- 这里我使用的是自己的linux服务器,我们以此为例进行安装, 由于jenkins基于java,
所以我们需要先安装java的环境(这里的版本根据需求安装):
- wget安装:类似于windows系统里的网页下载
- rpm安装:对已经下载的rpm包进行安装,类似于windows系统里.exe的安装
- yum安装:是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装
yum install java-1.8.0-openjdk*wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repoyum -y install apache-mavenwget https://pkg.jenkins.io/redhat/jenkins-2.230-1.1.noarch.rpm rpm -ivh jenkins-2.230-1.1.noarch.rpmvi /etc/sysconfig/jenkins //修改默认端口 默认是8080# systemctl start jenkins-
这时候打开浏览器可以输入 http://服务器地址ip+/8080
-
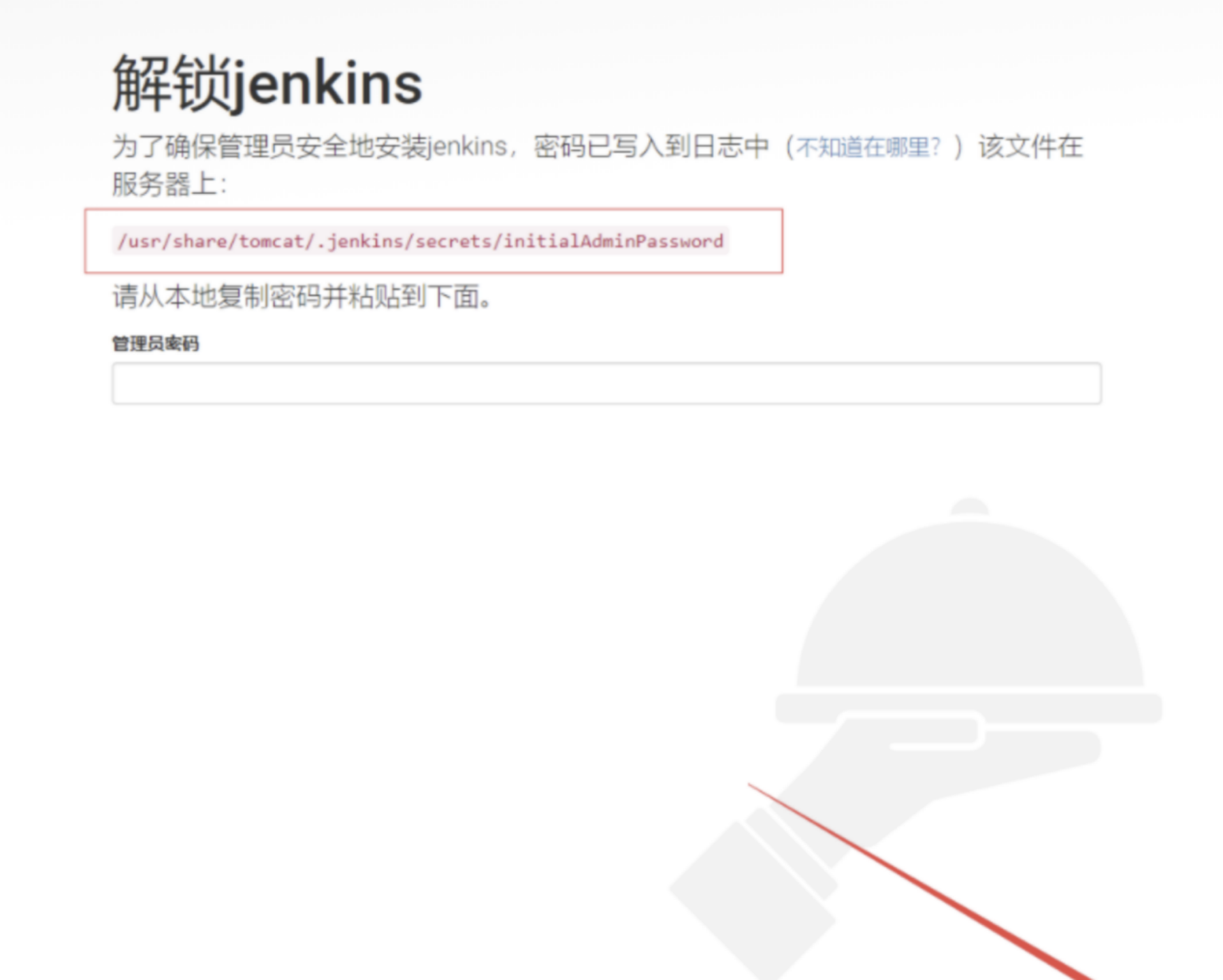
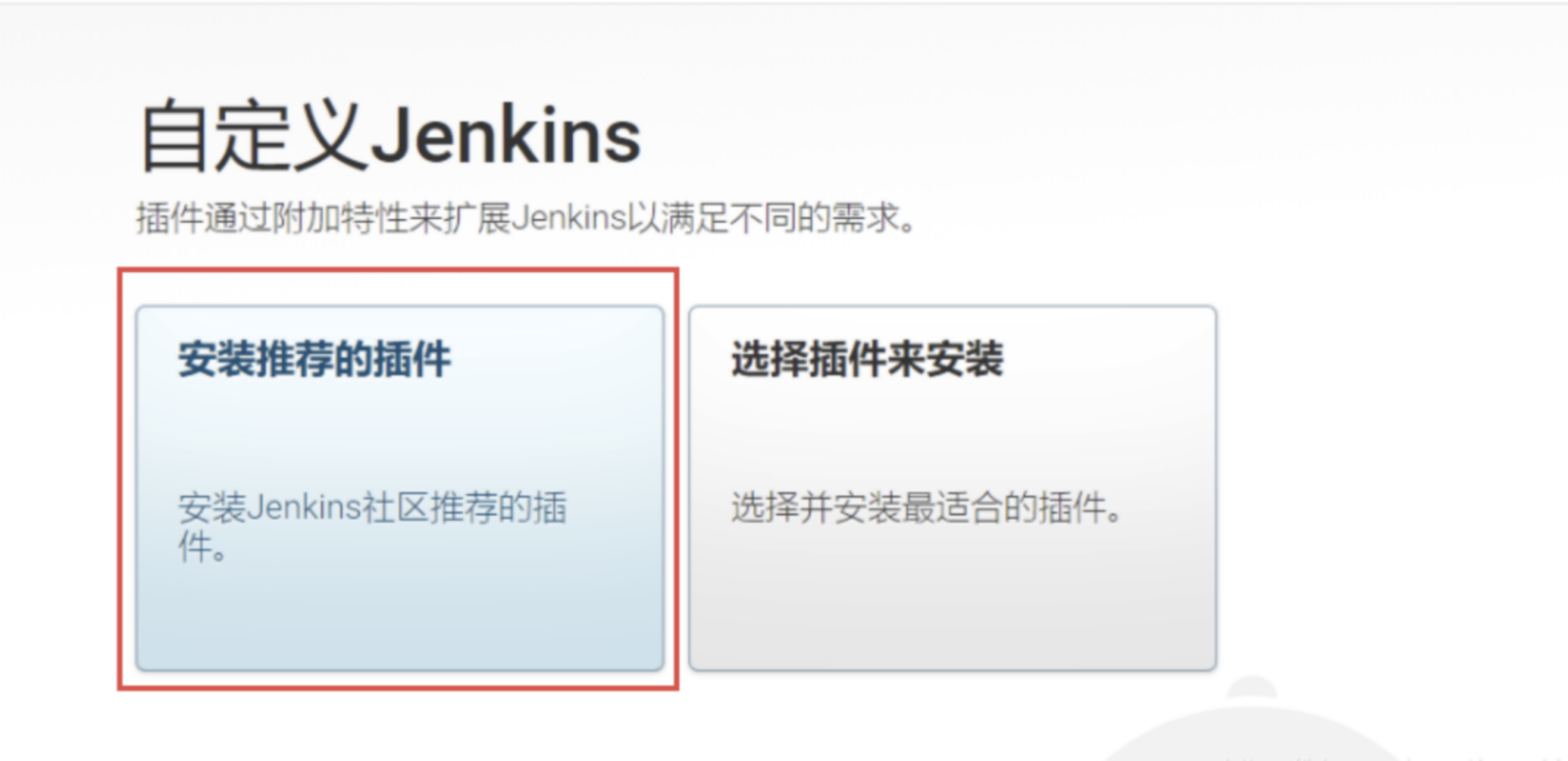
可以看到欢迎界面,根据页面提示路径 cat上面地址 查看第一次进入的密码,输入并以继续,接下来选择安装推荐插件
-
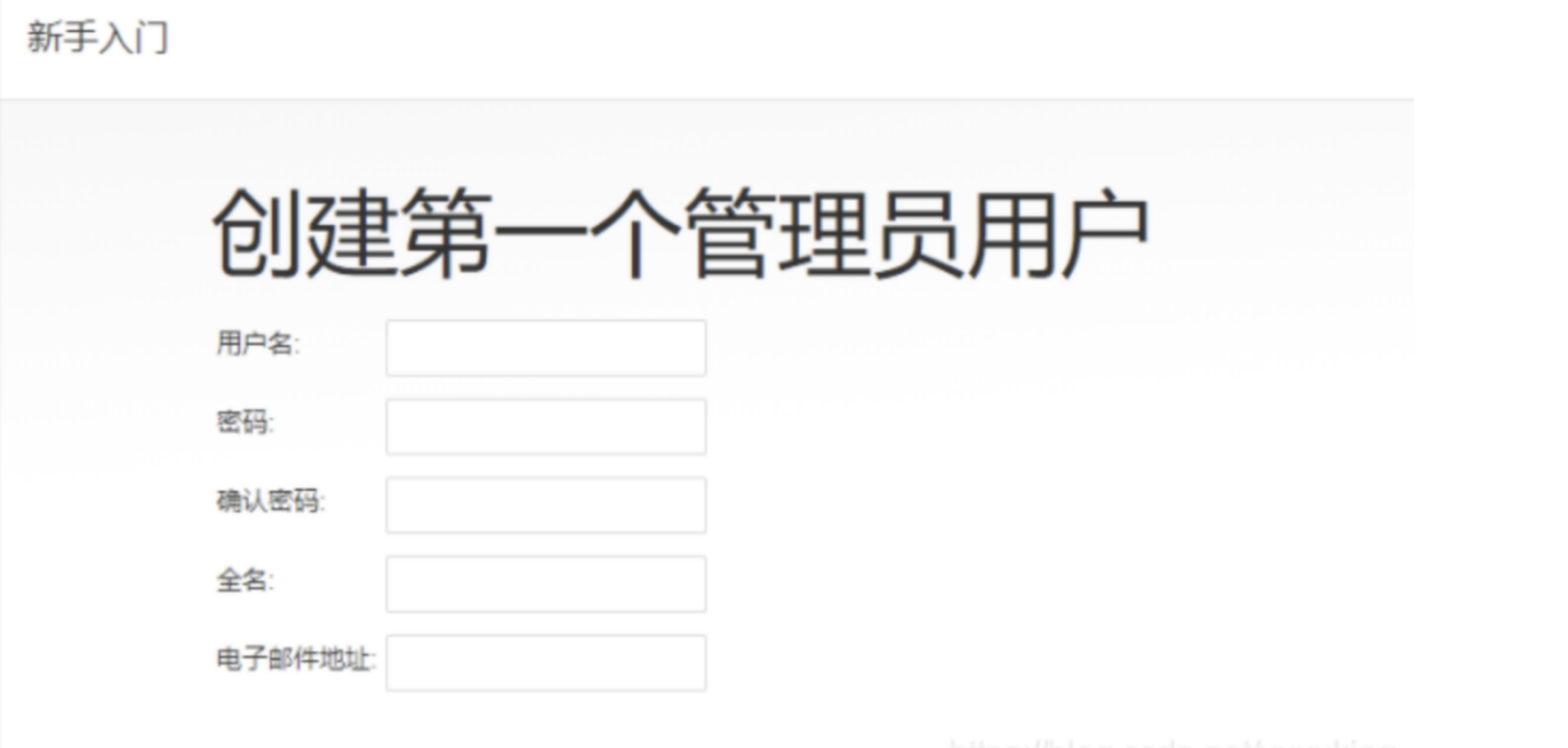
之后可以创建一个管理员账号,后续登陆使用设置的账号密码登陆即可
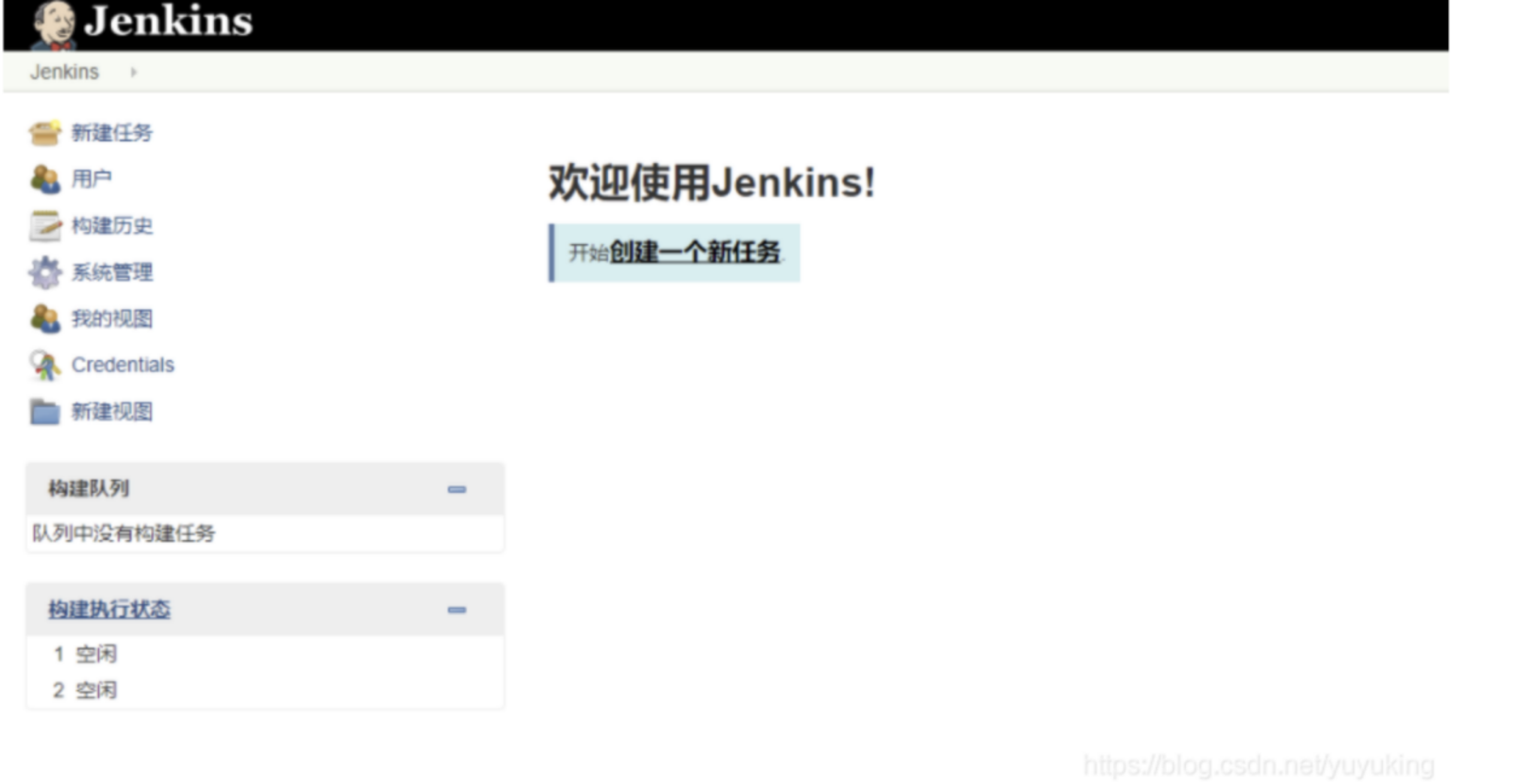
- 接下来 就会看到这个页面 表示安装完成
- 为了方便演示,我使用自己的github来做测试,关于对接gitlab的话可以参考jenkins配置gitlab, 先对github配置,首先登陆你的github账号依次点击右上角头像:
Settings->Developer settings->Personal access tokens->Generate new token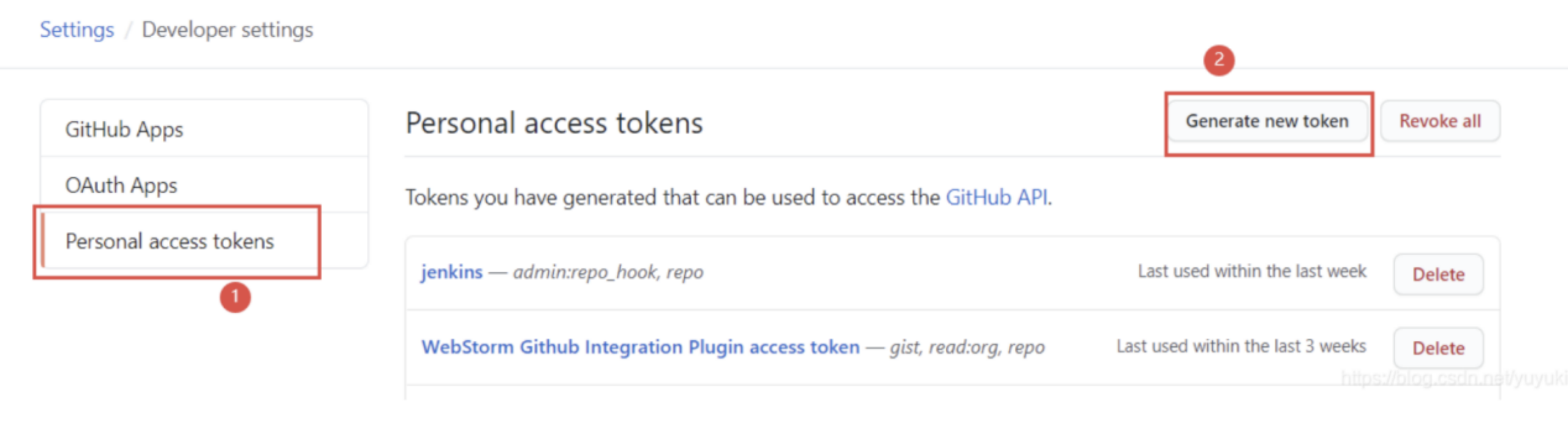
- 然后对Note命名为jenkins,勾选下图两项
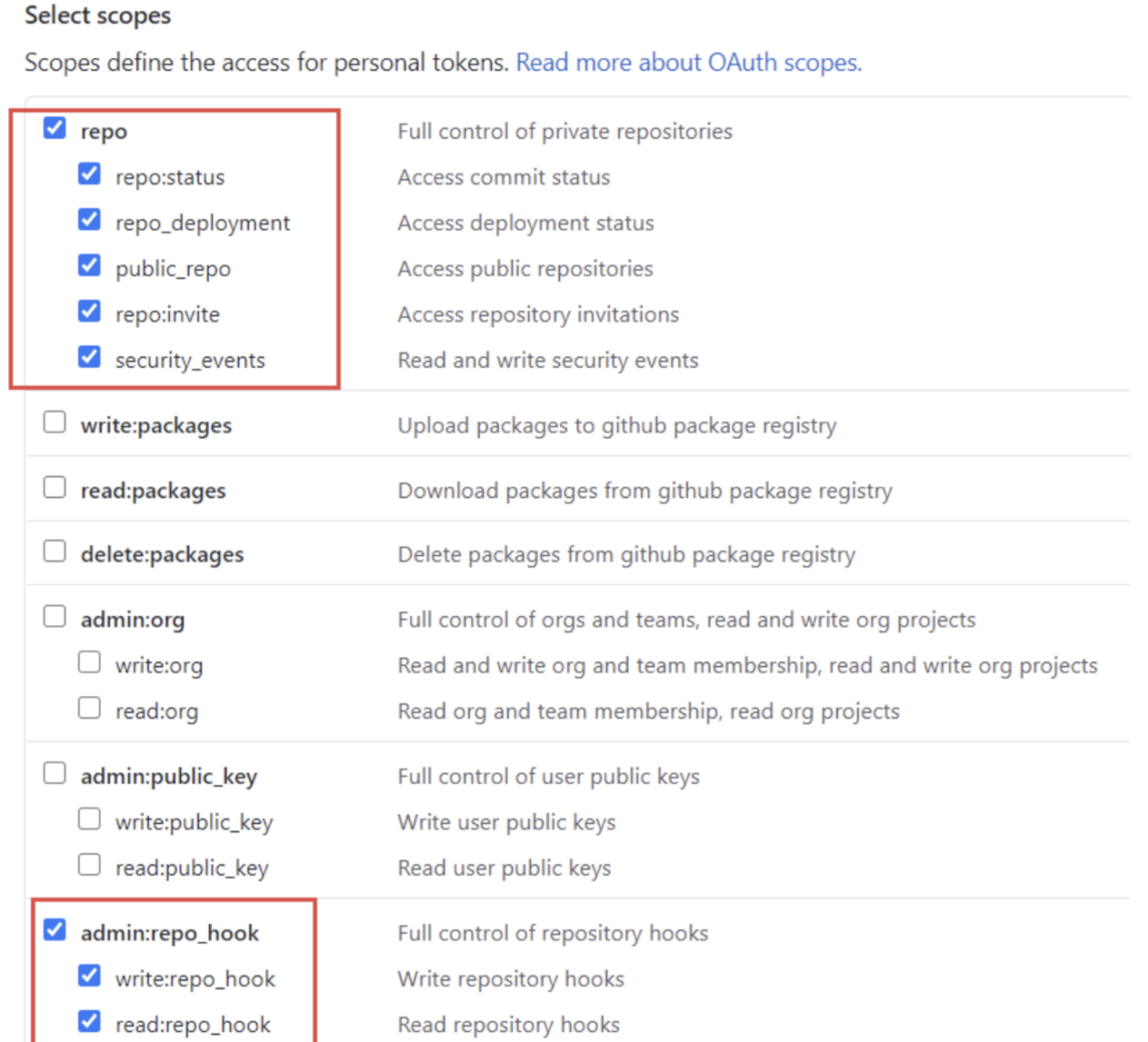
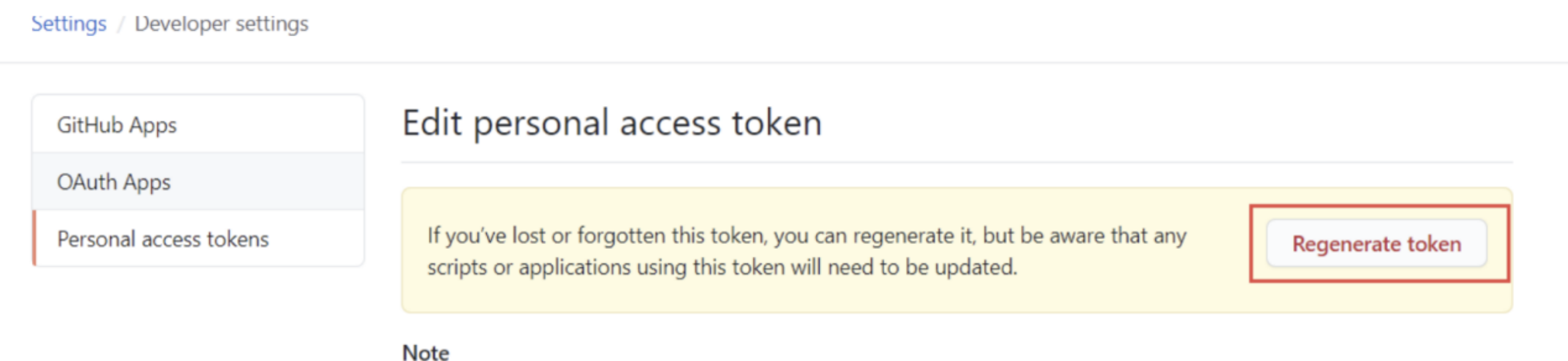
- 之后点击确定,第一次创建完成的后会在列表显示token的值,复制下来,如果忘记复制可以点击Regenerate token,会重新显示
- 依次点击系统管理->系统设置,找到GitHub,添加GitHub服务器,其中API URL是固定的,输入名称,点击添加,添加一个凭据。
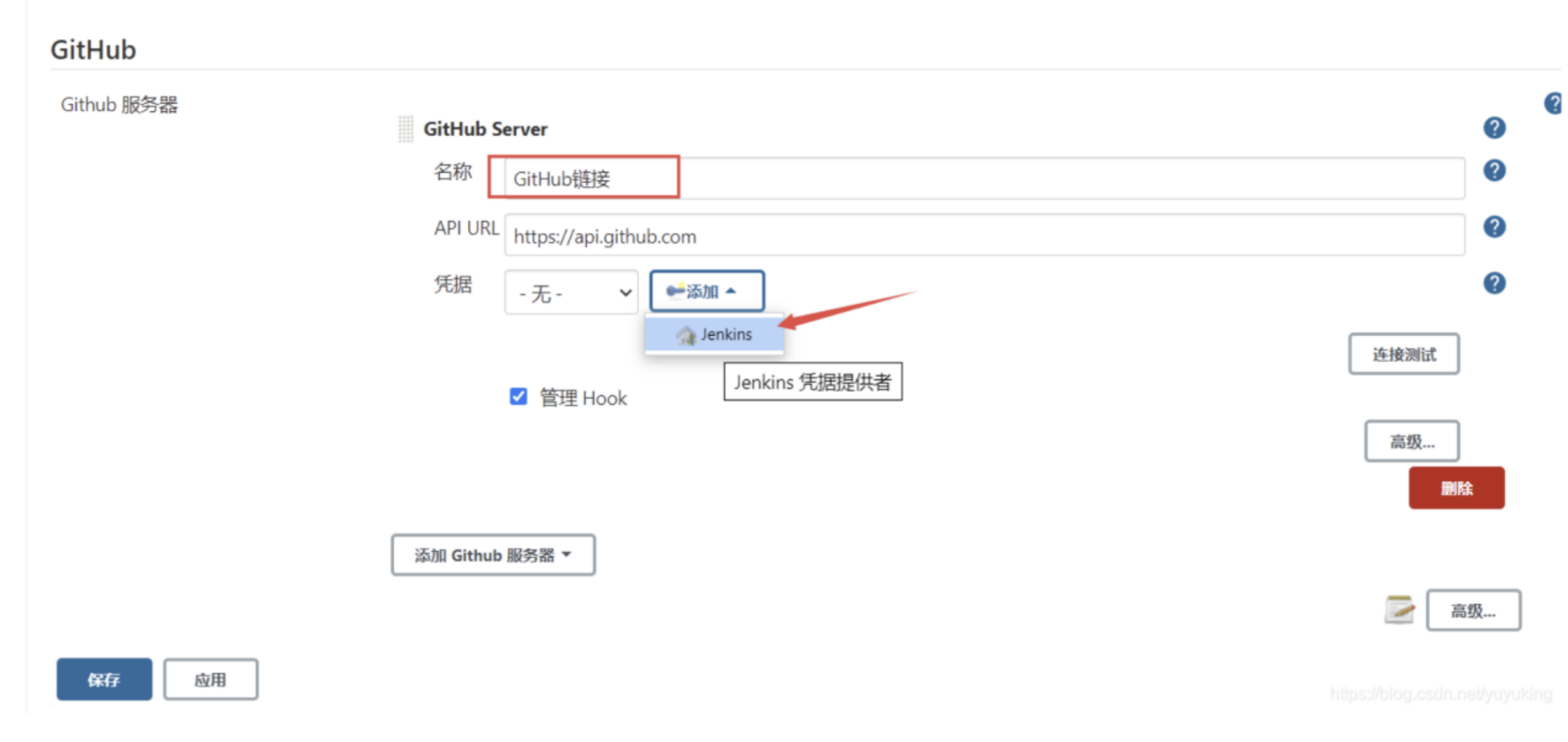
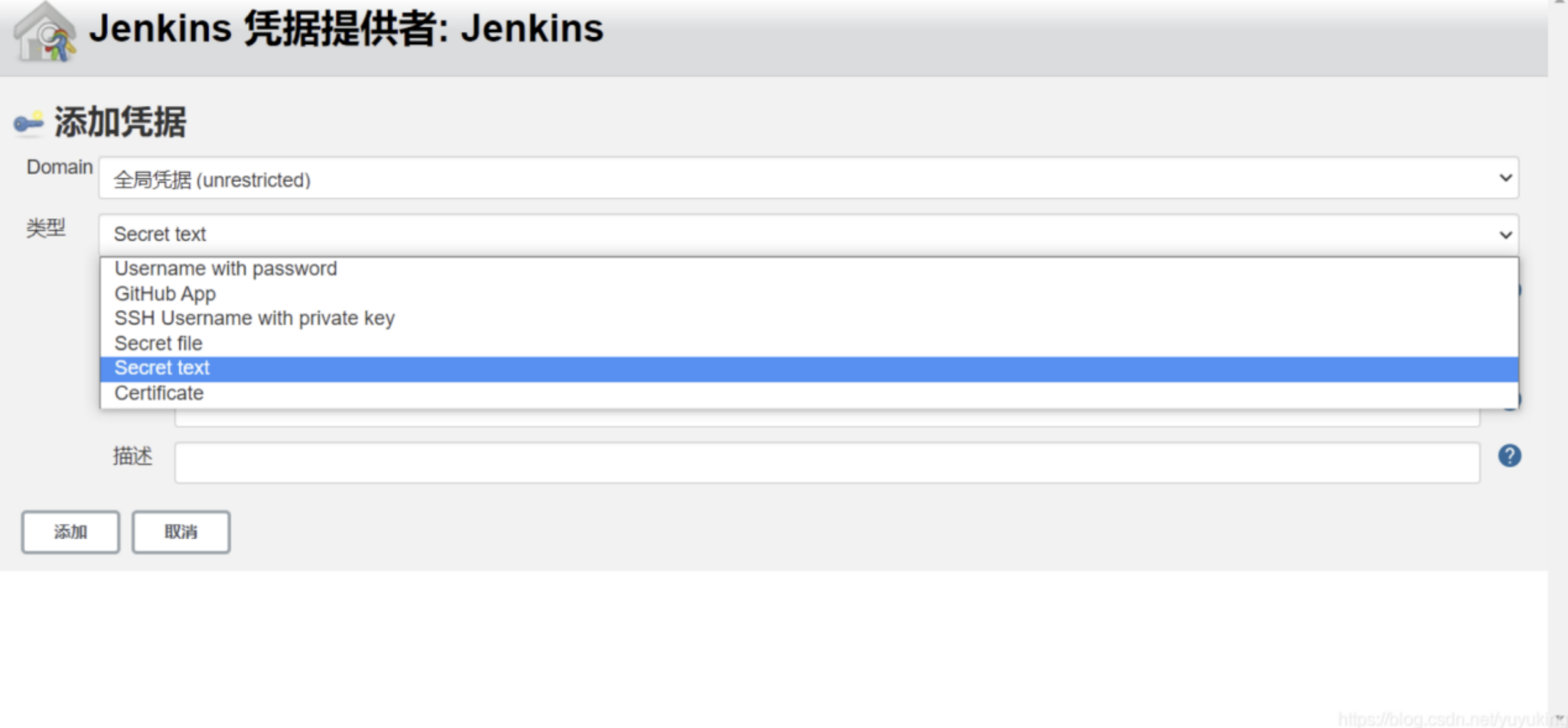
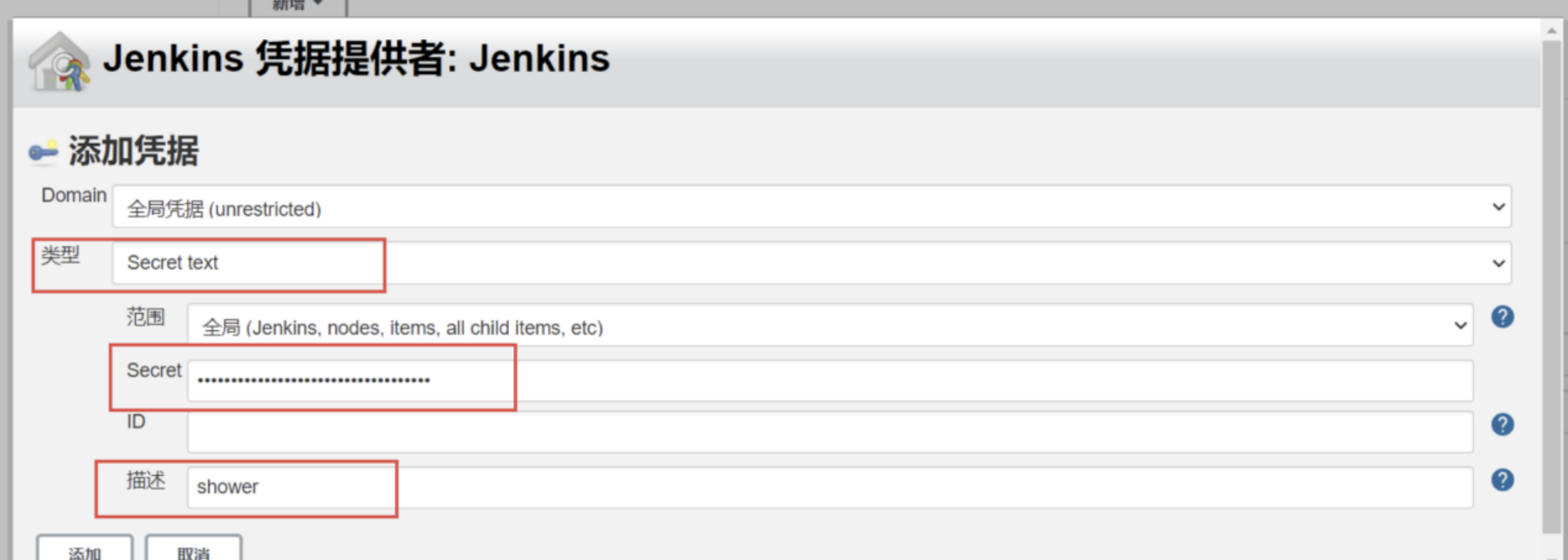
- 类型选择Secret text,Secret输入刚才复制的tonken,描述随意写,就是一个别名。
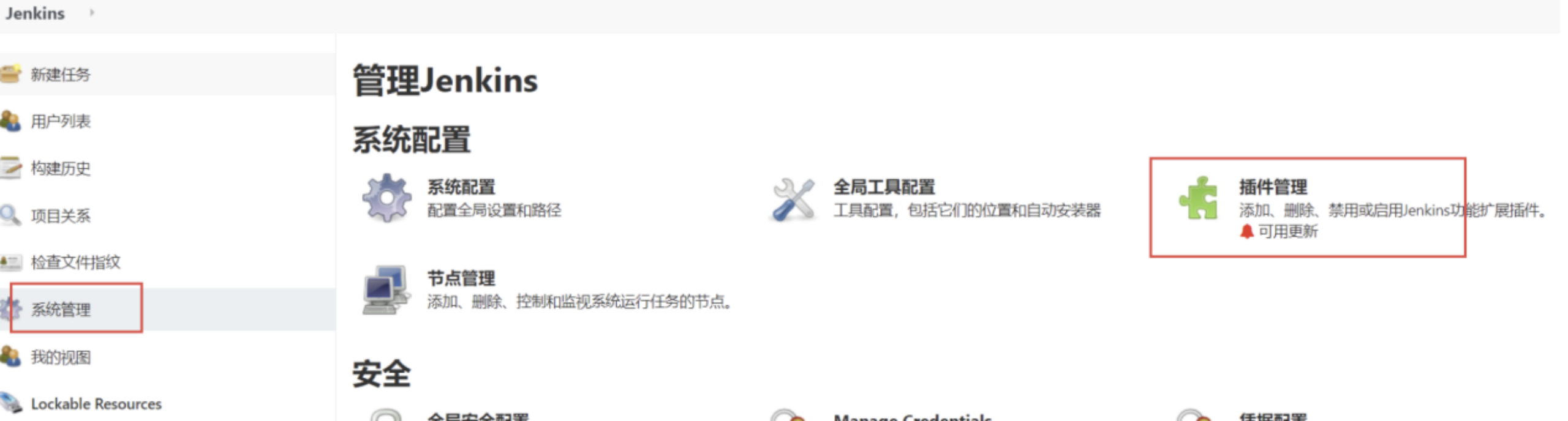
- 之后点击连接测试是否连接成功,上述安装步骤走完以后,我们就来安装我们所需要的一些插件,因为我们部署前端的项目是需要node环境的,所以我们要在jenkins的插件管理里安装一个nodejs插件 点击系统管理->插件管理
- 在可选插件里搜索nodejs
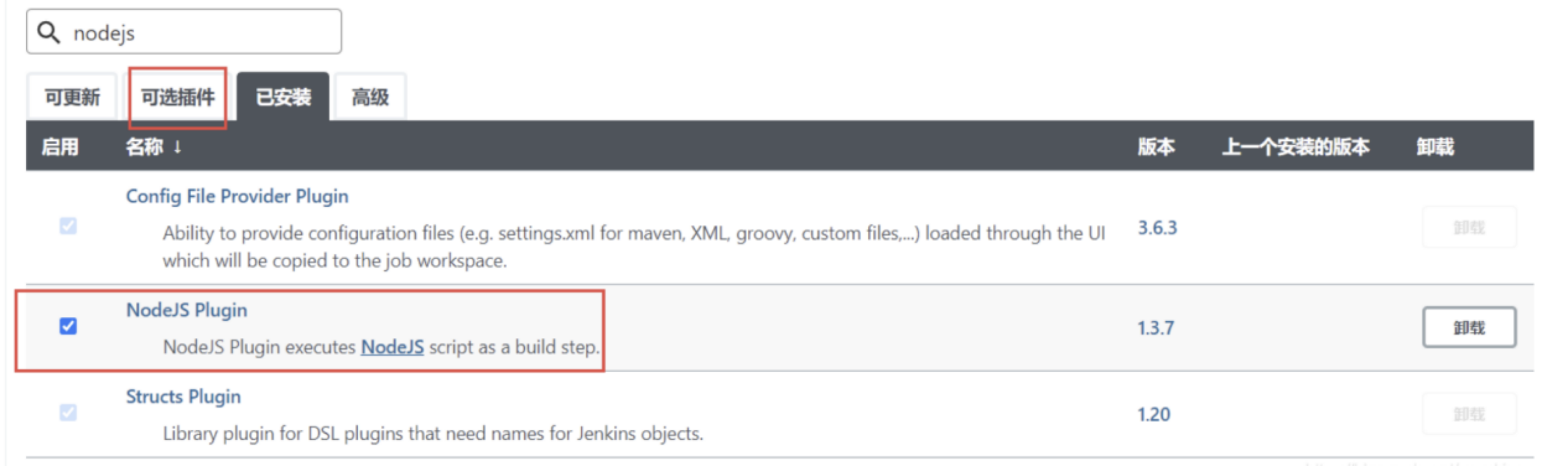
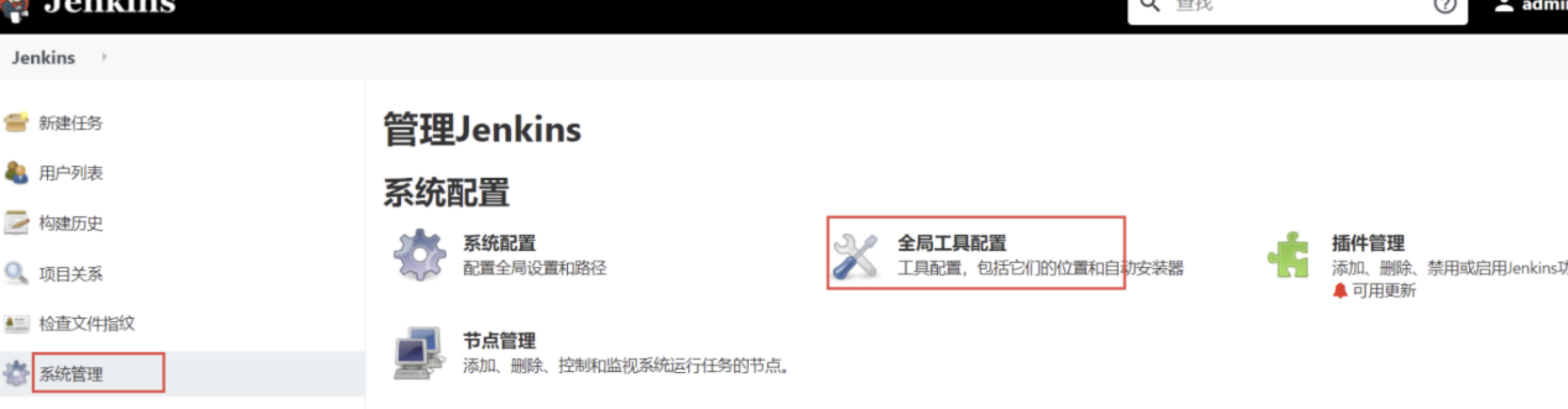
- 安装好以后重启一下jenkins,重启之后在系统设置-》全局工具配置中配置node
