

![]()
Why TrustLens · Visual Evidence · How It Works · Architecture & Evolution · Quickstart · Project WriteUp
Your model has 92% accuracy. It's still not safe for deployment.
Standard evaluation stops at accuracy. Accuracy measures what went right. TrustLens measures what can go wrong — in production, on underrepresented subgroups, and at high confidence.
You train a model. The test set reports 92% Accuracy and a 0.95 ROC-AUC. By all traditional metrics, it is ready to ship.
But behind those numbers, silent failures are lurking:
- Overconfidence: The model is "90% sure" about its predictions, but it's only right 60% of the time.
- Subgroup Collapse: The aggregate accuracy is 92%, but for a specific demographic, performance drops to 40%.
- Latent Bleed: In the embedding space, the model cannot distinguish between critical classes, leading to unpredictable edge-case behavior.
- Confidently Wrong: The model's most severe mistakes are made with >99% confidence, bypassing human-in-the-loop safety nets.
| Traditional Metrics | TrustLens Diagnostics | What It Tells You |
|---|---|---|
| Accuracy, F1, Precision | Calibration (ECE, Brier) | Does the model know when it's guessing? |
| Aggregate ROC-AUC | Fairness & Bias | Are minority groups experiencing higher failure rates? |
| Loss Curve | Latent Space Health | Are the internal embeddings stable and separated? |
| Manual Error Analysis | Failure Diagnostics | Are the errors concentrated at high confidence? |
| "Looks good to me" | Deployment Verdict | Is this model mathematically safe to deploy? |
TrustLens surfaces all these hidden risks with a single, statistically grounded audit, outputting a machine-readable deployment verdict.
TrustLens diagnostics are powered by visual evidence. We don't just give you a score; we show you exactly why a model is failing.
The Deployment Verdict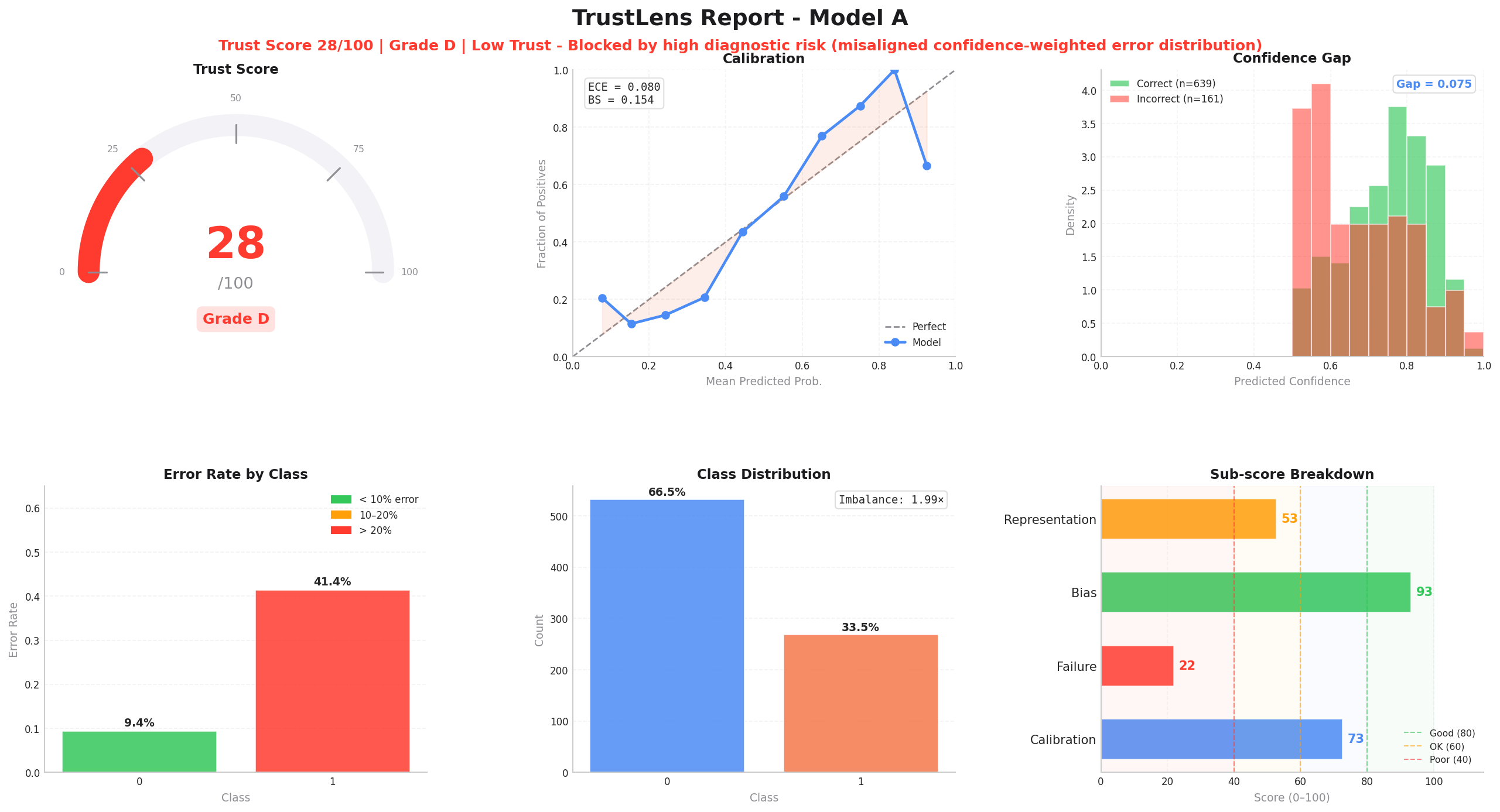
What it is: The composite Trust Score.
Why it matters: Gives a CI/CD-ready grade. Risk: Blocks shipping unsafe models. |
Calibration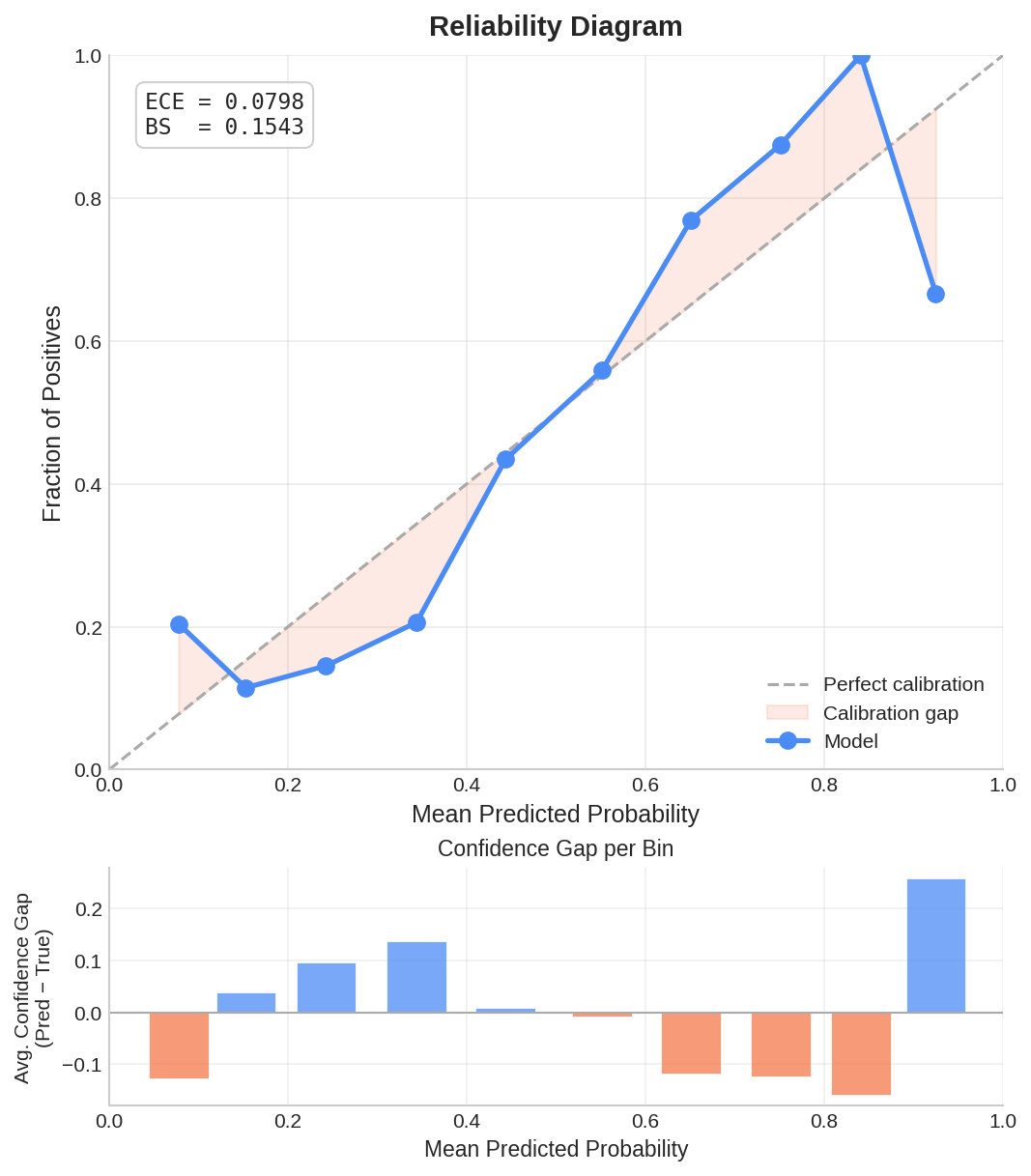
What it is: Reliability diagram.
