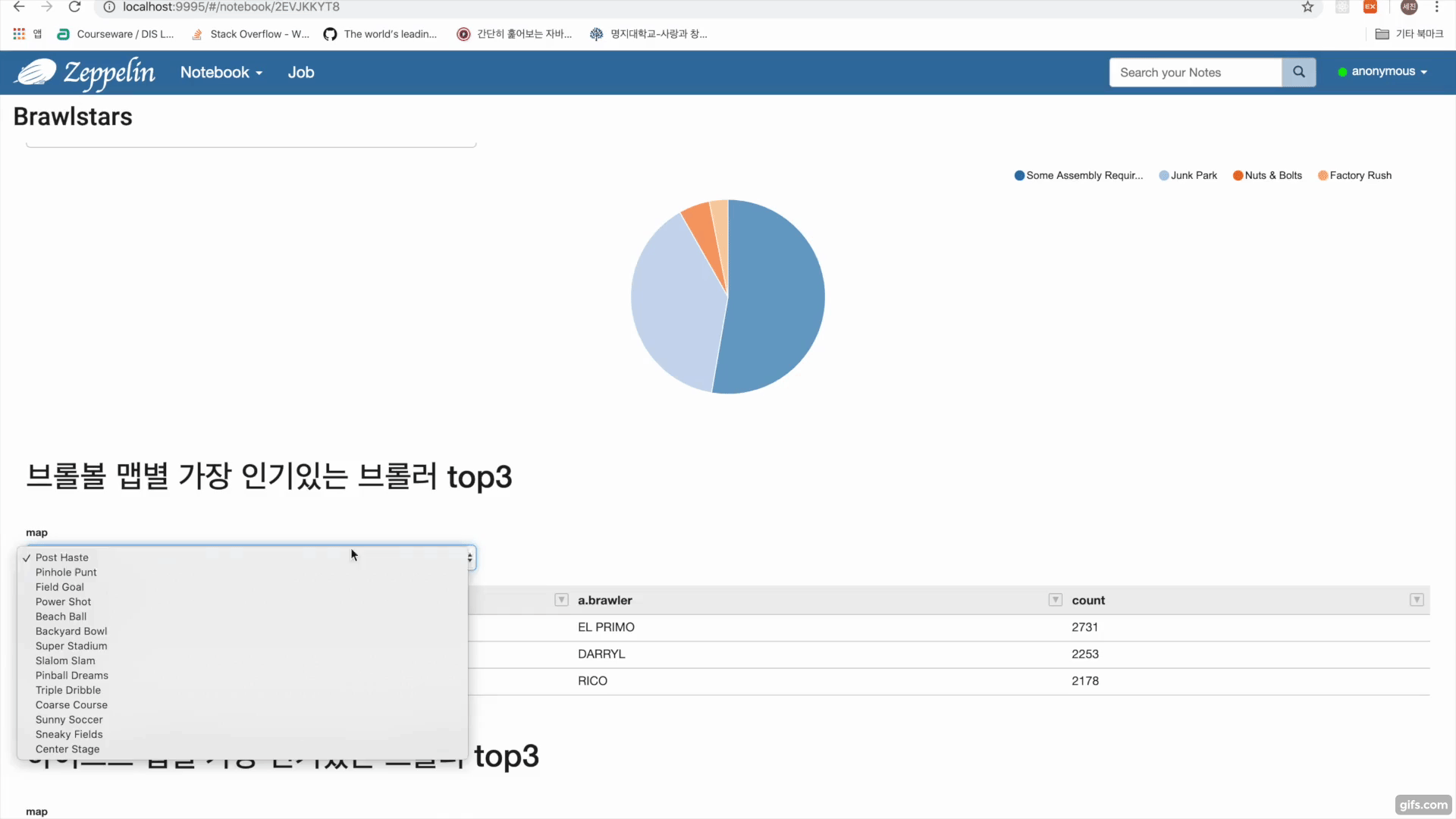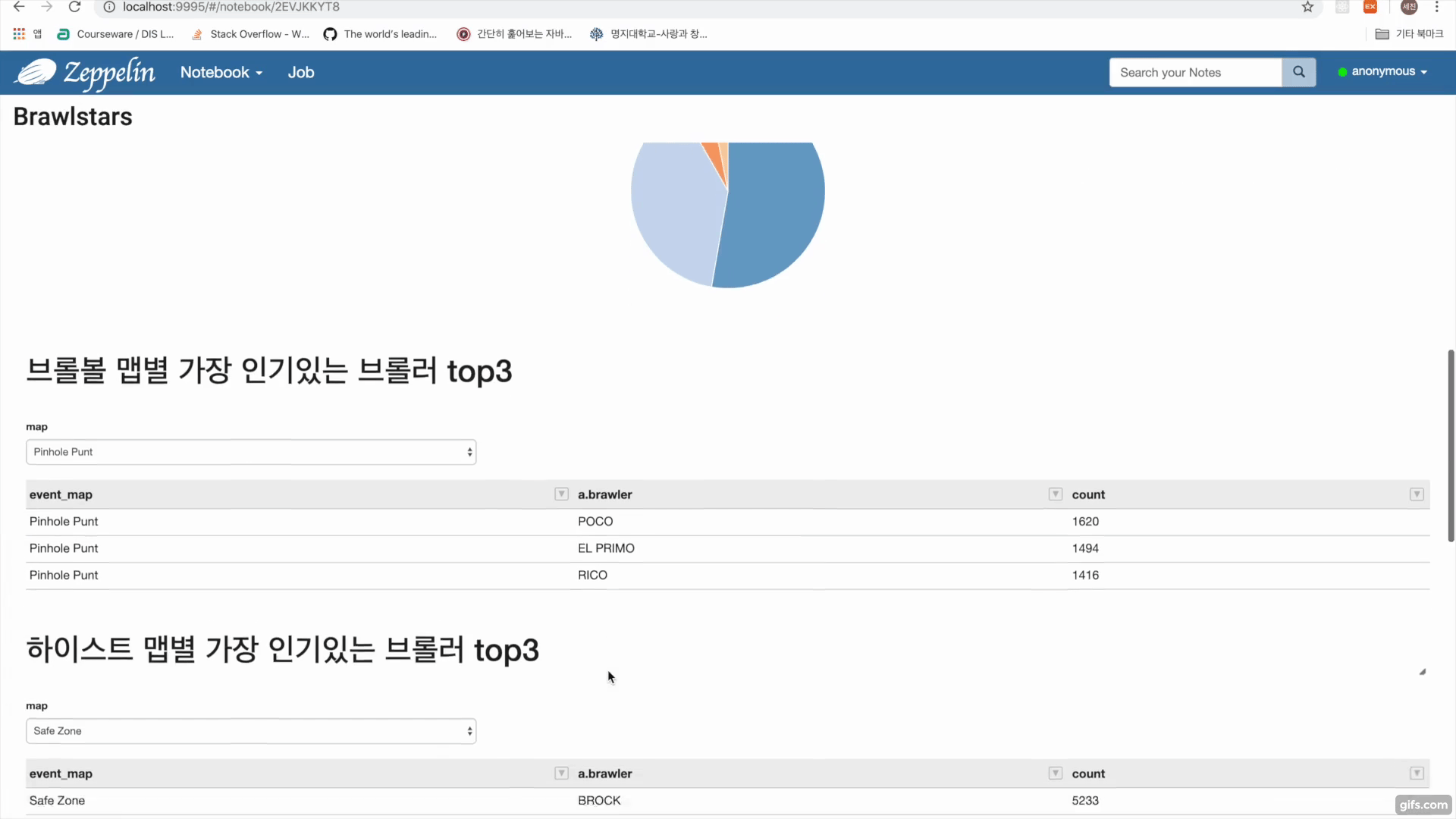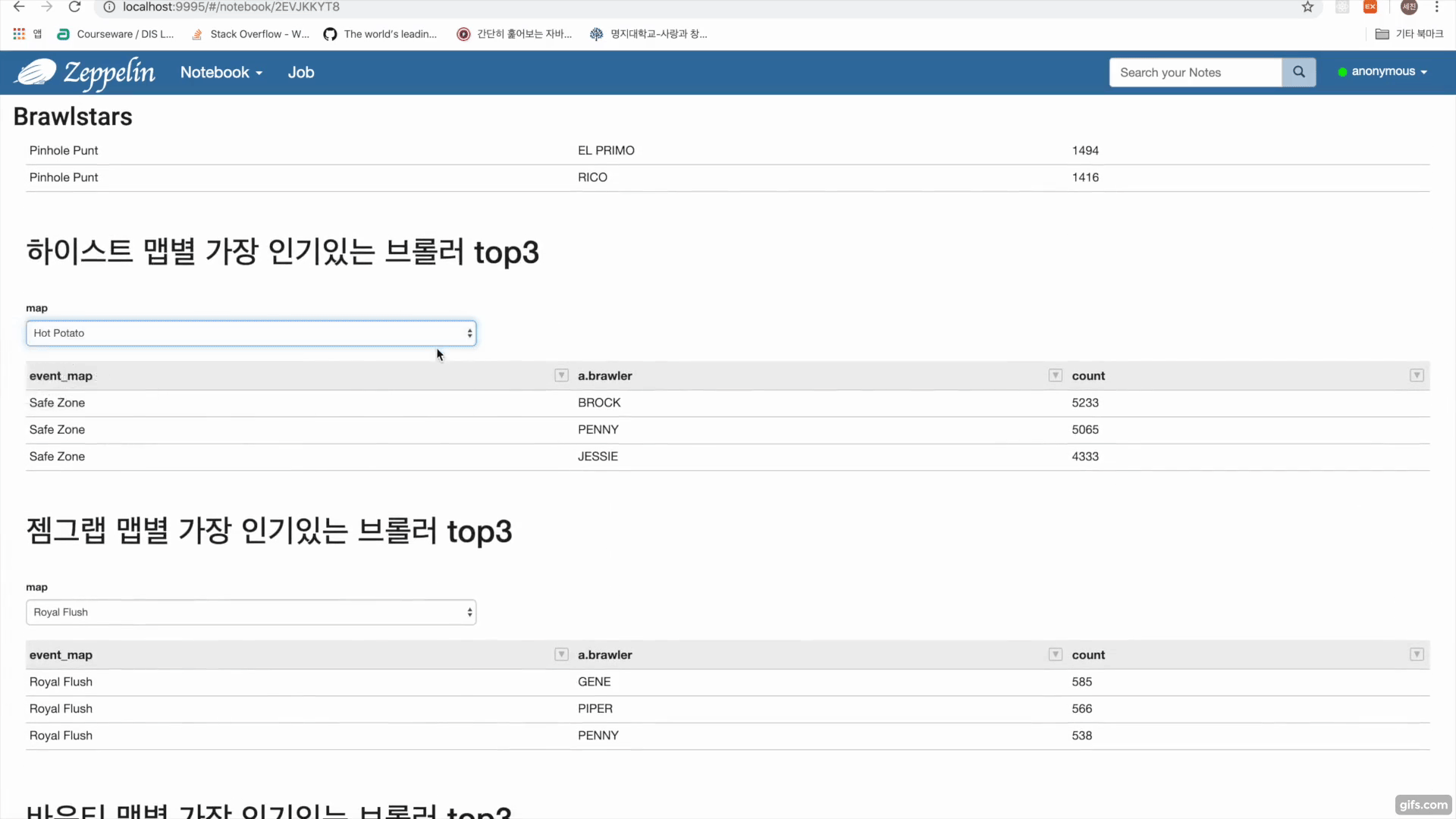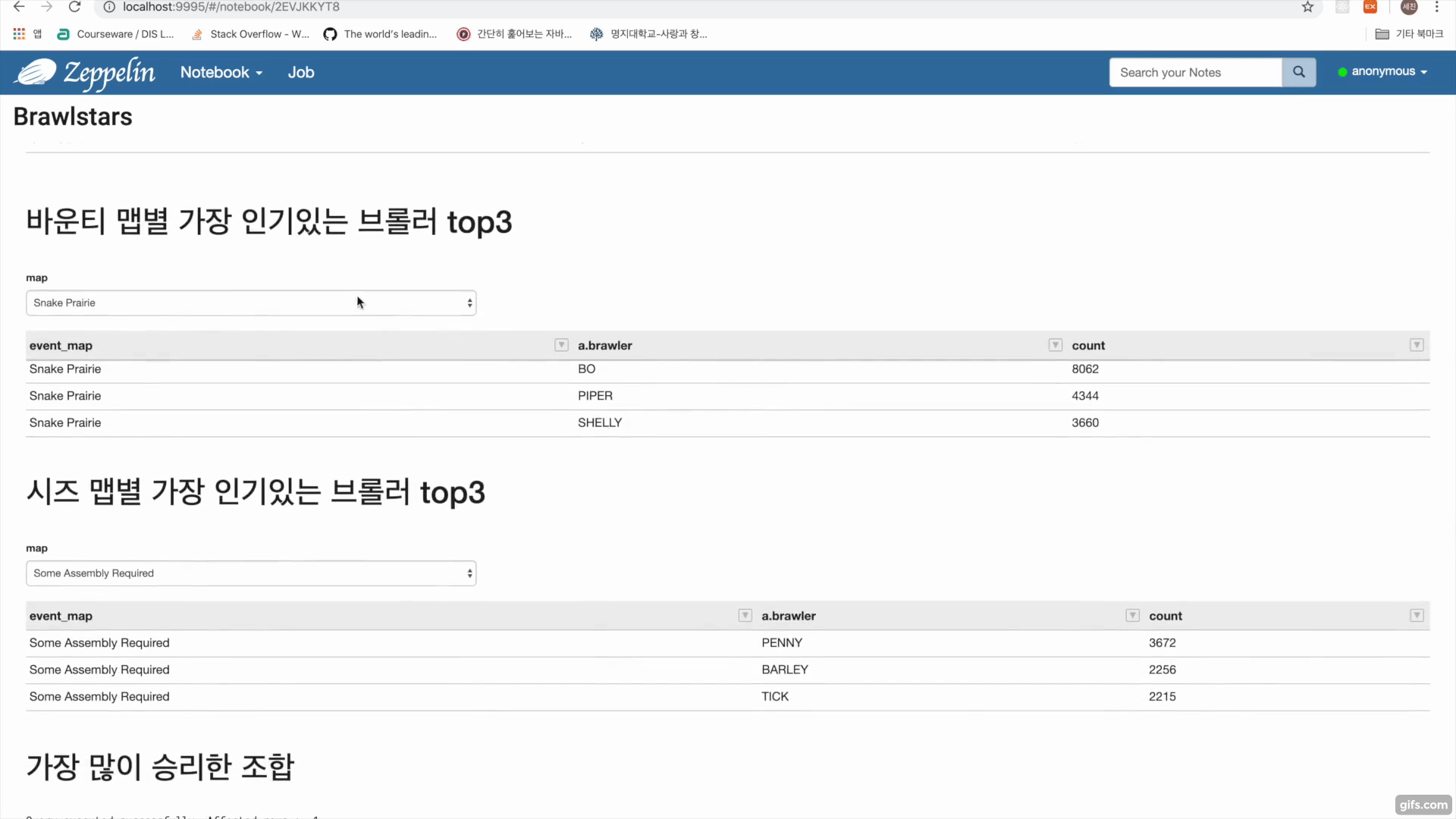
브롤스타즈 api를 이용한 데이터수집 https://developer.brawlstars.com/