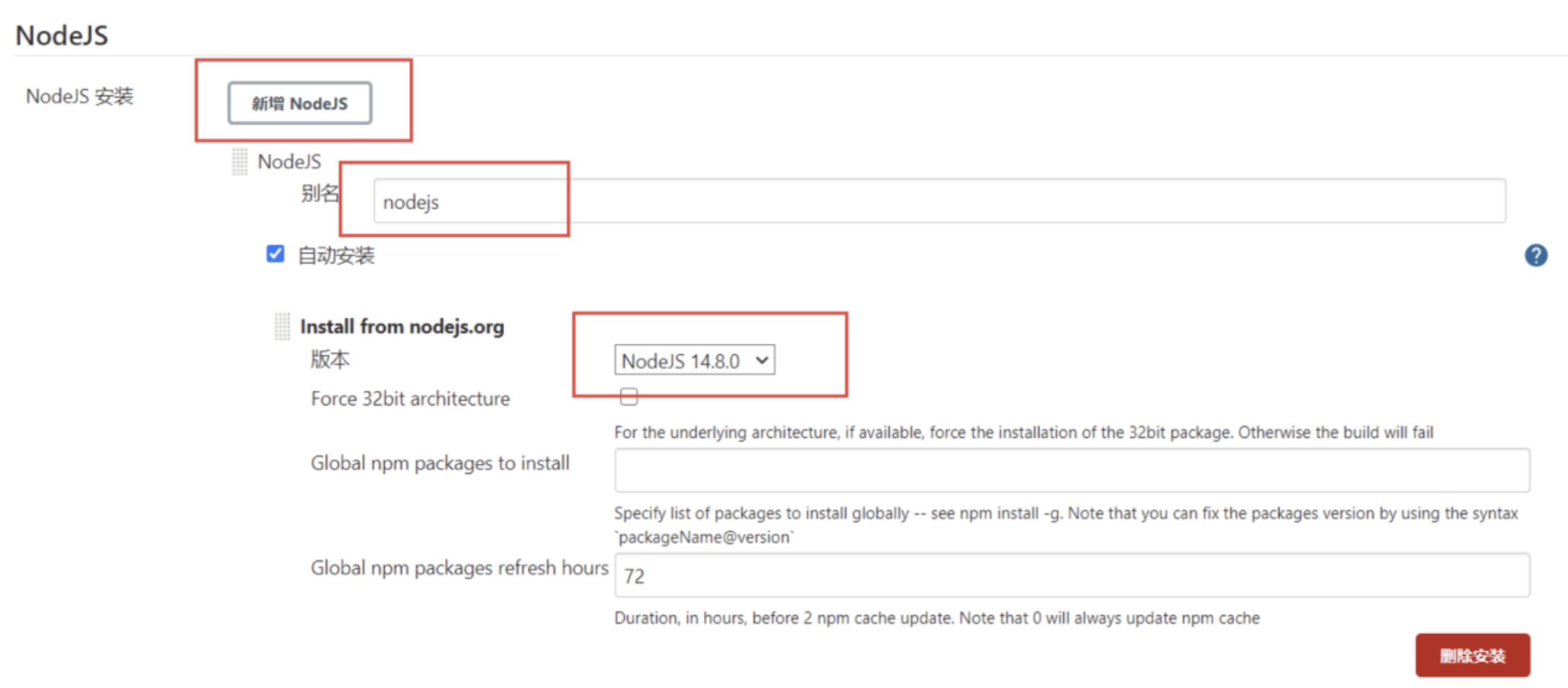
- 下拉找到Nodejs 新增node,选择版本
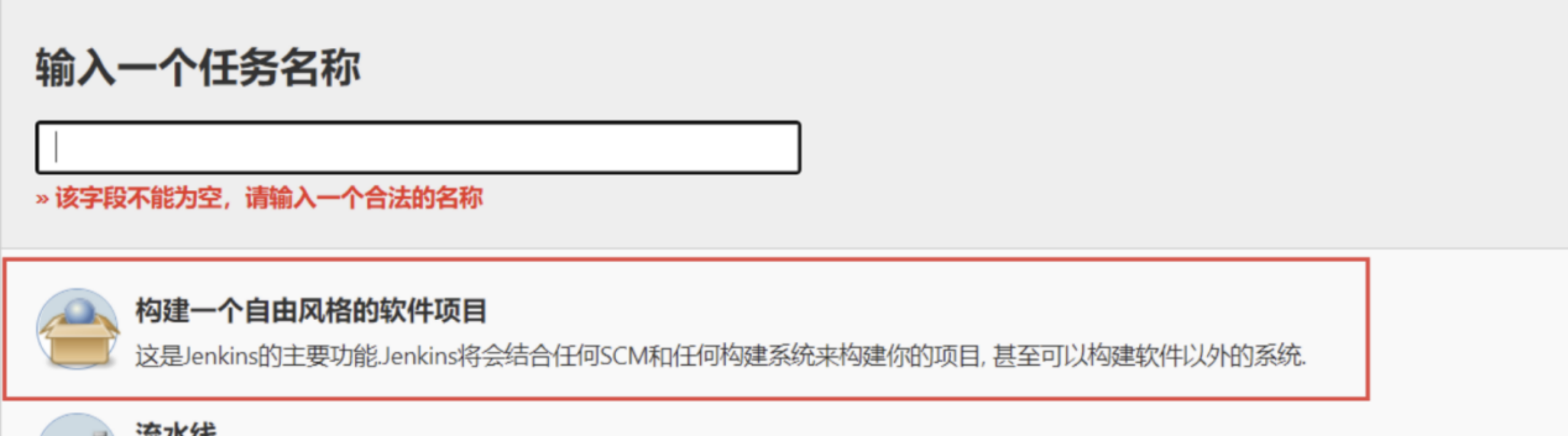
- 现在让我们来新建一个任务,输入名称,选择构建一个自由风格的软件项目
- 输入描述,写上你的git地址
- 输入描述,填写你的git地址
- 这里输入的url是以.git结尾的,就是你克隆项目是使用的url。
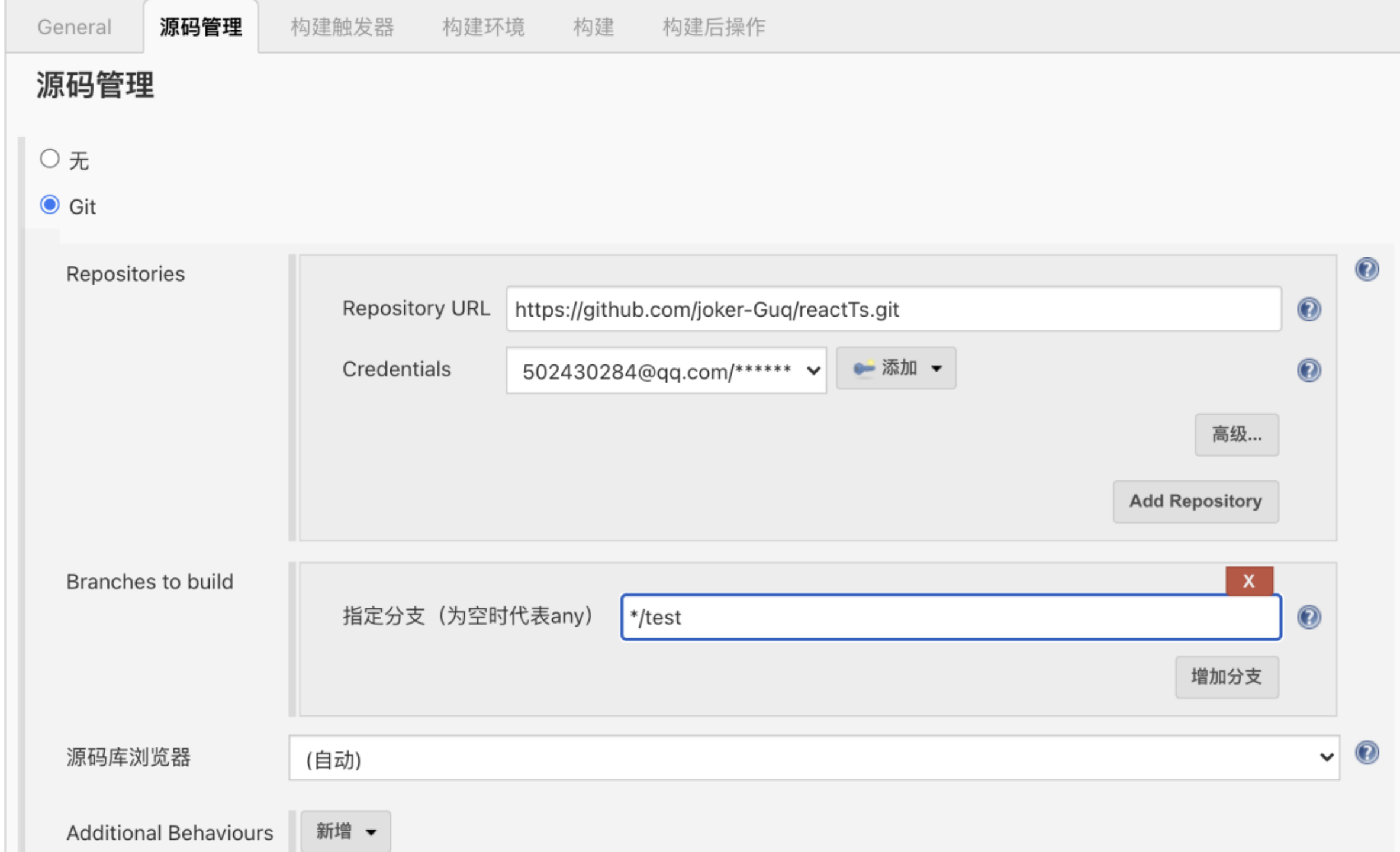
- 之后点击添加,选择账号密码,输入即可。
- 默认分值为master,在你的github上切一个test分支,并指定构建test分支
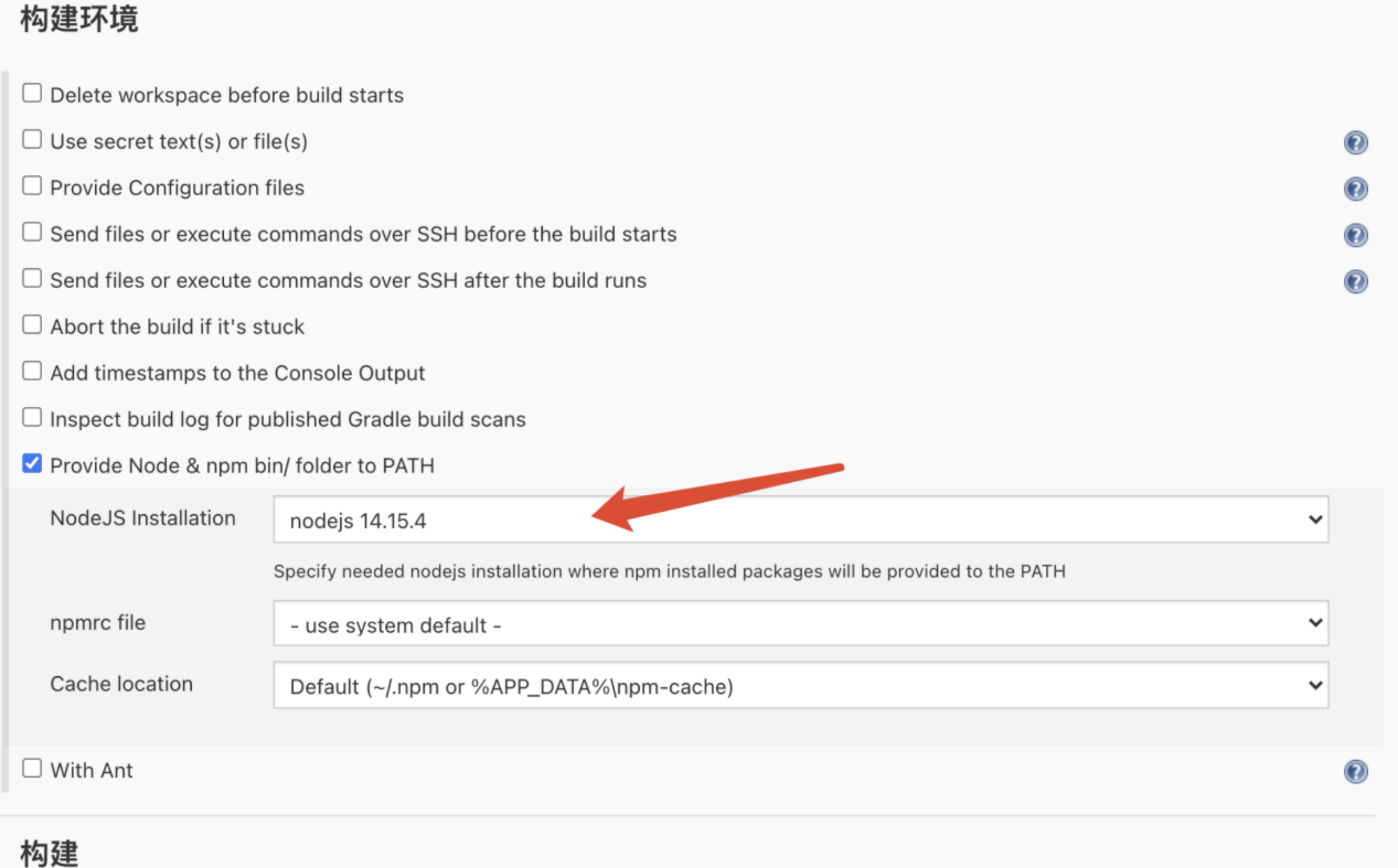
- 构建环境:选择nodejs,刚才在全局配置工具中配置的
- 执行shell 这里我用的是我目前简单构建用到的命令
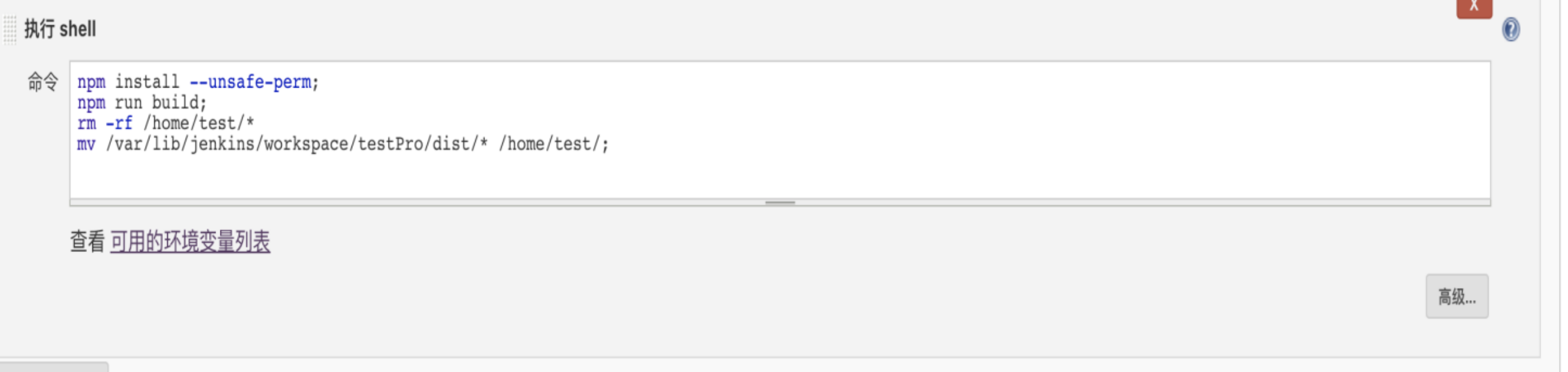
- npm install 后面多了一串命令 --unsafe-perm ,这里为什么用到这个我解释一下,这是我部署的时候发现的一个问题,我用npm install安装的时候,会构建失败提示我 npm无权限写入

- 我在服务器上查看了下读写权限,并全部改写了最高权限,发现还是不行,最后找到了问题: npm 出于安全考虑不支持以 root 用户运行,即使你用 root 用户身份运行了,npm 会自动转成一个叫 nobody 的用户来运行,而这个用户几乎没有任何权限。这样的话如果你脚本里有一些需要权限的操作,比如写文件(尤其是写 /root/.node-gyp),就会崩掉了。 为了避免这种情况,要么按照 npm 的规矩来,专门建一个用于运行 npm 的高权限用户;要么加 –unsafe-perm 参数,这样就不会切换到 nobody 上,运行时是哪个用户就是哪个用户,即使是 root。 经常是安装node-sass的时候会很容易出现因为权限不够无法创建目录的问题

- 这里我也是经历了数次的构建失败:
- 好了shell这一块填写完后 你可以再加一个ls 列出目录简单的测试下 你构建后的结果,这个时候我们就要回到标题自动化了,现在就加上自动化构建,即检测到代码push,jenkins自动构建项目。
- 首先我们去GitHub找到当前项目的
Settings->Webhooks->Add webhook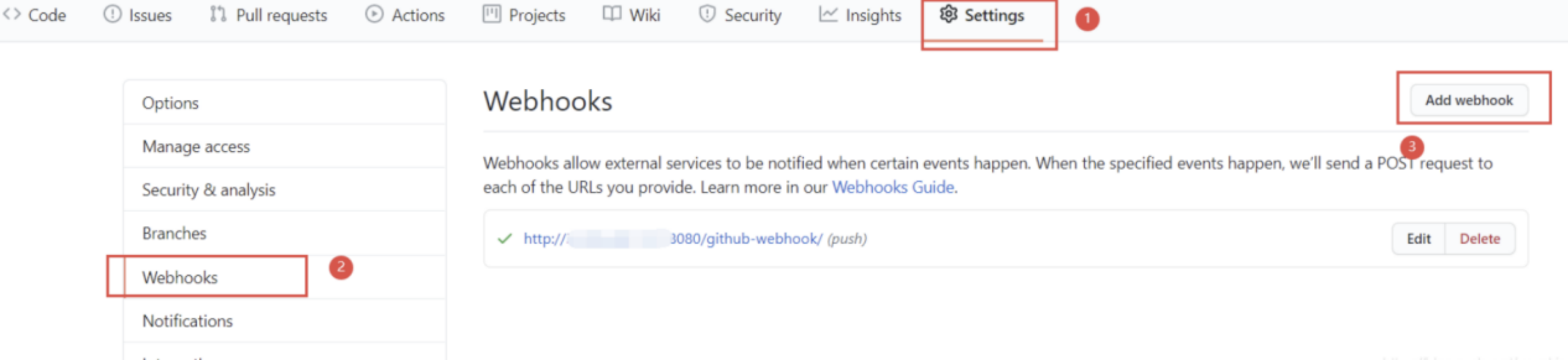
- 输入的url为,其中/github-webhook/是固定的
http://你的ip地址:8080/github-webhook/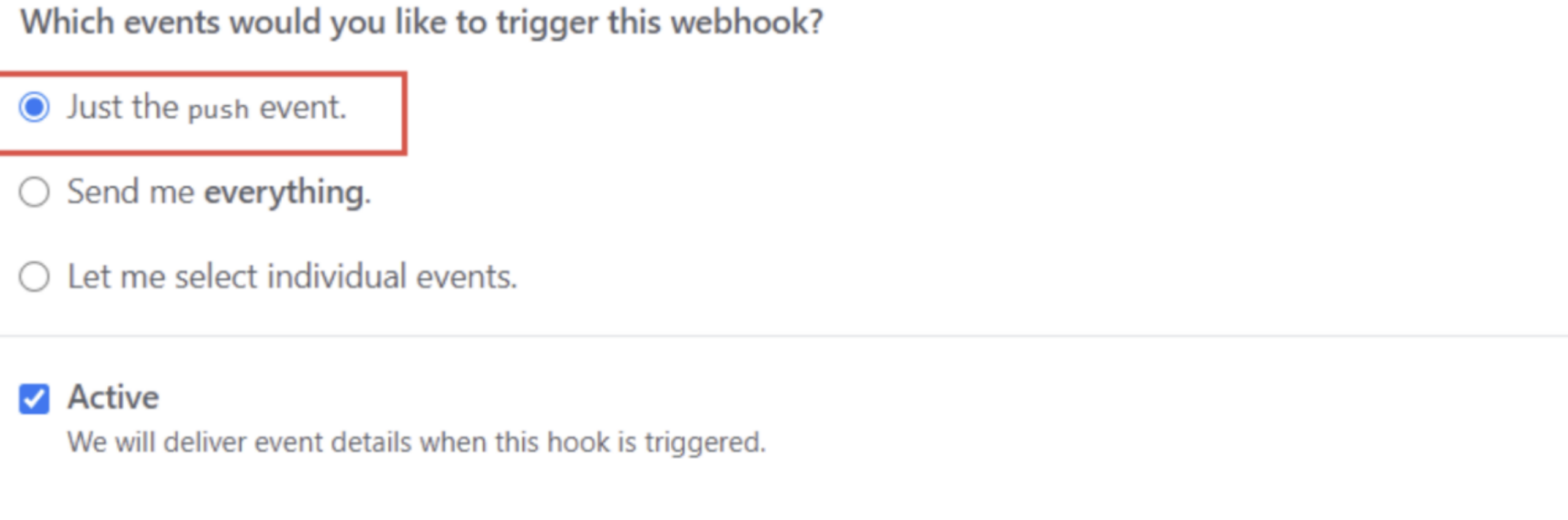
- 点击确定后返回jenkins找到刚才的任务,点击配置
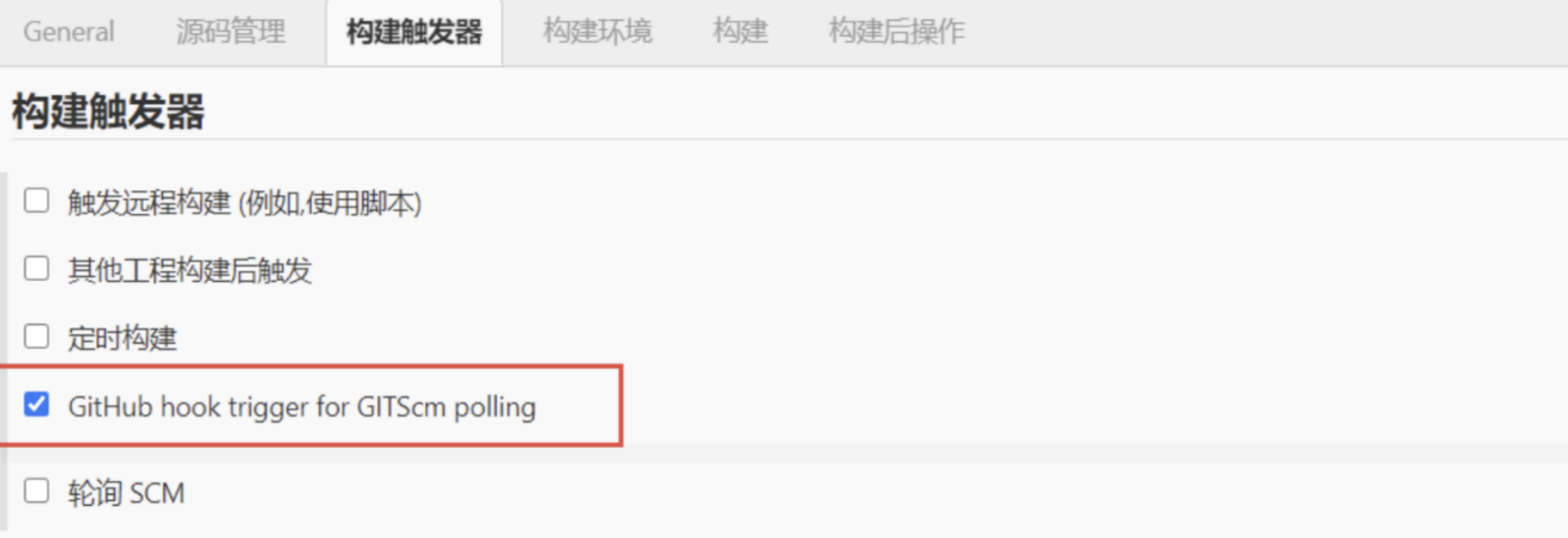
- 勾选之后修改shell命令,意思为打包后把dist文件夹移动到 /root/testweb/目录下,并更名为 jenkinsPro
npm run build;mv dist /home/web/jenkinsPro- 至此可以构建一下,成功后查看代码是否构建至指定目录,这时候再配合nginx,就完全可以实现我们的自动化构建了
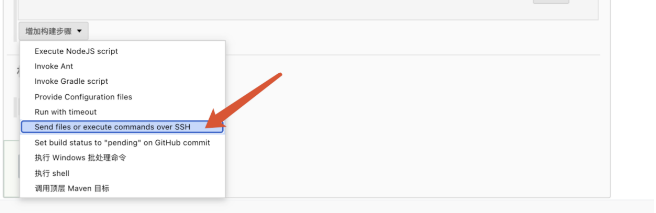
以上的操作仅仅是在jenkins所在服务器构建我们代码,接下来就是如何构建代码至其他服务器上面去,首先给我们的jenkins安装两个插件: publish over ssh 用于连接远程服务器 Deploy to container 用于把打包的应用发布到远程服务器 还是一样的打开插件管理,可选插件,搜索对应插件安装,这个插件有很多,实现的方式也不同,例如公司的jenkis使用的是ssh remote的一个插件。这里的话我采用我比较习惯的方式来演示。
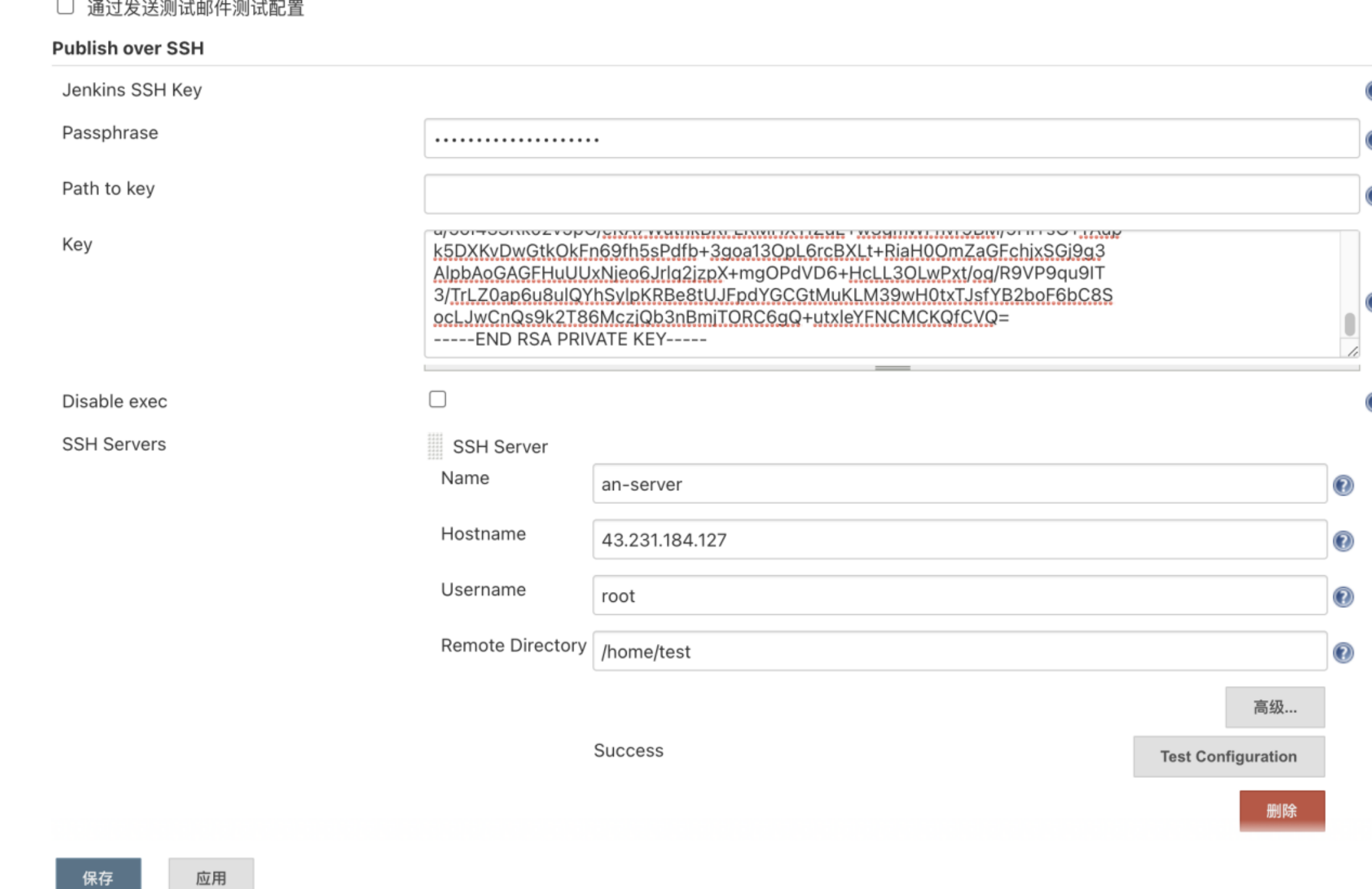
