) |
gradient_checkpointing |
False |
Recompute activations — ~4× activation memory saving |
compile_model |
False |
torch.compile — 20–50% throughput boost (PyTorch 2.0+) |
use_8bit_optimizer |
False |
8-bit AdamW via bitsandbytes — ~2× optimizer memory saving |
dataloader_num_workers |
-1 |
DataLoader workers (-1 = auto-detect; 0 on macOS) |
dataloader_persistent_workers |
True |
Keep workers alive between epochs |
dataloader_prefetch_factor |
2 |
Batches to prefetch per worker |
| Field | Default | Description |
|---|---|---|
freeze_confidence |
0.85 |
Confidence threshold to enter FREEZE |
freeze_quality |
0.80 |
Q-value threshold to enter FREEZE |
focus_confidence |
0.60 |
Confidence split between FOCUS and HARD |
bucket_weights |
(3, 1, 0) |
Sampling weights: (HARD, FOCUS, LIGHT) |
use_curriculum |
True |
Enable Mountain Curriculum |
q_value_lr |
0.1 |
EMA rate for Q-value updates |
min_q_for_freeze |
0.8 |
Minimum Q-value to freeze a sample |
q_value_loss_scale |
10.0 |
Loss normalizer for Q updates |
repartition_every |
1 |
Re-partition every N epochs |
log_bucket_stats |
True |
Print bucket distribution each epoch |
max_times_seen |
50 |
Max training passes per sample |
prune_frozen_after |
0 |
Permanently remove samples frozen N+ consecutive epochs (0 = disabled) |
Preset configs:
from geko.core import GEKO_AGGRESSIVE, GEKO_BALANCED, GEKO_CONSERVATIVE
# AGGRESSIVE: freeze_confidence=0.90, weights=(5, 2, 0) — max hard-sample focus
# BALANCED: freeze_confidence=0.85, weights=(3, 2, 1) — default
# CONSERVATIVE: freeze_confidence=0.80, weights=(2, 2, 1) — gentletrainer = GEKOTrainer(model=model, train_dataset=dataset, args=args)
trainer.load_checkpoint("./geko_output/checkpoint-1000")
trainer.train() # picks up from where it left off — all sample states includedShould I use GEKO for pre-training or fine-tuning? Fine-tuning only. GEKO's value comes from differentiating samples the model has already partially learned from ones it hasn't — that gap only exists meaningfully after pre-training. On a randomly initialized model, every sample looks equally hard, so GEKO's buckets won't diverge and savings will be minimal. Use GEKO for SFT, instruction tuning, domain adaptation, RLHF-style training, or any task-specific fine-tuning on top of a pre-trained base model.
Does GEKO work with multi-GPU / DDP?
Not natively in v0.3.0 — GEKO's per-sample state tracking is designed for single-GPU or single-node training. Multi-GPU support via DistributedDataParallel is planned.
What's the memory overhead of tracking sample states? Negligible. Each sample stores ~5 floats (confidence, Q-value, loss, bucket, counter). 1 million samples ≈ 40 MB of state — well within RAM for any realistic dataset size.
Does it work with custom loss functions?
Yes. GEKO calls your model's forward pass and reads outputs.loss. If your model returns a custom output object with .loss, it works out of the box. For per-sample correctness (recommended), implement compute_correctness(outputs, batch) → BoolTensor[B].
Can I use it with HuggingFace datasets?
Yes — wrap it in a torch.utils.data.Dataset that returns dicts with 'input_ids'. GEKO does not call .map() or any HuggingFace-specific APIs internally.
What if my dataset doesn't have a 'labels' key?
GEKO only requires 'input_ids'. Labels are optional — if not present, GEKO falls back to batch-level correctness (one correctness score per batch instead of per sample). Override compute_correctness for true per-sample bucketing.
Does GEKO add training overhead? Minimal. Per-epoch overhead is one O(N) pass over sample states to reclassify buckets — typically under 1 second for 100k samples. The weighted sampler rebuild adds another second. Both are negligible compared to actual training time.
- Gradio web interface — full training UI, no code required (
geko-appCLI entry point) - GEKO config presets — Aggressive / Balanced / Conservative, one click to apply
freeze_qualityslider — exposes the Q-value gate for FREEZE in the UI- Eval dataset support — enter any HuggingFace eval dataset + split; live eval loss stat box
- Steps/sec + ETA stat boxes — computed from a rolling 20-step window
- Eval Loss stat box — populated by dedicated
eval_lossevents from the trainer - Training summary card — rendered on completion with final loss, compute saved, steps, output path
- Resume from checkpoint — textbox input wired to
trainer.load_checkpoint() - Custom output directory — user-controlled, defaults to
./geko_output - Clear / Reset button — wipes all live outputs and charts
- Hardware info strip — PyTorch version + GPU name/VRAM or "CPU only" at page load
- Stop button — safely halts training between batches
- Added
pip install gekolib[app]extra (gradio, plotly, transformers, datasets) - Added
geko-appconsole script entry point
- LoRA / PEFT integration — pass
lora_configtoGEKOTrainer; prints trainable/frozen param counts - BF16 mixed precision —
bf16=TrueinGEKOTrainingArgs; unified autocast with FP16 - Gradient checkpointing —
gradient_checkpointing=True; ~4× activation memory reduction - 8-bit optimizer —
use_8bit_optimizer=True; requiresbitsandbytes - torch.compile —
compile_model=True; graceful fallback on unsupported environments - Fast DataLoader — auto num_workers, persistent workers, prefetch factor, non-blocking GPU transfers
- Stable bucket caching — skip DataLoader rebuild when bucket distribution changes < 5%
- Dynamic dataset pruning —
prune_frozen_afterinGEKOConfig; permanently removes mastered samples - Added
apply_loraandis_peft_availableexports - Added
extras_require:peft,bnb,allinsetup.py - Fixed eval DataLoader worker resolution
- All 120 tests passing
- Per-sample correctness via 1D loss — true per-sample bucketing
- One-time warning on batch-level correctness fallback
GEKODatasetrequires'input_ids'key with clearTypeError- All-FREEZE epoch skip
PartitionStatsfully serialized to checkpointsload_checkpointrestores partition history- Linear warmup LR scheduler
- Optional evaluation loop
max_times_seenenforcement- GitHub Actions CI (Python 3.9 / 3.10 / 3.11)
- Mixed-precision training via
torch.amp - Gradient accumulation
- Per-sample state updates inside training loop
- Initial release: GEKO algorithm, Mountain Curriculum, Q-value tracking
@software{geko2026,
author = {Syed Abdur Rehman},
title = {GEKO: Gradient-Efficient Knowledge Optimization},
year = {2026},
url = {https://github.com/Abd0r/GEKO},
doi = {10.5281/zenodo.18750303}
}Apache 2.0
GEKO is a solo open-source project. If it's useful to you, any support goes directly toward keeping it maintained and growing.
GEKO — Train smarter, not harder.