Why it matters: Shows if the model is overconfident. Risk: High-confidence wrong answers. |
Subgroup Fairness Gaps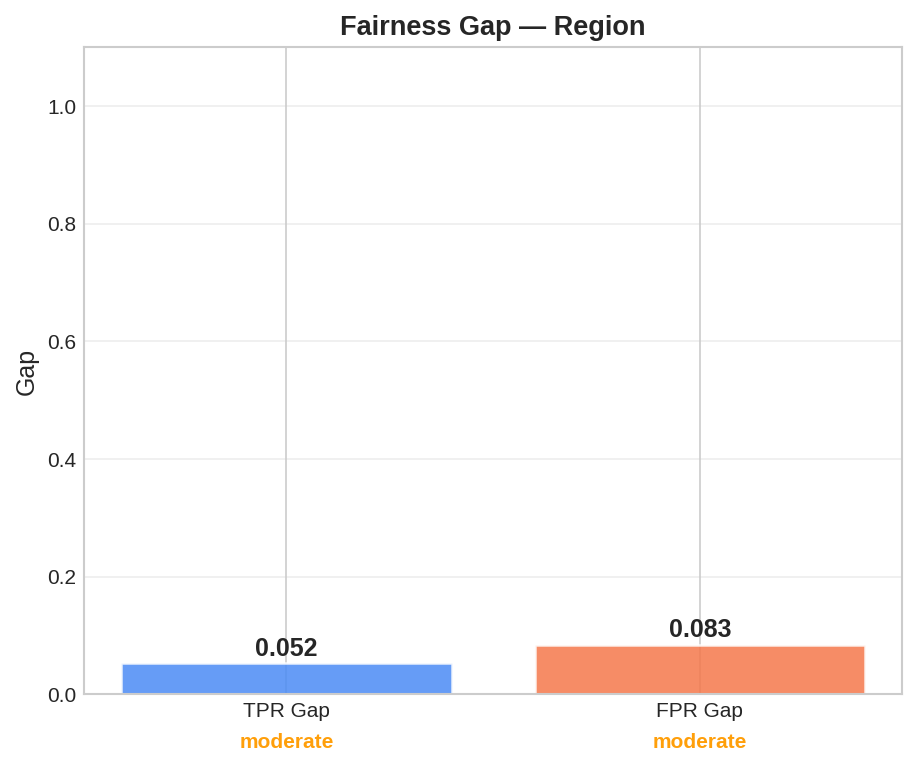
What it is: Error rates across demographics.