- 安装好以后还是老规矩去我们的系统管理配置下拉,找到publish over ssh
-
Jenkins SSH Key:jenkins服务器ssh秘钥
-
查看服务器是否存在ssh秘钥文件:
ll ~/.ssh如果服务器已经生成过ssh秘钥文件,目录下会有:id_rsa.pub、id_rsa文件。 如果不存在ssh秘钥文件,使用下面命令生成即可
ssh-keygen -t rsa -C "username". //# username一般设置为你的邮箱地址-
查看公钥文件,复制内容添加至SSH Server服务器~/.ssh/authorized_keys文件中,这个地方是把jenkins服务器公钥要添加至你构建目标服务器的authorized_keys里
-
authorized_keys是什么呢?
我们需要本地机器ssh访问远程服务器时为了减少输入密码的步骤,基本上都会在本地机器生成ssh公钥, 然后将本地ssh公钥复制到远程服务器的.ssh/authorized_keys中,这样就可以免密登录了。( 服务器之间访问同理) 查看秘钥文件,复制内容至 Key 选项输入框 如果在添加ssh秘钥文件时设置了密码也需要配置Passphrase、Path to key选项 设置SSH Server服务器Name、Hostname、Username、Remote Directory 设置完成后点击:Test Configuration按钮,出现:Success表示设置成功 -
接下来去任务的配置修改我们的构建参数:
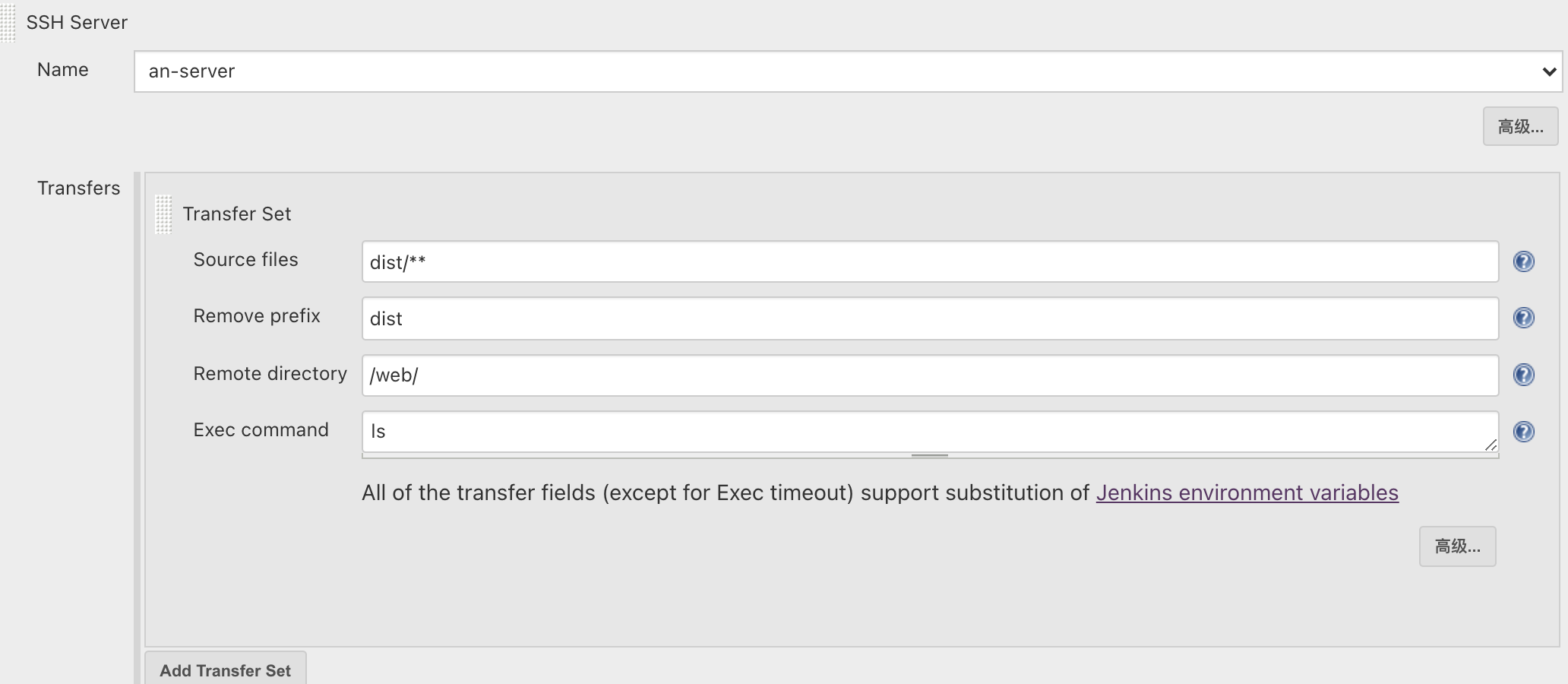
Name是我们之前在系统配置里服务器,自动带入的
Source files 项目构建后的目录 dist/** 匹配的是dist下所有文件包括文件夹
Remove prefix 去前缀 这里不填写的话 构建后扔过去的就是包含dist的完整文件夹
Remote directoty 测试发布的目录
Exec command 发布完执行的命令
- 保存以后,我们再次构建项目

- 输出成功以后,我们登陆目标服务器去查看下
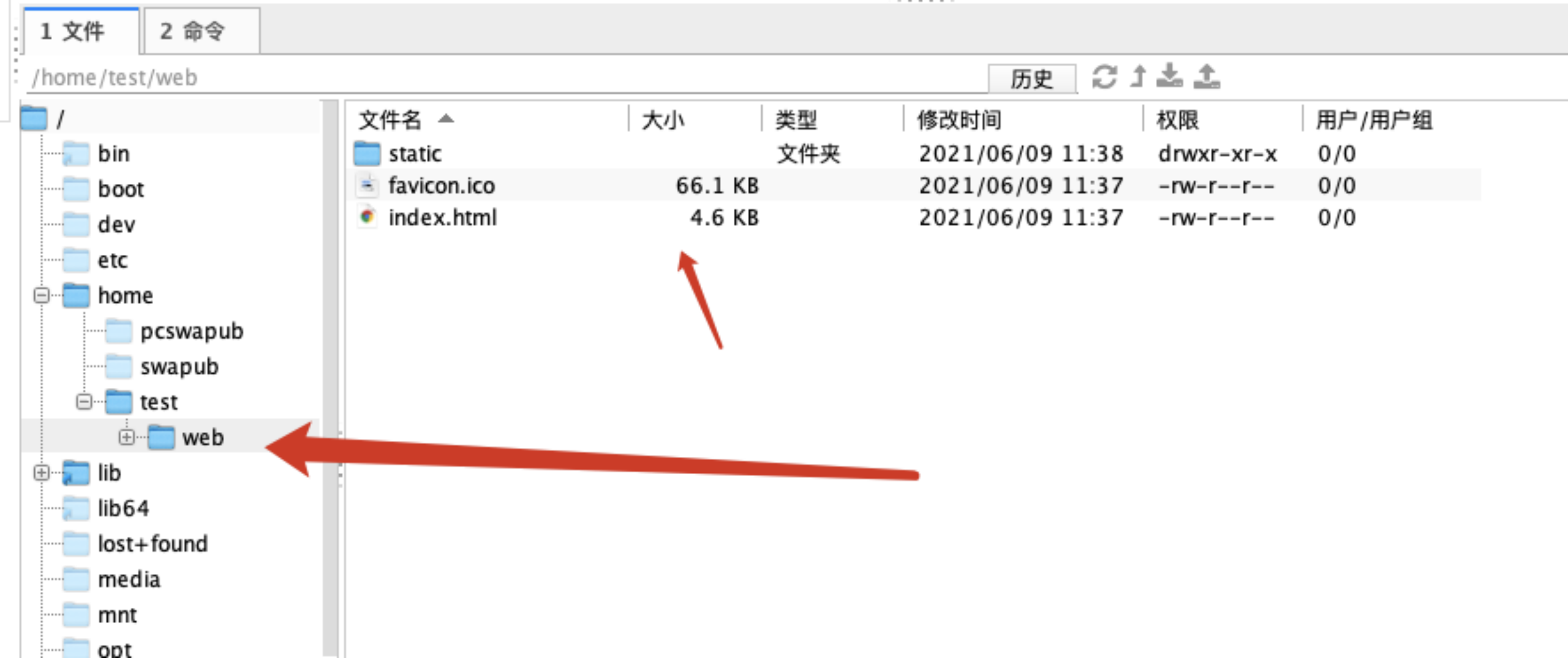
可以看到我们的代码成功构建到了这里。至此构建代码至其他服务器的一个流程也完成了。
现在我们每次提交代码至规定的分支,都会自动触发构建至我们的类似测试环境或者开发联调环境。
接下来就要配合nginx配合完成我们前端项目的部署了。
- Nginx 是一个高性能的HTTP和反向代理web服务器,何为反向代理,作为前端开发的同学还是有必要了解一下:
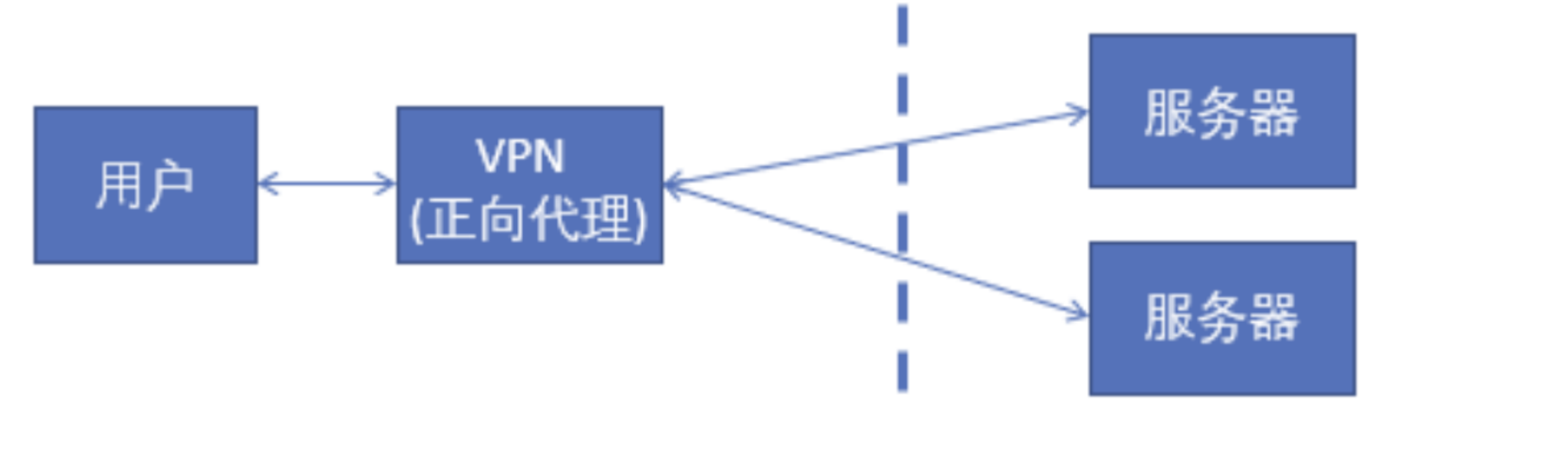
在客户端配置代理服务器,通过代理服务器进行互联网访问。代理对象是客户端,不知道服务端是谁。我们举个最直接的正向代理的例子,比如我们要访问国外的网站,速度很慢,甚至访问不到,这个时候我们就需要翻墙,使用vpn正向代理。并且vpn是在我们的用户端设置的(并不是在远端的服务器设置)。浏览器先访问vpn地址,vpn地址转发请求,并最后将请求结果原路返回来。
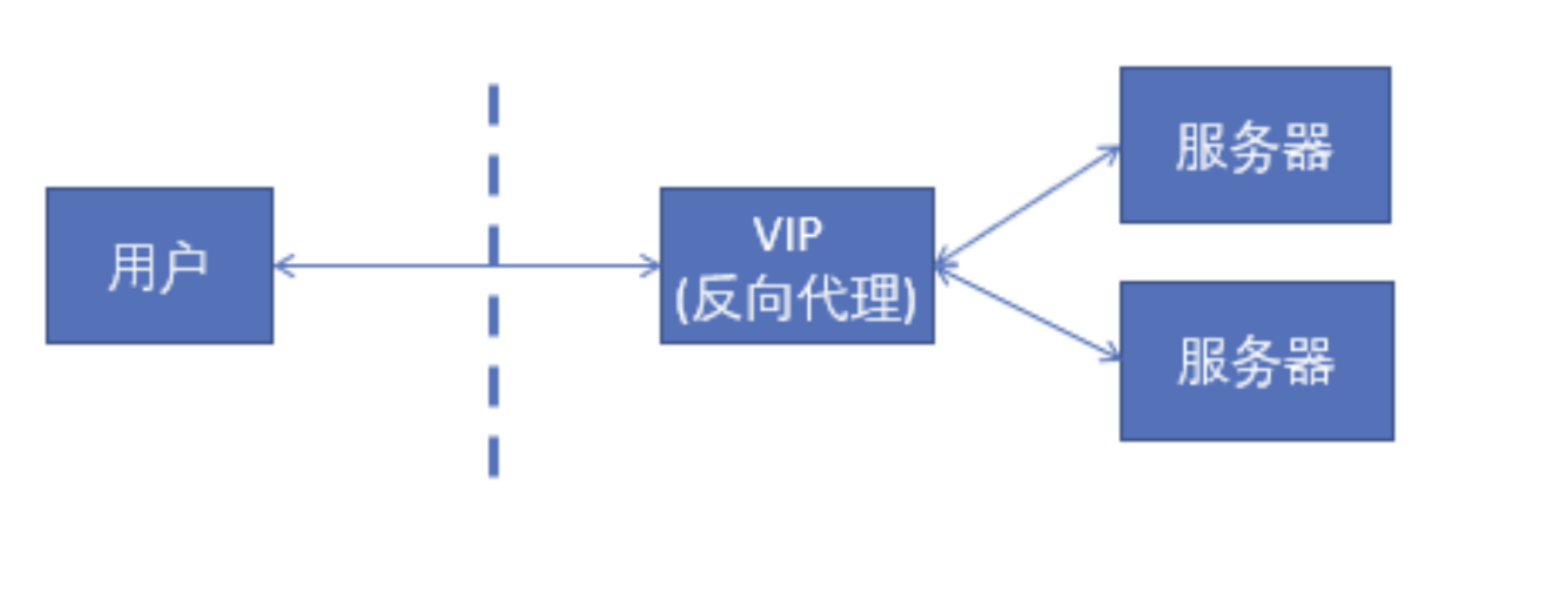
客户端不需要任何配置就能访问,只需要将请求发送到反向代理服务器,由反向代理服务器去选择目标服务器,获取数据后在返回给客户端。对外就一个服务器,暴露的是反向代理服务器地址,隐藏了真实服务器IP地址。代理对象是服务端,不知道客户端是谁。反向代理是作用在服务器端的,是一个虚拟ip(VIP)。对于用户的一个请求,会转发到多个后端处理器中的一台来处理该具体请求。

- /etc/nginx/nginx.conf 核心配置文件
- /etc/nginx/conf.d/default.conf 默认http服务器配置文件
- /etc/nginx/fastcgi_params fastcgi配置
- /etc/nginx/scgi_params scgi配置
- /etc/nginx/uwsgi_params uwsgi配置
- /etc/nginx/koi-utf