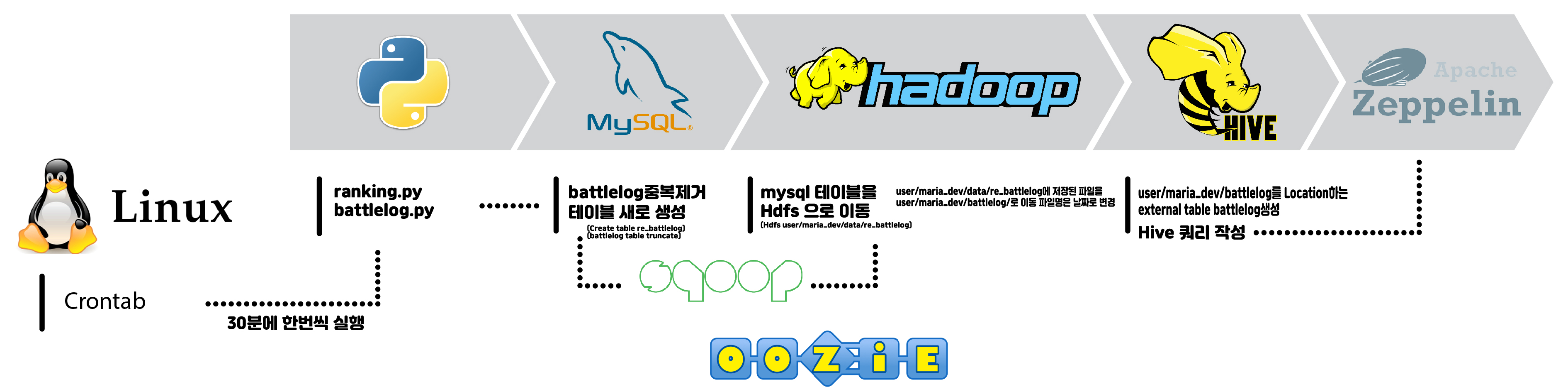
- 파이썬을 이용해 배틀로그 수집
- mysql테이블에 저장
- mysql의 데이터를 스쿱을 이용해 hdfs로 이동
- hdfs파일을 하이브 외부테이블이 참조하는 디렉토리로 이동
- 제플린에서 하이브를 이용해 데이터를 분석
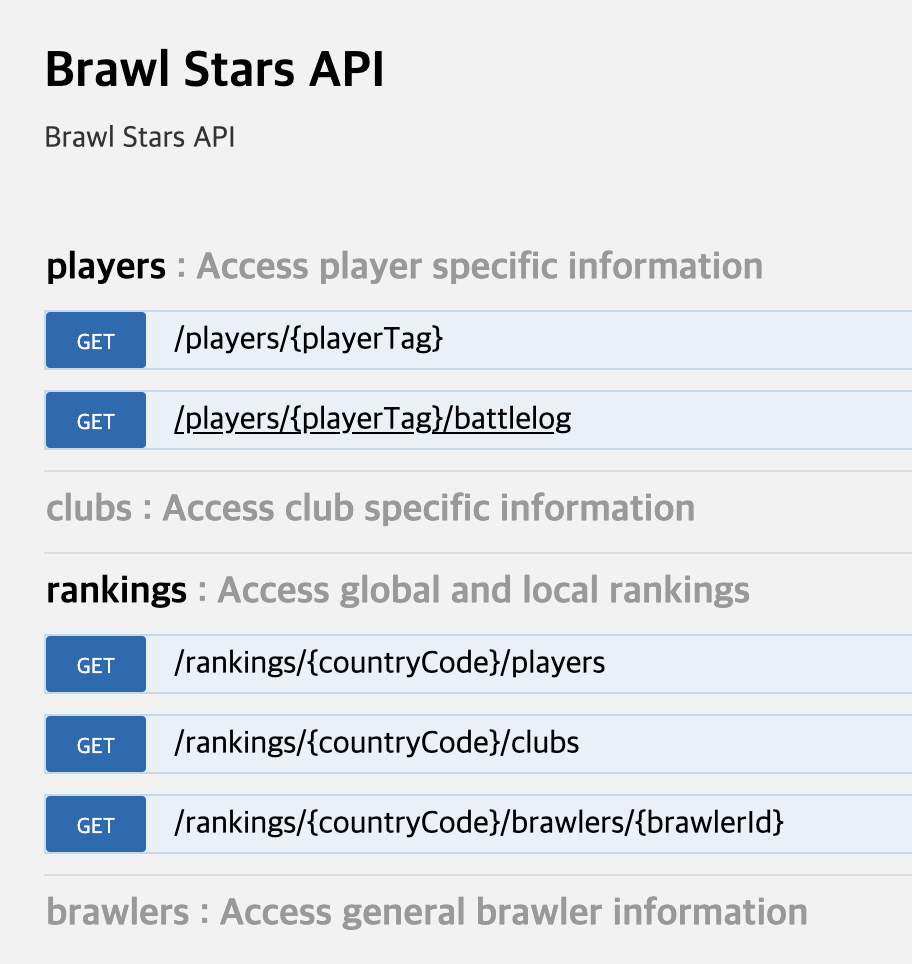
