論文"DEEP ATTRACTOR NETWORK FOR SINGLE-MICROPHONE SPEAKER SEPARATION"( https://arxiv.org/pdf/1611.08930.pdf )の非公式実装 (Unofficial implementation of "DEEP ATTRACTOR NETWORK FOR SINGLE-MICROPHONE SPEAKER SEPARATION.")
上記の論文で実装されているモデルの実装、ESC-50を使ったモデル学習とその結果の評価。
2種類の環境音を混ぜて混合音声を作り、それをモデルに分離させてその分離音性能をGNSDR、GSAR、GSIRで測定した。
DANetディレクトリにはモデルの実装、学習、評価の際に実行したものをモジュールとしてまとめており、パッケージとして利用することが可能。
DANet.ipynbには実際にモデルの実装、学習、評価を行った結果を示す。
モデルの実装にはTensorflowとKerasを用いた。
DANet.ipynbのGoogle Colab上のリンクはこちら
Pytorchを用いた公式の実装はこちら
- Python 3.7.10
- TensorFlow 2.4.1
- museval 0.4.0
- SoundFile 0.10.3.post1
- pandas 1.1.5
- numpy 1.19.5
- scipy 1.4.1
- librosa 0.8.0
- matplotlib 3.2.2
論文での実験通りに行った。
まず、入力音声を8000Hzでリサンプリングし、window lengthを32ms、hop sizeを8ms、窓関数をハニング窓の平方根とした短時間フーリエ変換を行った。その後、絶対値を取ってから自然対数を取り、時間方向の次元数を100にしたものをモデルへの入力とした。
画像の引用元:
Zhuo Chen, Yi Luo, Nima Mesgarani, "DEEP ATTRACTOR NETWORK FOR SINGLE-MICROPHONE SPEAKER SEPARATION," arXiv preprint arXiv:1611.08930v2, 2017
https://arxiv.org/pdf/1611.08930.pdf
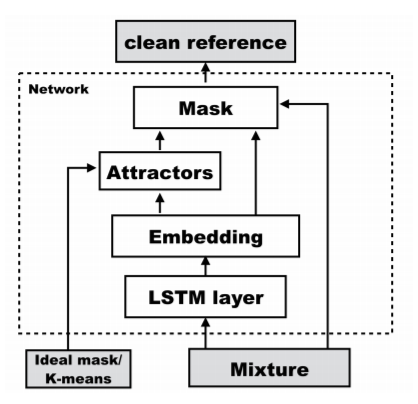
まず、入力音声を双方向LSTMに入力し、その結果を結合することで周波数方向の次元数を600にする。
そして全結合層に入力し、周波数方向の次元数を129(モデル入力時の周波数方向の要素数)×20(embedding空間の次元数)にし、Reshapeすることで周波数方向とembedding空間方向に分離する。
その後、訓練時には下の式によりAttractorを計算する。
Vは入力音声のEmbedding結果であり、Yはideal mask(各時刻、各周波数において、混合音声の中で振幅が一番大きい音声を1、そうでない音声を0としたもの)を表す。
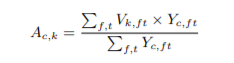
推論時にはVをkmeansクラスタリングし、そのときの中心点を用いることでAtractorを生成する。
また、AttractorとEmbedding結果を用いて下式のようにしてMaskを計算する。
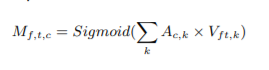
混合音声の分離が難しいような条件のときはSigmoid関数の代わりにSoftmax関数を用いることもでき、今回の実装でもSoftmax関数を用いた。
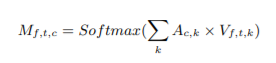
Maskを混合音声とかけることにより分離音声が生成され、モデルの出力となる。なお、推論時には混合音声として、短時間フーリエ変換した後に絶対値や対数を取っていない位相付きのスペクトログラムを用い、モデルの出力を逆短時間フーリエ変換することで音声波形に戻せるようにした。
また、損失は下の式(正解音声とモデルの出力との差の二乗和)をf(周波数方向の次元数)×t(時間方向の次元数)で割ったものを用いた。
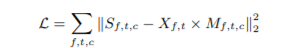
参考: https://library.naist.jp/mylimedio/dllimedio/showpdf2.cgi/DLPDFR009675_P1-57
推定音声をs^(t)とし、下のように正解音声s_target(t)、非正解音声e_interf(t)、ノイズe_artif(t)と分解する。
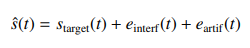
これらの値から、SDR、SIR、SARが下の式から計算される。
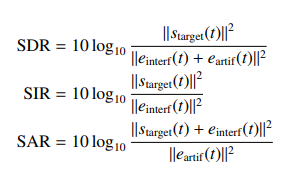
今回はmusevalというパッケージを用いてこれを計算した。
また、この計算における推定音声の部分を混合音声に変えてSDRに対応するものを計算し、SDRからその値を引いたものがNSDRとなる。
NSDR、SIR、SARの各平均をとったものがGNSDR、GSIR、GSARとなり、これが論文で使用されている分離音性能の評価の指標となる(数値が大きいほど性能が高い)。