- /etc/nginx/koi-win
- /etc/nginx/win-utf 这三个文件是编码映射文件,因为作者是俄国人
- /etc/nginx/mime.types 设置HTTP协议的Content-Type与扩展名对应关系的文件
- /usr/lib/systemd/system/nginx-debug.service
- /usr/lib/systemd/system/nginx.service
- /etc/sysconfig/nginx
- /etc/sysconfig/nginx-debug 这四个文件是用来配置守护进程管理的
- /etc/nginx/modules 基本共享库和内核模块
- /usr/share/doc/nginx-1.18.0 帮助文档
- /usr/share/doc/nginx-1.18.0/COPYRIGHT 版权声明
- /usr/share/man/man8/nginx.8.gz 手册
- /var/cache/nginx Nginx的缓存目录
- /var/log/nginx Nginx的日志目录
- /usr/sbin/nginx 可执行命令
- /usr/sbin/nginx-debug 调试执行可执行命令
nginx的核心配置文件nginx.conf主要由3个部分组成:
#user nobody; #配置worker进程运行用户
worker_processes 1; #配置工作进程数目,根据硬件调整,通常等于CPU数量或者2倍于CPU数量
#error_log logs/error.log; # 配置全局错误日志及类型
events {
worker_connections 1024; #配置每个worker进程连接数上限,nginx支持的总连接数等于worker_connections*worker_processes
}http {
include mime.types;
default_type application/octet-stream;
client_max_body_size 100m;
sendfile on; #开启高效文件传输模式
#tcp_nopush on; #防止网络阻塞
keepalive_timeout 0;
gzip on; //启动
gzip_buffers 32 4K;
gzip_comp_level 6; //压缩级别,1-10,数字越大压缩的越好
gzip_min_length 100; //不压缩临界值,大于100的才压缩,一般不用改
gzip_types application/javascript text/css text/xml;
}-
client_max_body_size表示 客户端请求服务器最大允许大小,如果请求正文数据大于设定值,HTTP协议会报413错误Request Entity Too Large,如果需要上传大文件是需要修改这个值的。 关于这部分具体内容如果有兴趣的可以看这篇文献 -
keepalive_timeout:长连接超时时间,单位是秒,Nginx使用keepalive_timeout来指定KeepAlive的超时时间(timeout)。指定每个 TCP 连接最多可以保持多长时间。 Nginx 的默认值是 75 秒,有些浏览器最多只保持60秒,所以可以设定为60秒。若将它设置为 0,就禁止了 keepalive 连接。做好这些超时时间的限定, 判定超时后资源被释放,用来处理其他的请求,以此提升Nginx的性能 -
gzip:在不设置服务器gzip的情况下,我们访问网站
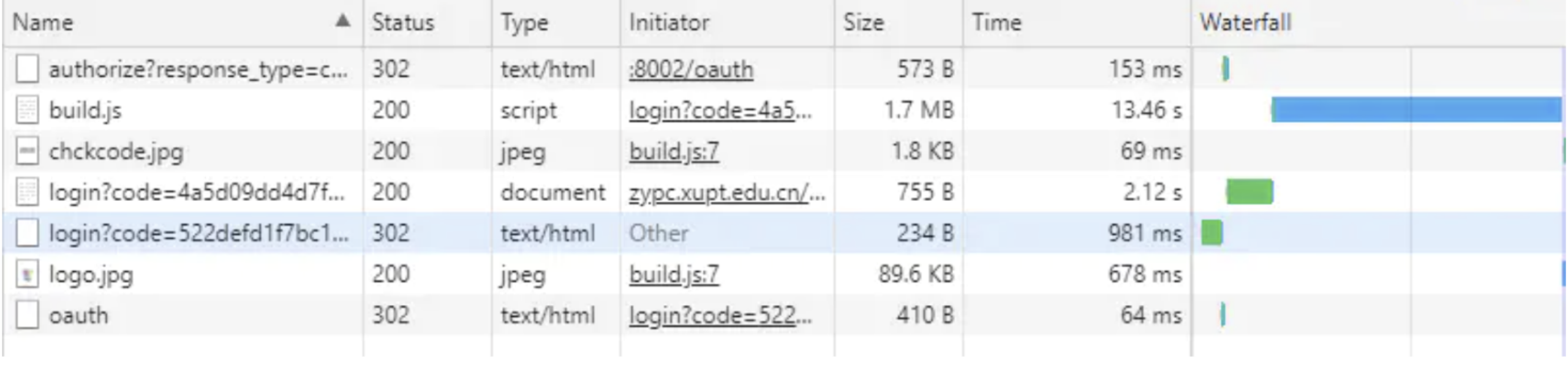
设置了gzip后访问情况如下
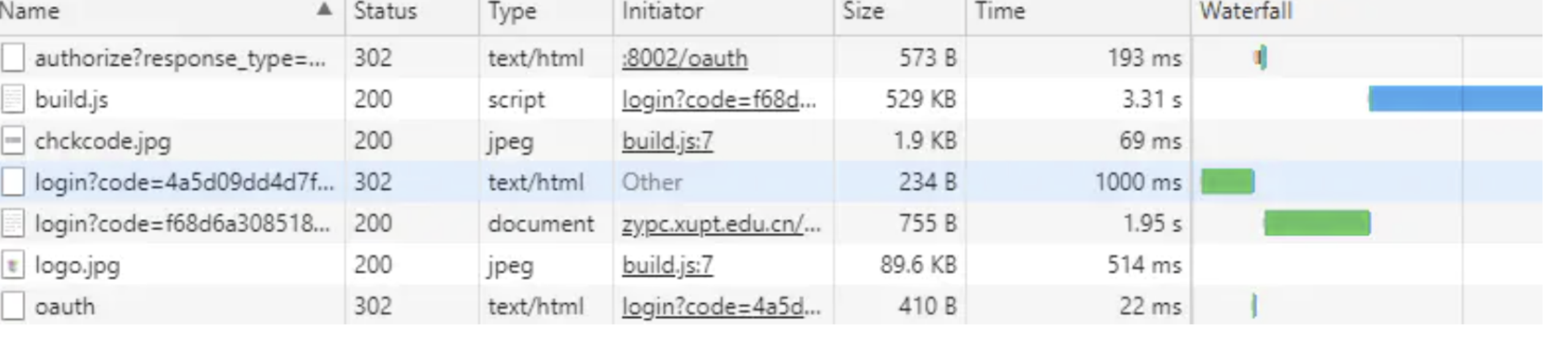
- 经过对比,我们发现,设置gzip之后,获取同样的数据。压缩之后的数据量大概是原始数据的1/4。同样的,获取数据的时间也大大降低。极大的优化了用户的体验。
server {
listen 80; #配置监听端口