Why it matters: Uncovers hidden biases. Risk: Regulatory failure and harm. |
Latent Space Health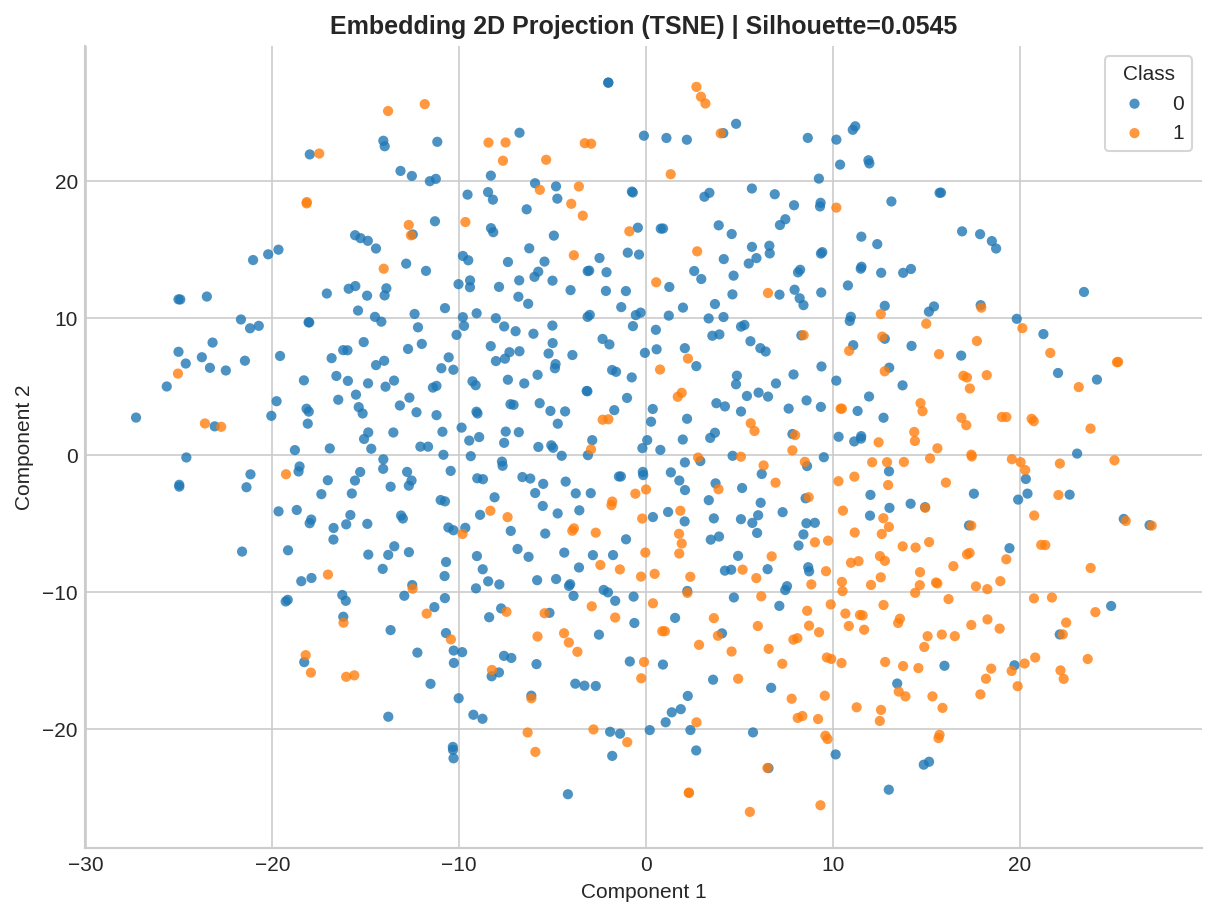
What it is: UMAP/t-SNE projection.
Why it matters: Visualizes class separability. Risk: Feature collapse and instability. |
