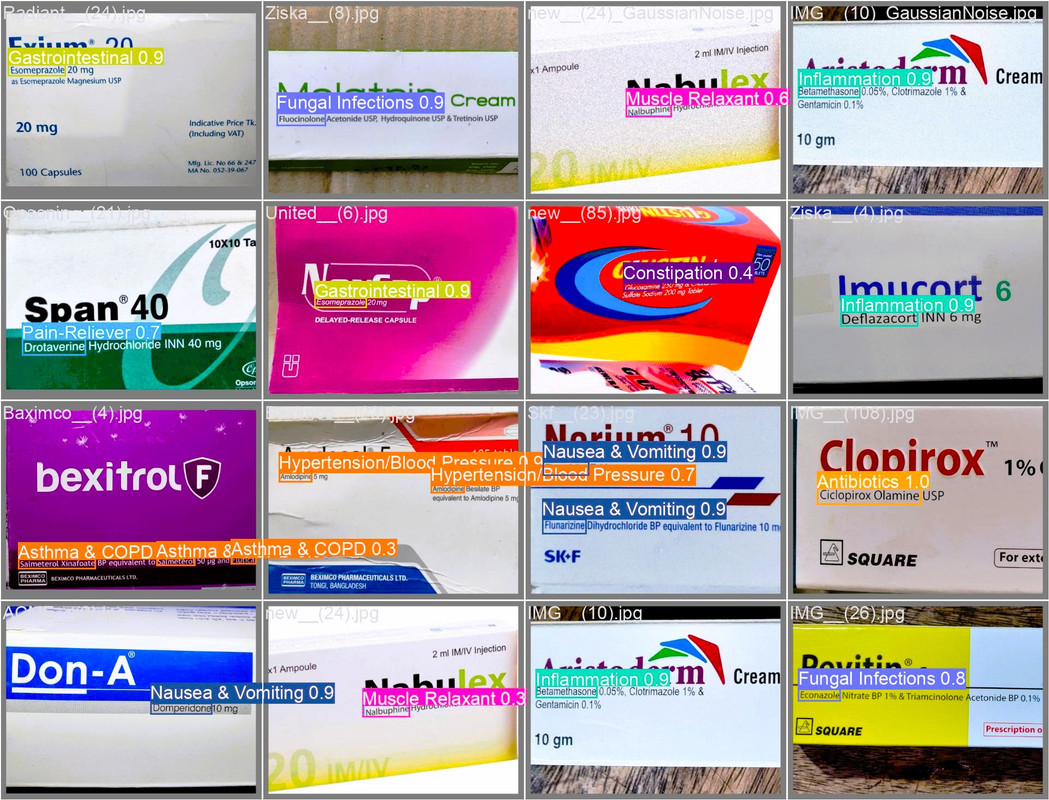
train: /content/Datasettest/train.txt val: /content/Datasettest/val.txt nc: 42 names: ['Brand Name','Mental Health','Hypertension/Blood Pressure','Antibiotics','Gastrointestinal','Vitamins & Minerals','Diabetes','Allergies','Cough & Cold','Inflammation','Pain-&-Fever-Reliever','Pain-Reliever','Nausea & Vomiting','Fungal Infections','Cholesterol','Cardiovascular','Constipation','Asthma','Diarrheal','Muscle Relaxant','Antiseptic','Asthma & Allergy','Asthma & COPD','Menstrual','Herbal Preparation','Parasites','Urological treatment','Neuropathic Pain','Neurological/Brain Disease','Migraine' ,'Nasal Decongestant','Multi-Purpose Medication','Menstrual','Cancer Treatment','Thyroid Hormones','Birth Control Pills','Viral Flu','Antiplatelet Medications','Anaemia','Arthritis', Miscellaneous']
[CSV Dataset file for verification][https://docs.google.com/spreadsheets/d/1d-qfGSXfb6onXsAqS1jgL_CerTP0q316P9xYRl4fexc/edit?usp=sharing]
Code for using Yolov5 Drug detection, verification, and generic name based drug suggestion done in Google Colab:
from google.colab import drive
drive.mount('/content/drive')
#installs dependencies
!sudo apt install tesseract-ocr
!sudo apt install libtesseract-dev
!sudo pip install pytesseract
!pip install pydub
!pip install gtts
import pytesseract
from PIL import Image
import re
import yaml
import pandas as pd
import cv2
import matplotlib.pyplot as plt
from IPython.display import Audio, display
import torch
import os
from IPython.display import Image, clear_output
import os
from IPython.display import Image, display
from gtts import gTTS
import io
%cd /content/drive/MyDrive
!git clone https://github.com/ultralytics/yolov5.git
%cd /content/drive/MyDrive/yolov5
!pip install -r requirements.txt
%cd /content
!git clone https://github.com/Anik-nath/DrugDataset.git
train_img_path = "/content/DrugDataset/images/train"
val_img_path = "/content/DrugDataset/images/val"
with open('/content/DrugDataset/train.txt', "a+") as f:
img_list = os.listdir(train_img_path)
for img in img_list:
f.write(os.path.join(train_img_path,img+'\n'))
print("Done")
with open('/content/DrugDataset/val.txt', "a+") as f:
img_list = os.listdir(val_img_path)
for img in img_list:
f.write(os.path.join(val_img_path,img+'\n'))
print("Done")
train: /content/DrugDataset/train.txt val: /content/DrugDataset/val.txt nc: 38 names: ['Mental Health', 'Hypertension/Blood Pressure', 'Antibiotics', 'Gastrointestinal', 'Vitamins & Minerals', 'Diabetes', 'Allergies', 'Cough & Cold','Inflammation','Pain-&-Fever-Reliever','Pain-Reliever','Nausea & Vomiting', 'Fungal Infections', 'Cholesterol', 'Cardiovascular', 'Constipation', 'Asthma', 'Diarrheal', 'Muscle Relaxant', 'Antiseptic', 'Asthma & Allergy', 'Asthma & COPD', 'Menstrual', 'Herbal Preparation', 'Parasites', 'Urological treatment', 'Neuropathic Pain', 'Neurological/Brain Disease', 'Migraine' ,'Nasal Decongestant', 'Multi-Purpose Medication', 'Cancer Treatment', 'Thyroid Hormones', 'Birth Control Pills', Viral Flu', 'Antiplatelet Medications', 'Anemia', 'Arthritis']
%cd /content/drive/MyDrive/yolov5
!python train.py --img 640 --batch 16 --epochs 100 --data data/custom.yaml --weights yolov5x.pt –cache
!python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.1 --source /content/drive/MyDrive/yolov5/testImages/ --save-txt --save-conf
import os
from IPython.display import Image, display
detect_results_path = '/content/drive/MyDrive/yolov5/runs/detect'
latest_folder_path = max((os.path.join(detect_results_path, f) for f in os.listdir(detect_results_path) if os.path.isdir(os.path.join(detect_results_path, f))),
key=os.path.getmtime)
print(latest_folder_path)
limit = 10000
for i, imageName in enumerate(os.listdir(latest_folder_path)):