server_name localhost; #配置服务名
root /home/test; #root根目录
##默认的匹配斜杠/的请求,当访问路径中有/,会被该localtion匹配到并进行处理
location / {
try_files $uri $uri/ /index.html;
}
location /api {
proxy_pass http:url; #接口的代理地址
}
error_page 404 /404.html;
#可显示自定义404页面内容,正常返回404状态码
error_page 404 = /404.htmml
#可显示自定义404页面内容,但返回200状态码。
}location / {
try_files $uri $uri/ /index.html;
}-
以上这段代码主要是为了解决vue项目history模式下刷新页面出现404的问题,目前web开发 使用一般前后端分离技术,并且前端负责路由。为了美观,会采用前端会采用history 模式的路由。但刷新页面时,前端真的会按照假路由去寻找文件。此时,必须返回index(index.html)文件才不至于返回404,如果没有使用该段代码,地址栏的#号依旧会消失,但是你无法通过直接输入路由地址直接进入到对应的页面。主要原因是路由的路径资源并不是一个真实的路径,所以无法找到具体的文件因此需要
rewrite到index.html中,然后交给路由在处理请求资源,try_files为文件匹配,先找真实的地址($uri),如果找不到,再找index.html文件 -
error_page在一次请求中只能响应一次,对应的Nginx有另外一个配置可以控制这个选项:recursive_error_pages默认为false,作用是控制error_page能否在一次请求中触发多次。
- proxy_pass配置中url末尾带/时,nginx转发时,会将原uri去除location匹配表达式后的内容拼接在proxy_pass中url之后。
测试地址:http://43.231.184.127/test/api
场景一:
location ^~ /test/ {
proxy_pass http://stageclub.swapub.com/server/;
}
代理后实际访问地址:http://stageclub.swapub.com/server/api
场景二:
location ^~ /test {
proxy_pass http://stageclub.swapub.com/server/;
}
代理后实际访问地址:http://stageclub.swapub.com/server//api
场景三:
location ^~ /test/ {
proxy_pass http://stageclub.swapub.com/;
}
代理后实际访问地址:http://stageclub.swapub.com/api
场景四:
location ^~ /test {
proxy_pass http://stageclub.swapub.com/;
}
代理后实际访问地址:http://stageclub.swapub.com//api- proxy_pass配置中url末尾不带/时,如url中不包含path,则直接将原uri拼接在proxy_pass中url之后;如url中包含path,则将原uri去除location匹配表达式后的内容拼接在proxy_pass中的url之后
测试地址:http://43.231.184.127/test/api
场景一:
location ^~ /test/{
proxy_pass http://stageclub.swapub.com/server;
}
代理后实际访问地址:http://stageclub.swapub.com/serverapi
场景二:
location ^~ /test {
proxy_pass http://stageclub.swapub.com/server;
}
代理后实际访问地址:http://stageclub.swapub.com/server/api