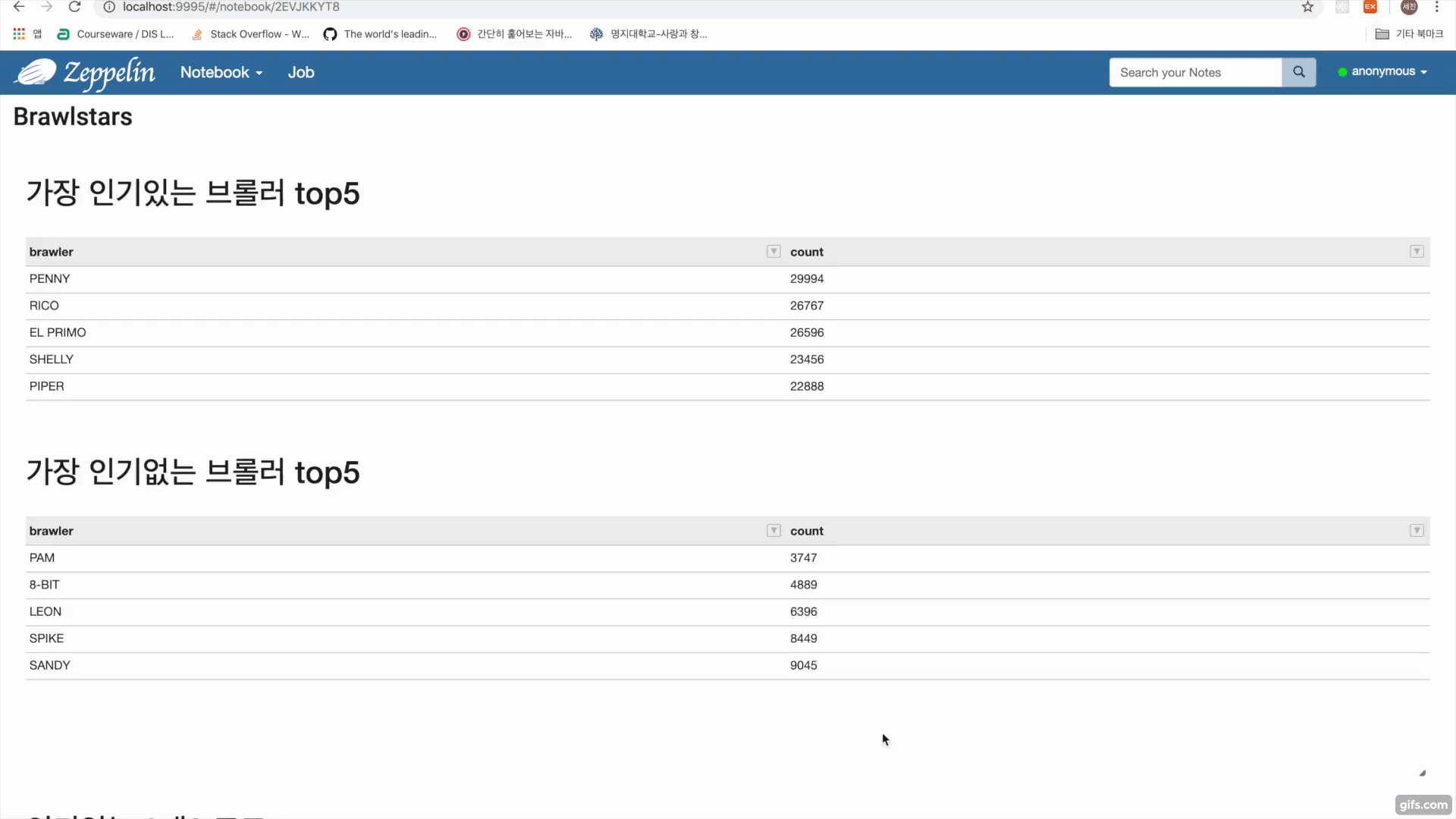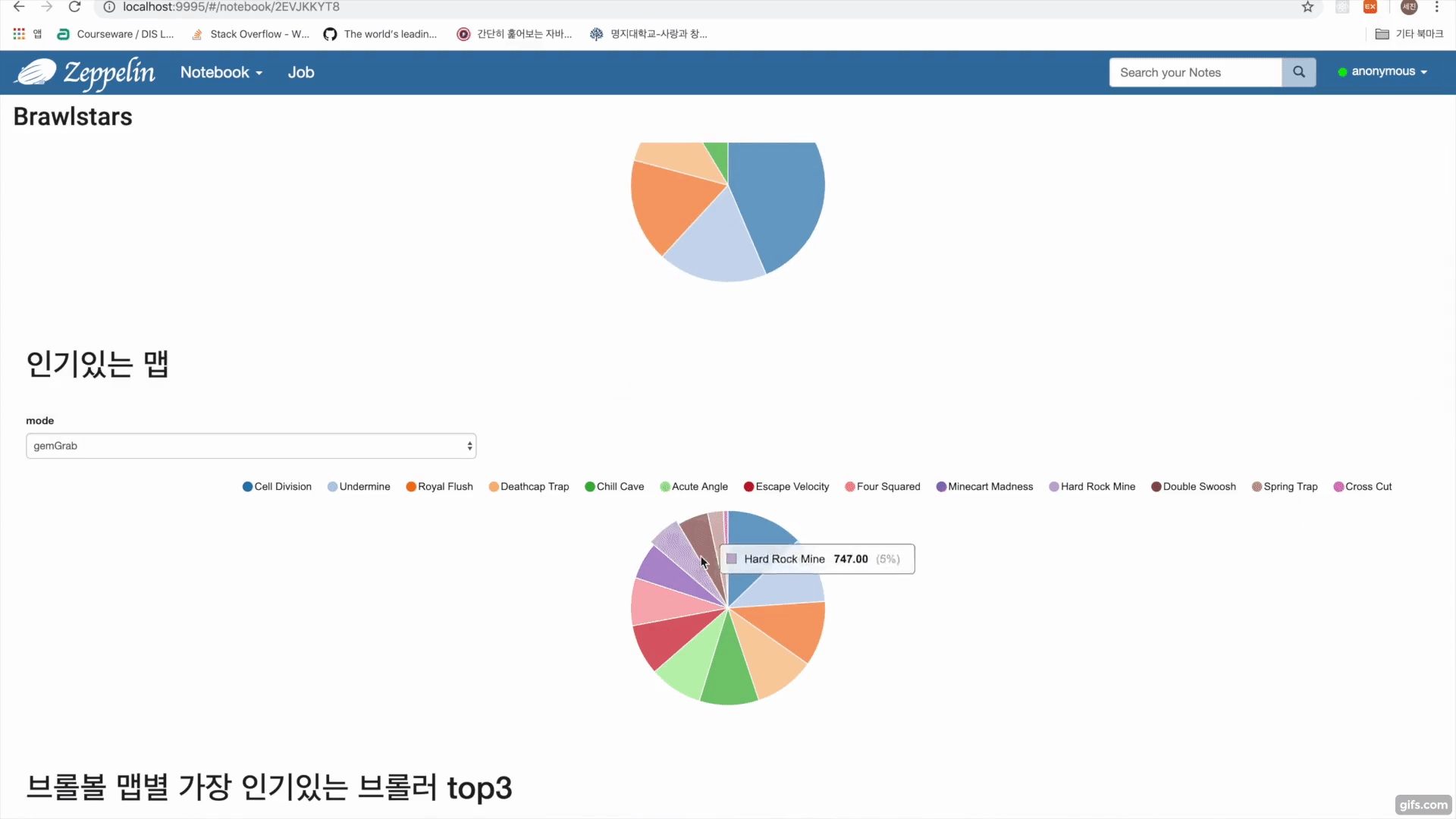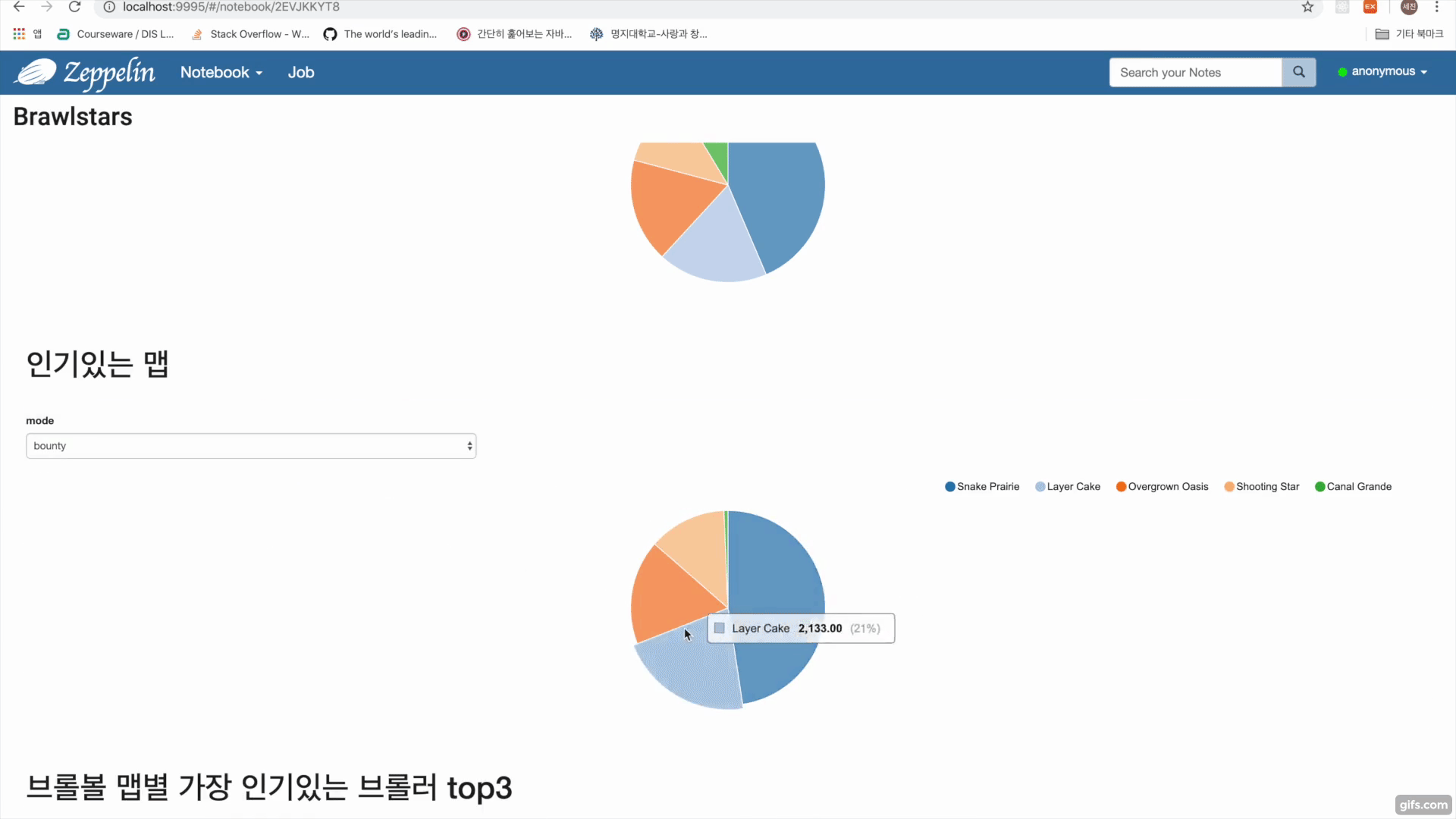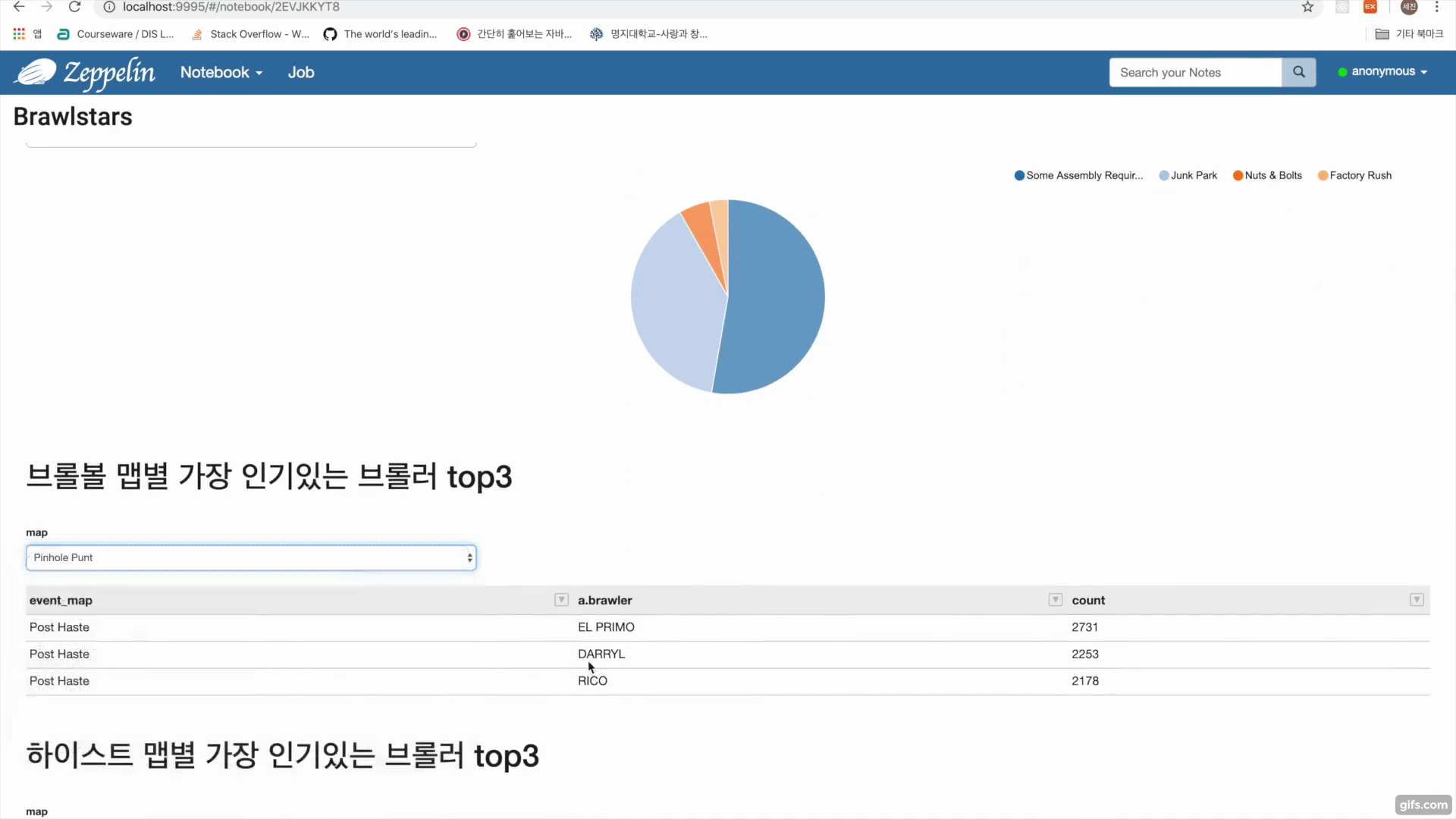
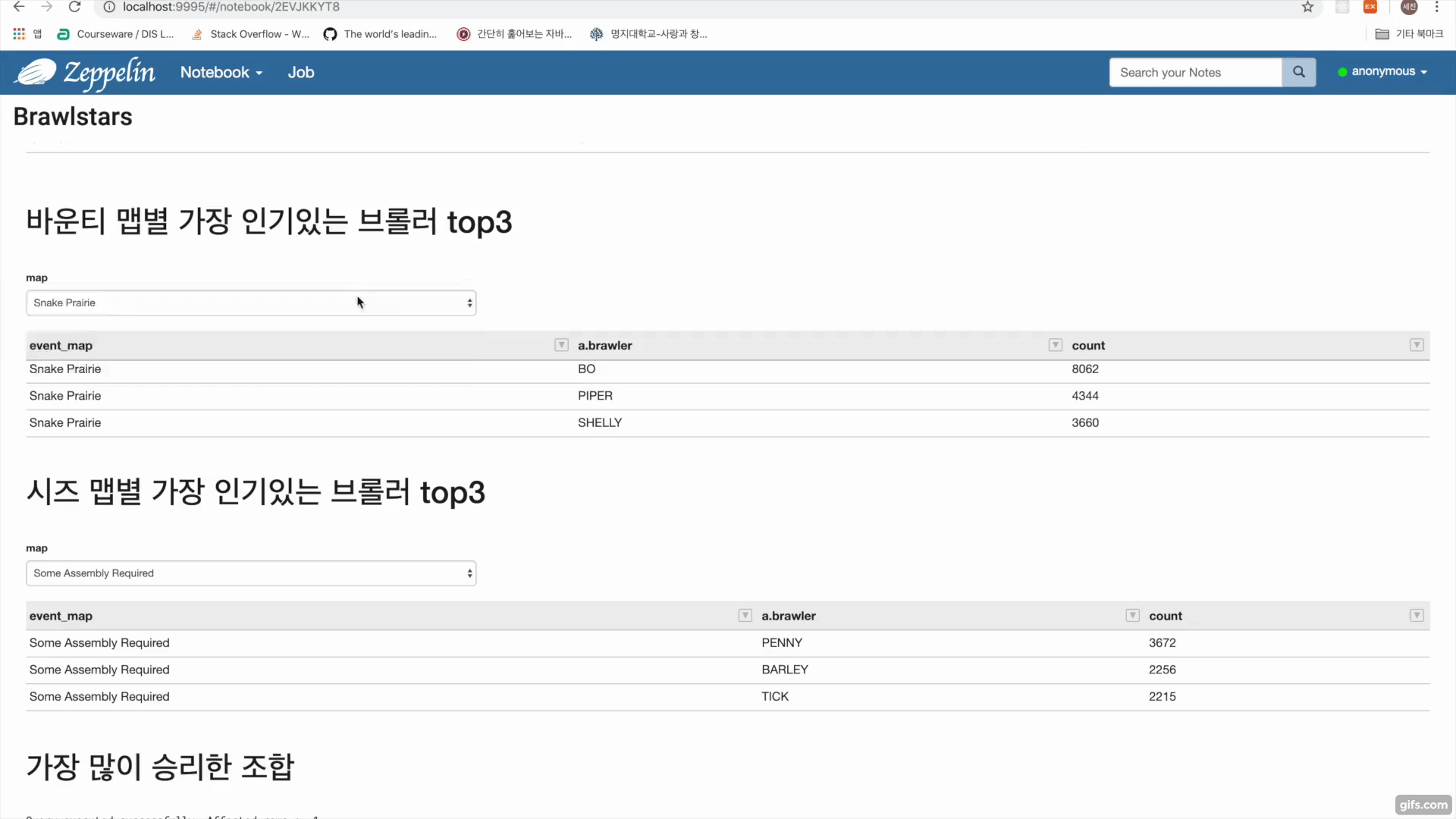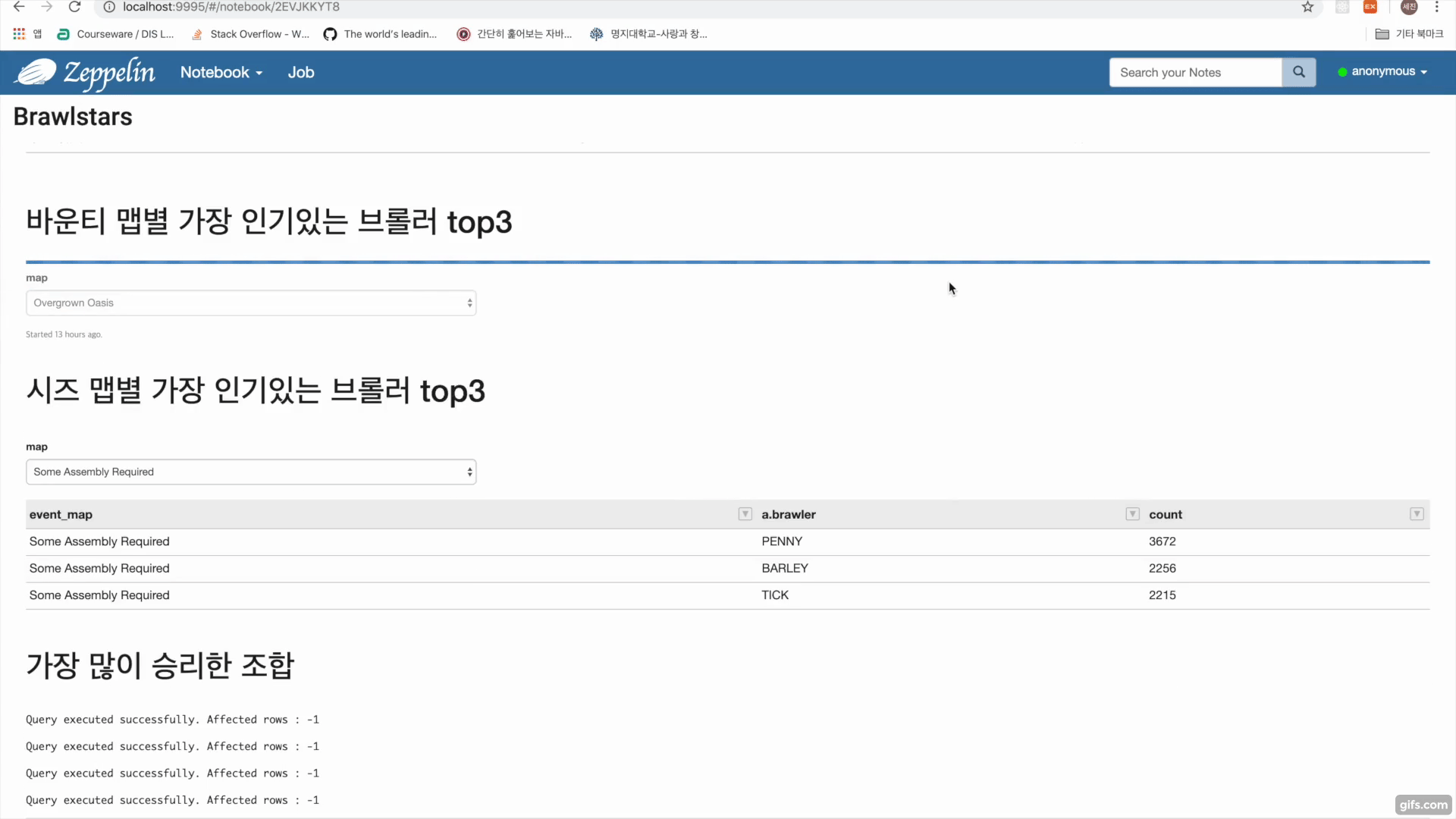