Equalized Odds Violations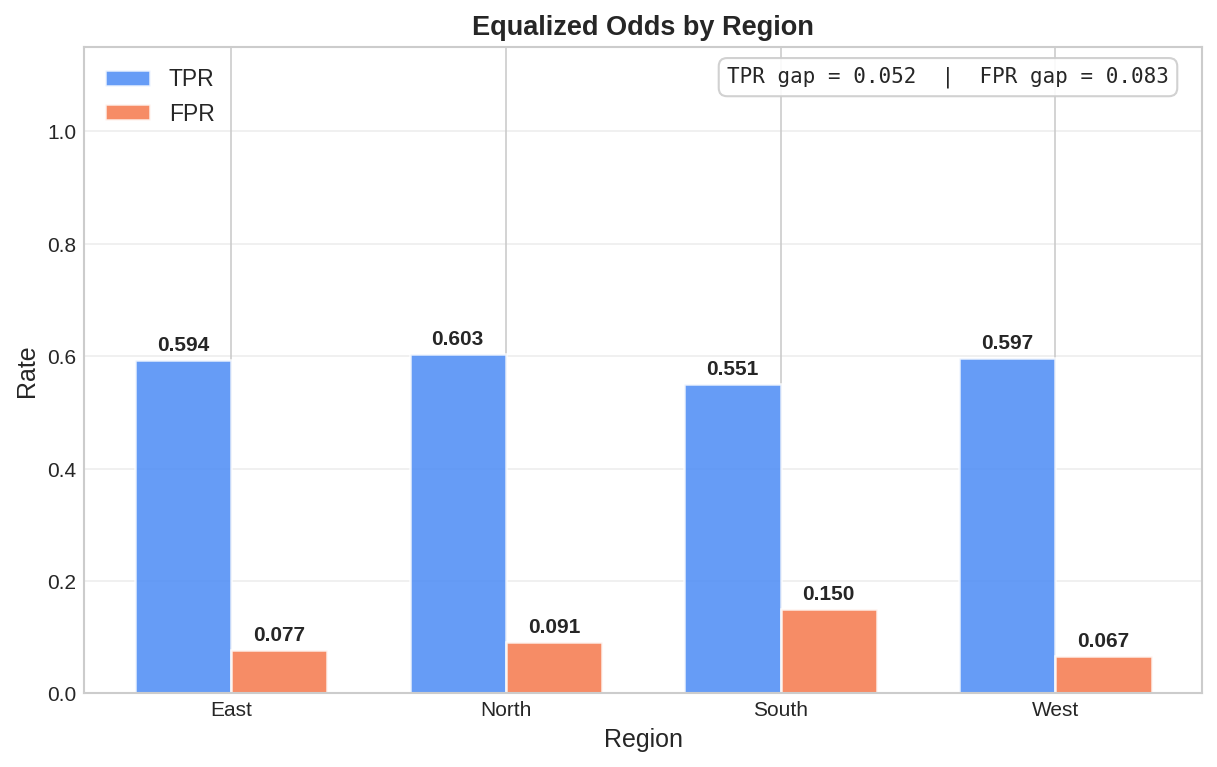
What it is: True vs False Positive Rates.
Why it matters: Ensures equitable outcomes. Risk: Systemic discrimination. |
Failure Analysis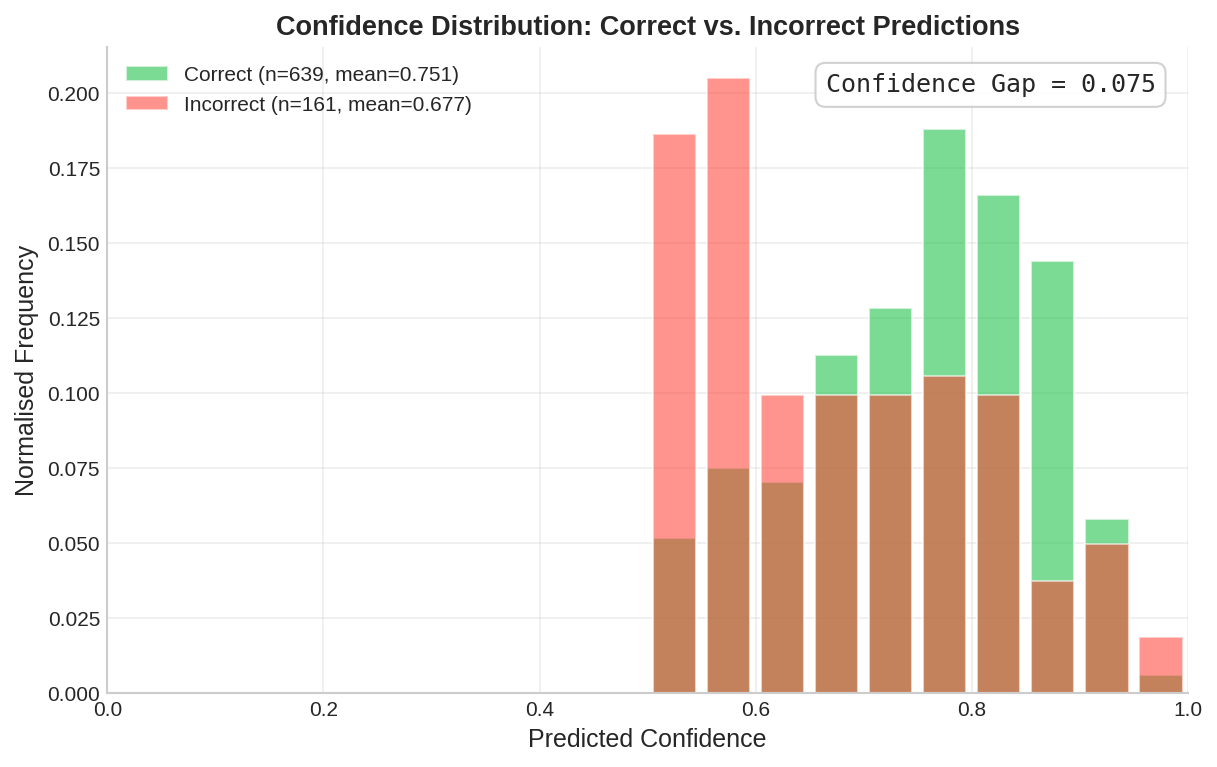
What it is: Confidence distribution of errors.