场景三:
location ^~ /test/ {
proxy_pass http://stageclub.swapub.com;
}
代理后实际访问地址:http://stageclub.swapub.com/test/api
场景四:
location ^~ /test {
proxy_pass http://stageclub.swapub.com;
}
代理后实际访问地址:http://stageclub.swapub.com/test/api- Nginx 的 location 实现了对请求的细分处理,有些 URI 返回静态内容,有些分发到后端服务器等,在这里我们也做一个梳理:
location 支持的语法 location [=|~|~*|^~] pattern { ... }server {
server_name web.com;
location = /anchnet {
[…]
}
}
http://web.com/anchnet匹配http://web.com/ANCHNET可能会匹配 ,也可以不匹配,取决于操作系统的文件系统是否大小写敏感(case-sensitive)。ps: Mac 默认是大小写不敏感的,git 使用会有大坑。http://web.com/anchnet?param1¶m2匹配,忽略 querystringhttp://web.com/anchnet/不匹配,带有结尾的/http://web.com/anchnete不匹配
server {
server_name web.com;
location ~ ^/anchnet$ {
[…]
}
}
http://web.com/anchnet匹配(完全匹配)http://web.com/ANCHNET不匹配,大小写敏感http://web.com/anchnet?param1¶m2匹配http://web.com/anchnet/不匹配,不能匹配正则表达式http://web.com/anchnete不匹配,不能匹配正则表达式
server {
server_name web.com;
location ~* ^/anchnet$ {
[…]
}
}http://web.com/anchnet匹配 (完全匹配)http://web.com/ANCHNET匹配 (大小写不敏感)http://web.com/anchnet?param1¶m2匹配http://web.com/anchnet/不匹配,不能匹配正则表达式http://web.com/anchnets不匹配,不能匹配正则表达式- 「^~」修饰符:前缀匹配 如果该 location 是最佳的匹配,那么对于匹配这个 location 的字符串, 该修饰符不再进行正则表达式检测。注意,这不是一个正则表达式匹配,它的目的是优先于正则表达式的匹配
当有多条 location 规则时,nginx 有一套比较复杂的规则,优先级如下:
- 精确匹配 =
- 前缀匹配 ^~(立刻停止后续的正则搜索)
- 按文件中顺序的正则匹配
或* - 匹配不带任何修饰的前缀匹配。
这个规则是这样的:
- 先精确匹配,没有则查找带有 ^~的前缀匹配,没有则进行正则匹配,最后才返回前缀匹配的结果(如果有的话)
rewrite模块即ngx_http_rewrite_module模块,主要功能是改写请求URI,是Nginx默认安装的模块。rewrite模块会根据PCRE正则匹配重写URI,然后发起内部跳转再匹配location rewrite指令所执行的顺序如下:
- 首先在server上下文中依照顺序执行rewrite模块指令;
- 如果server中行了rewrite重写,那么以新URI发起内部跳转,直接匹配location,不会再执行server里的rewrite指令
- 新URI直接匹配location
- 如果匹配上某个location,那么其中的rewrite模块指令同样依照顺序执行
- 如果再次导致URI的rewrite,那么再一次进行内部跳转去匹配location,但跳转的总次数不能超过10次