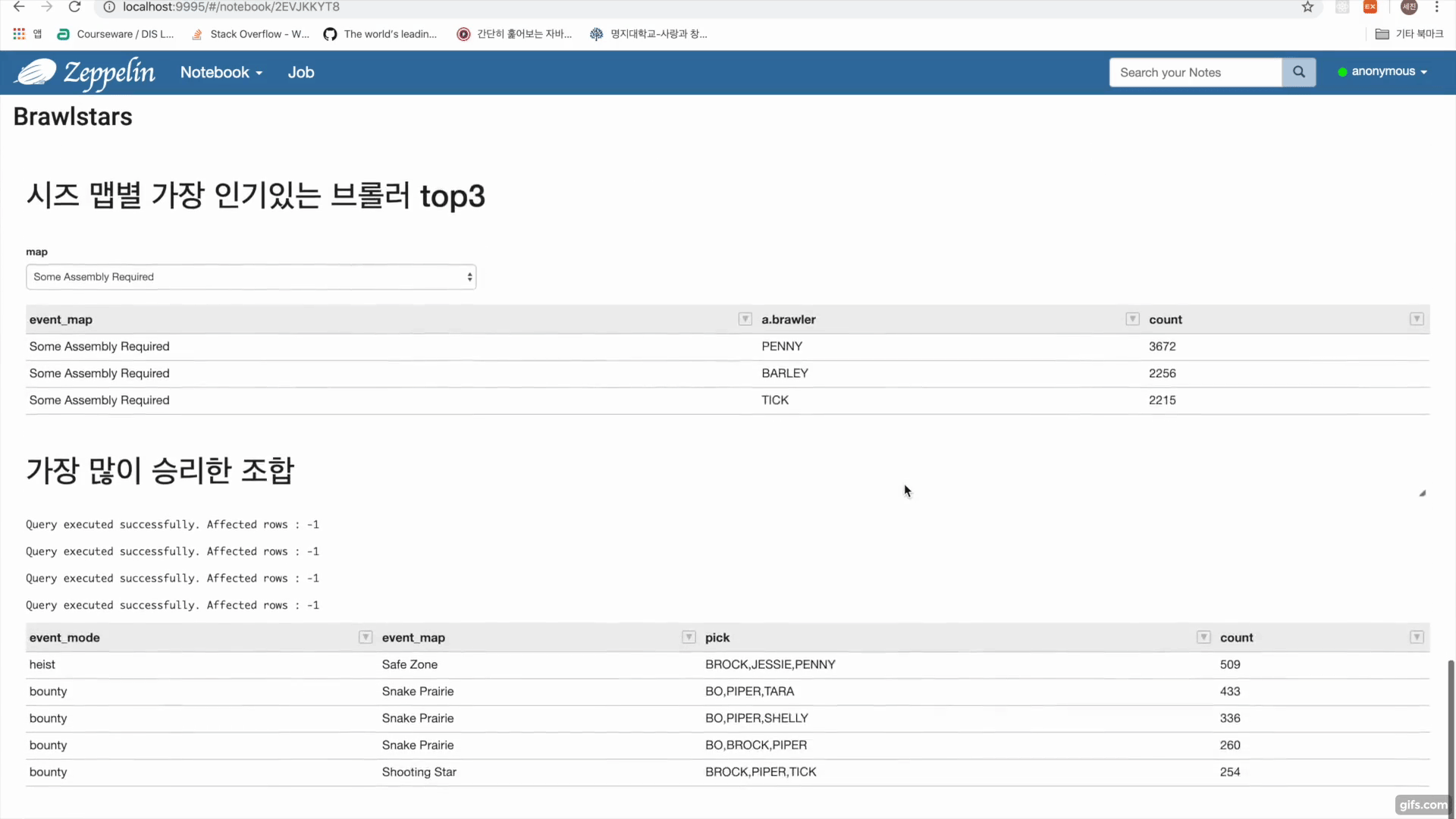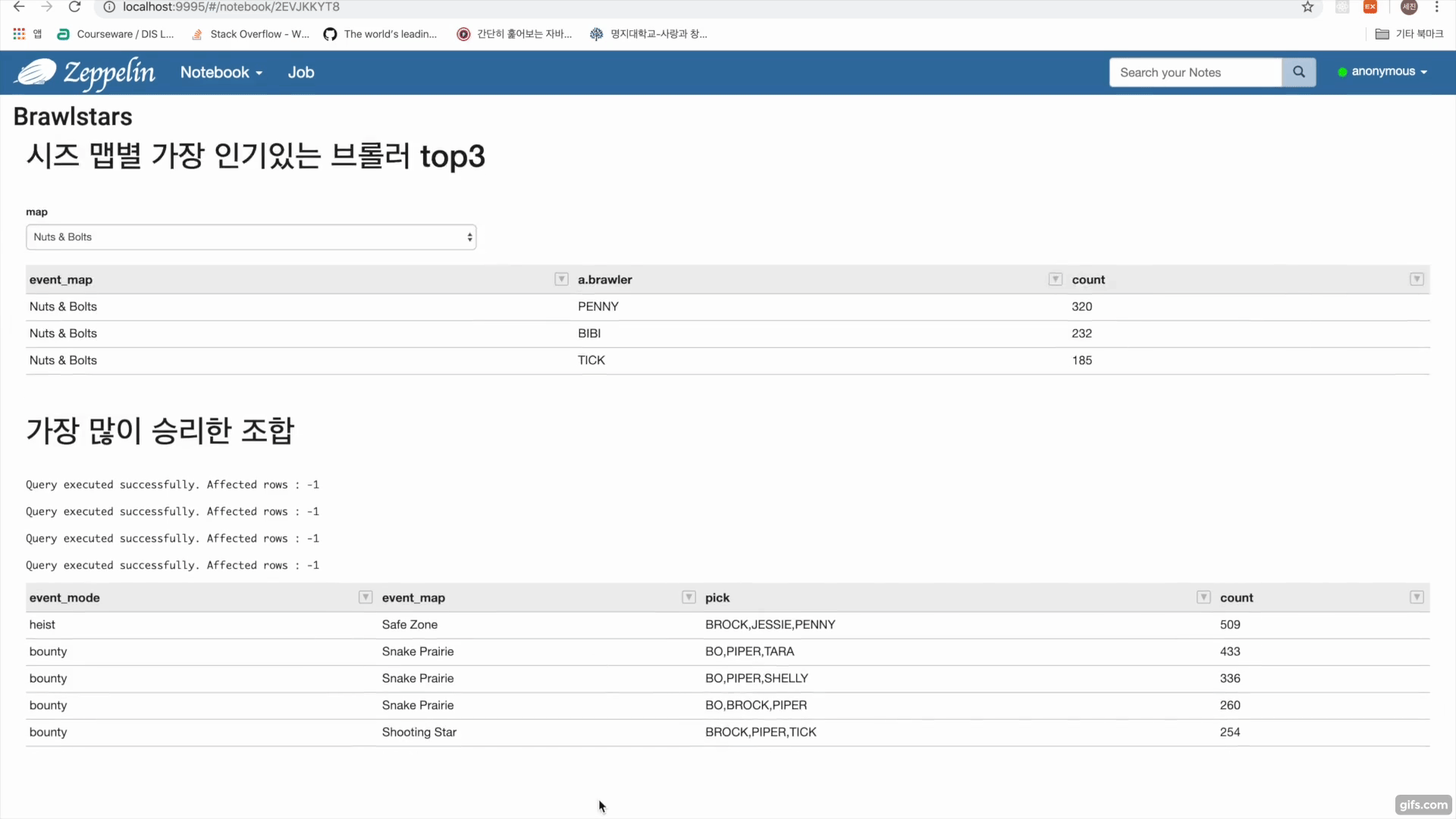
- Get(/rankings/{countryCode}/players)를 통해 랭커들의 플레이어 태그를 수집
- Get(/players/{playerTag}/battlelog)를 통해 플레이어 태그에 해당하는 유저 배틀로그
-
python
-