if i < limit and imageName.lower().endswith(('.jpg', '.jpeg')):
display(Image(filename=os.path.join(latest_folder_path, imageName)))
print("\n")
df = pd.read_csv('/content/drive/MyDrive/yolov5/FinalDataSheet.csv')
df.head(10)
from PIL import Image
def load_data_yaml(data_yaml_path):
with open(data_yaml_path, 'r') as file:
data = yaml.safe_load(file)
return data
def extract_class_names_by_indices(results_file_path, data_yaml_path):
with open(results_file_path, 'r') as file:
lines = file.readlines()
class_info = {}
for line in lines:
index, confidence = line.strip().split()[0], float(line.strip().split()[-1])
class_info[int(index)] = confidence # Store confidence value for each index
# Get the index and confidence
last_line = lines[-1]
last_index, last_confidence = last_line.strip().split()[0], float(last_line.strip().split()[-1])
# Ensure only the last occurrence of the index is considered
unique_class_indices = {int(index) for index, conf in class_info.items() if conf == last_confidence and index == int(last_index)}
data = load_data_yaml(data_yaml_path)
all_class_names = data['names']
detected_class_names = [all_class_names[index] for index in unique_class_indices]
return detected_class_names
def get_latest_folder(directory):
all_folders = [f for f in os.listdir(directory) if os.path.isdir(os.path.join(directory, f))]
latest_folder = max(all_folders, key=lambda f: os.path.getmtime(os.path.join(directory, f)))
return latest_folder
def get_latest_files(directory, extension):
try:
files = [f for f in os.listdir(directory) if any(f.lower().endswith(ext.lower()) for ext in extension)]
if not files:
raise FileNotFoundError(f"")
latest_file = max(files, key=lambda f: os.path.getmtime(os.path.join(directory, f)))
return os.path.join(directory, latest_file)
except FileNotFoundError as e:
print(e)
return None
def extract_text_and_search(folder_path):
image_files = [f for f in os.listdir(folder_path) if f.lower().endswith(('.jpg', '.jpeg', '.JPG'))]
clean_extracted_text_list = []
for image_file in image_files:
image_path = os.path.join(folder_path, image_file)
bbox_path = os.path.join(folder_path, image_file.replace('.jpg', '.txt').replace('.jpeg', '.txt').replace('.JPG', '.txt'))
original_image = cv2.imread(image_path)
all_boxes = []
with open(bbox_path, 'r', encoding='utf-8') as file:
for line in file:
box_info = line.strip().split()
all_boxes.append(box_info)
max_confidence_box = max(all_boxes, key=lambda box: float(box[-1]))
class_id, center_x, center_y, width, height, confidence = map(float, max_confidence_box)
x = int((center_x - width / 2) * original_image.shape[1])
y = int((center_y - height / 2) * original_image.shape[0])
w = int(width * original_image.shape[1])
h = int(height * original_image.shape[0])
x = max(0, x)
y = max(0, y)
w = min(w, original_image.shape[1] - x)
h = min(h, original_image.shape[0] - y)
cv2.rectangle(original_image, (x, y), (x + w, y + h), (0, 255, 0), 2)
cropped_image = original_image[y:y+h, x:x+w]
display_size = (int(w * 0.2), int(h * 0.2))
resized_cropped_image = cv2.resize(cropped_image, display_size)
pil_cropped_image = Image.fromarray(cv2.cvtColor(cropped_image, cv2.COLOR_BGR2RGB))
grayscale_cropped_image = cv2.cvtColor(cropped_image, cv2.COLOR_BGR2GRAY)
_, binary_cropped_image = cv2.threshold(grayscale_cropped_image, 128, 255, cv2.THRESH_BINARY)
extracted_text_grayscale = pytesseract.image_to_string(grayscale_cropped_image)
clean_extracted_text = re.sub(r'[^A-Za-z0-9\s]', '', extracted_text_grayscale)
clean_extracted_text_list.append(clean_extracted_text)
return clean_extracted_text_list
detect_results_path = '/content/drive/MyDrive/yolov5/runs/detect'
latest_detection_folder = get_latest_folder(detect_results_path)