基本语法: rewrite regex replacement [flag]
上下文:server, location, if
regex是PCRE风格的,如果regex匹配URI,那么URI就会被替换成replacement,replacement 就是新的URI。如果rewrite同一个上下文中有多个这样的正则,匹配会依照rewrite指令出现的顺序先后依次进行下去,匹配到一个之后并不会终止,而是继续往下匹配,直到返回最后一个匹配上的为止。如果想要中止继续往下匹配,可以使用第三个参数flag。
如果新URI字符中有关于协议的任何东西,比如http://或者https://等,进一步的处理就终止了
-
flag 参数值:
- last:如果有last参数,那么停止处理任何rewrite相关的指令,立即用替换后的新URI开始下一轮的location匹配
server { listen 80; server_name web.com; location ^~ /anchnet { rewrite ^/anchnet/(.*) /test/$1 last; root /home/test; } location ^~ /test { return 200 "hello world"; } }#curl http://web.com/anchnet/index.html => http://web.com/test/index.html => hello worldurl由重写前的http://web.com/anchnet/index.html变为http://web.com/test/index.html,重新进行location匹配后,匹配到第二个location条件,所以请求url得到的响应是hello wold- break: 停止处理任何rewrite的相关指令。如果出现在location里面,那么所有后面的rewrite模块指令都不会再执行,也不发起内部重定向,而是直接用新的URI进一步处理请求。
server { listen 80; server_name web.com location ^~ /anchnet { rewrite ^/anchnet/(.*) /test/$1 break; root /home/test; } location ^~ /test { return 200 "hello world"; } }#curl -s http://web.com/anchnet/index.html => test#curl -s http://web.com/test/index.html => testurl由重写前的http://web.com/anchnet/index.html变为http://web.com/test/index.html,nginx按照重写后的url进行资源匹配,匹配到的资源文件是/home/test/index.html,所以请求url得到的响应就是/home/test/index.html文件中的内容:test。配置rewrite break时,请求不会跳出当前location,但资源匹配会按照重写后的url进行,如果location里面配置的是proxy_pass到后端,后端服务器收到的请求url也会是重写后的url。客户端的url不变。
last的break的相同点在于,立即停止执行所有当前上下文的rewrite模块指令;不同点在于last参数接着用新的URI马上搜寻新的location,而break不会搜寻新的location,直接用这个新的URI来处理请求,这样能避免重复rewite。因此,在server上下文中使用last,而在location上下文中使用break。 -
rewrite在实际开发中的示例:
location /club {
rewrite /club(.*) $1 break; # $1表示路径中正则表达式匹配的第一个参数
proxy_pass http://stageclub.swapub.com;
}curl 43.253.23.21:8080/club/mongodb/version #这里的/mongodb/version便是匹配到的$1