Why it matters: Spots systemic failure modes. Risk: Unpredictable production behavior. |
TrustLens evaluates your model through four distinct diagnostic modules, combining the findings into a Trust Score (0–100).
- Calibration Engine: Computes Expected Calibration Error (ECE) and Brier Score to detect confidence mismatch.
- Fairness Engine: Evaluates Equalized Odds and Subgroup Performance gaps across sensitive features.
- Representation Engine: Analyzes latent embedding separability (Silhouette, CKA) to ensure stable decision boundaries.
- Decision Engine: Synthesizes the risks into a penalty-based Trust Score and a
Ready/Blockeddeployment verdict.
You don't need to write boilerplate to extract probabilities. TrustLens features a Prediction Resolver Architecture that automatically detects your framework and standardizes the output.
We natively support:
- scikit-learn (
ClassifierMixinestimators) - XGBoost (
XGBClassifier,Booster) - LightGBM (
LGBMClassifier,Booster) - CatBoost (
CatBoostClassifier)
TrustLens is more than a visualization package—it is a statistically grounded diagnostic framework. We have systematically validated its behavior across 6 model architectures and multiple data corruption scenarios (noise, imbalance, bias).
Key Finding: TrustLens empirically decouples Accuracy from Trust, accurately flagging high-accuracy models that exhibit high reliability risks (the "Overconfidence Zone").
TrustLens is an actively evolving framework driven by robust engineering discussions and RFCs (Request for Comments). We treat evaluation as a first-class architectural problem.
Active Architectural Debates & Milestones:
- RFC #145: Regression Trust Score — Proposing the scoring framework for regression models.
- PR #147: Implements RFC #145 (Regression Trust Score) — Core engine execution for regression contexts.
- PR #102: Centralize plotting style — Unifying visual identity across the framework.
- PR #68: Fairness multi-feature support — Scaling bias detection across complex datasets.
The Evolution:
- v0.1: MVP — Core metrics and visualizations.
- v0.4: Framework-Agnostic Core — Native support for XGBoost, LightGBM, CatBoost.
- v0.5 (Current): Regression Support, Model Zoo Benchmark, Multiclass Calibration.
- v0.6: In Progress — Policy Profiles, TrustComparison, Deep Learning Backends.
- v1.0: Planned — CI/CD enterprise integration and Web Dashboards.
Install TrustLens (use [full] for extended plotting and framework support):
pip install trustlens
pip install trustlens[full]Run a one-line audit on a built-in dataset to see why high accuracy isn't the full story:
from trustlens import quick_analyze
quick_analyze(dataset="breast_cancer")Or run a comprehensive audit on your own model:
from trustlens import analyze
from xgboost import XGBClassifier
model = XGBClassifier().fit(X_train, y_train)
# TrustLens auto-detects the XGBoost model and extracts probabilities
report = analyze(
model=model,
X=X_test,
y_true=y_test,
sensitive_features={"gender": gender_test}
)
# Render the rich HTML dashboard or visual plots
report.show()
# Gate your CI/CD pipeline
report.save("trust_report/")The README is just the tip of the iceberg. Explore the full TrustLens documentation site for methodology, API references, and architectural deep-dives:
TrustLens is an open ecosystem. We welcome contributions—whether it's new diagnostic plugins, better visualizers, or core engine improvements.
→ Contributing Guide · Open an Issue
A massive thank you to our contributors:
@software{trustlens2026,
author = {Shahid Ul Islam},
title = {TrustLens: Audit ML models beyond accuracy},
year = {2026},
url = {https://github.com/Khanz9664/TrustLens}
}
Engineering Design © 2026 Shahid Ul Islam.
Built with passion for Mathematical Rigor and Technical Excellence.