folder_path = os.path.join(detect_results_path, latest_detection_folder)
results_file_path = get_latest_files(folder_path, ['.txt'])
if results_file_path:
data_yaml_path = '/content/drive/MyDrive/yolov5/data/custom.yaml'
detected_class_names = extract_class_names_by_indices(results_file_path, data_yaml_path)
# detected_class = '/'.join(detected_class_names).strip()
if detected_class_names:
detected_class = '/'.join(detected_class_names).strip()
else:
detected_class = "miscellaneous"
extracted_texts = extract_text_and_search(folder_path)
generic = ' '.join(extracted_texts)
detected_generic_name = generic.strip()
print("DrugClassName:", detected_class)
print("GenericName:", detected_generic_name)
else:
print("No detection")
import base64
from IPython.display import HTML
import random
#Function to convert error message to sound
def text_to_voice(text):
tts = gTTS(text=text, lang='en')
mp3_fp = io.BytesIO()
tts.write_to_fp(mp3_fp)
mp3_fp.seek(0)
display(Audio(mp3_fp.read(), autoplay=True))
detected_generic_name = re.sub(r'[^\x20-\x7E]', '', detected_generic_name).strip()
matching_rows = df[
(df['Generic'].str.strip().str.lower().isin([detected_generic_name.strip().lower(), detected_generic_name.split()[0].strip().lower()]))
]
if not matching_rows.empty:
print(f"Generic = {detected_generic_name} is matched")
if detected_class.strip().lower() in matching_rows['Class Name'].str.strip().str.lower().unique():
print(f"Detected class '{detected_class}' matches the class in the row.")
related_image_paths = matching_rows[
(matching_rows['Generic'].str.strip().str.lower() == detected_generic_name.strip().lower()) |
(matching_rows['Generic'].str.split().str[0].str.strip().str.lower() == detected_generic_name.split()[0].strip().lower())
]['Image Path'].dropna().tolist()
if related_image_paths:
print(f"Displaying related drugs for class '{detected_class}' generic '{detected_generic_name}':")
# Shuffle the list of related image paths
random.shuffle(related_image_paths)
# Take the first 4 images if there are more than 4, otherwise take all available images
selected_images = related_image_paths[:6]
# Generate HTML code with image cards
html_code = "<div style='display: flex; flex-wrap: wrap;'>"
for i, image_path in enumerate(selected_images, 1):
with open(image_path, "rb") as image_file:
image_base64 = base64.b64encode(image_file.read()).decode('utf-8')
# Include the base64-encoded image in the HTML code with card-like styling
html_code += f"""
<div style='flex: 0 0 calc(25% - 10px); margin: 5px;'>
<div class='card' style='border: 1px solid #ddd; border-radius: 5px; overflow: hidden; cursor: pointer;' onclick='openImage("{image_base64}")'>
<img src='data:image/jpeg;base64,{image_base64}' alt='Image {i}' style='width:100%; height:100%; object-fit: cover;'>
</div>
</div>
# Start a new row after every 4 images
if i % 4 == 0:
html_code += "</div><div style='display: flex; flex-wrap: wrap;'>"
html_code += "</div>"
# JavaScript function to open the image in another tab
javascript_code = """
<script>
function openImage(imageBase64) {
var w = window.open("", "_blank");
w.document.write("<img src='data:image/jpeg;base64," + imageBase64 + "' style='width:100%; height:100vh; object-fit: cover;'>");
}
</script>
"""
# Display the HTML code with the JavaScript function
display(HTML(html_code + javascript_code))
else:
error_message = f"No related image paths found for '{detected_class}' and '{detected_generic_name}'."
print(error_message)
text_to_voice(error_message)
else:
error_message = f"Class '{detected_class}' is Wrong."
print(error_message)
text_to_voice(error_message)
else:
error_message = f"Generic = {detected_generic_name} is not detected correctly"
print(error_message)
text_to_voice(error_message)