result-> http://stageclub.swapub.com/mongodb/version
- 当用户从移动端打开PC端的场景时,将自动跳转指移动端m.anchnet.com,本质上是Nginx可以通过内置变量$http_user_agent,获取到请求客户端的userAgent,从而知道当前用户当前终端是移动端还是PC,进而重定向到H5站还是PC站
server {
location / {
//移动、pc设备agent获取
if ($http_user_agent ~* '(Android|webOS|iPhone)') {
set $mobile_request '1';
}
if ($mobile_request = '1') {
rewrite ^.+ http://m.anchnet.com;
}
}
} server {
#ssl参数
listen 443 ssl; //监听443端口,因为443端口是https的默认端口。80为http的默认端口
server_name example.com;
#证书文件
ssl_certificate example.com.crt; #ssl证书的pem文件路径
#私钥文件
ssl_certificate_key example.com.key; #ssl证书的key文件路径
}- 几个单页应用同时需要部署在同一台电脑上,并且都需要占用80或者443端口,可以采用以下的方式
server {
listen 80;
root /root/test; #web服务器目录;
location ^~ /a/{
try_files $uri /a/index.html; #如果找不到文件,就返回 /toot/test/a/index.html
}
location ^~ /b/{
try_files $uri /b/index.html; #如果找不到文件,就返回 /toot/test/b/index.html
}
}- 额外拓展一下关于
Nginx中几个关于uri的变量
在nginx中有几个关于uri的变量,包括$uri $request_uri $document_uri,下面看一下他们的区别 :
$args #这个变量等于请求行中的参数。
$content_length #请求头中的Content-length字段。
$content_type #请求头中的Content-Type字段。
$document_root #当前请求在root指令中指定的值。
$host #请求主机头字段,否则为服务器名称。
$http_user_agent #客户端agent信息
$http_cookie #客户端cookie信息
$limit_rate #这个变量可以限制连接速率。
$request_body_file #客户端请求主体信息的临时文件名。
$request_method #客户端请求的动作,通常为GET或POST。
$remote_addr #客户端的IP地址。
$remote_port #客户端的端口。
$remote_user #已经经过Auth Basic Module验证的用户名。
$request_filename #当前请求的文件路径,由root或alias指令与URI请求生成。
$query_string #与$args相同。
$scheme #HTTP方法(如http,https)。
$server_protocol #请求使用的协议,通常是HTTP/1.0或HTTP/1.1。
$server_addr #服务器地址,在完成一次系统调用后可以确定这个值。
$server_name #服务器名称。
$server_port #请求到达服务器的端口号。
$request_uri #包含请求参数的原始URI,不包含主机名,如:”/foo/bar.php?arg=baz”。
$uri #不带请求参数的当前URI,$uri不包含主机名,如”/foo/bar.html”。
$document_uri #与$uri相同。