DB_connection.py
sqlalchemy를 이용해 python파일과 vm안의 mysql을 연결한다. -
crawling_ranking.py
crawling_func()이 있어 호출시 랭킹의 정보를 가져온다. -
ranking.py
crawling_func()호출 후 랭킹정보를 가져온다.
Flatten을 이용해 json 데이터를 분해한 뒤 데이터프레임에 저장한다.
저장된 데이터프레임에서 플레이어태그만 mysql ranking테이블에 저장한다.
이때 insert ignore을 사용해 re_ranking테이블에는 이미 저장된 플레이어태그를 insert하지 않는다. -
battlelog.py
re_ranking테이블에서 플레이어 태그를 가져와 api에 해당 플레이어의 배틀로그를 요청한다.
받아온 배틀로그를 데이터프레임에 저장한다.
이때 데이터구조상 누구의 승리인지 패배인지 확인할 수 없기때문에 playerTag를 데이터 프레임에 같이 넣고 mysql에 insert한다.
배틀로그는 중복을 허용해 계속 mysql에 쌓아둔 뒤 하둡에 올리기 전에 중복 처리를 한다.
배틀로그 중복을 파이썬 파일에서 insert할 때마다 확인하면 쿼리의 속도가 눈에 띄게 느려지기 때문이다.
-
-
oozie
- mysql
mysql --defaults-file=.my.cnf -e "use brawlstars; DROP TABLE IF EXISTS re_battlelog; create table re_battlelog select distinct * from battlelog;Truncate battlelog;"Oozie가 실행되면 mysql battlelog테이블의 하루동안 모은 배틀로그 중복을 제거한다.
re_battlelog테이블을 생성해 중복을 제거한 배틀로그데이터를 저장한다.
위 과정을 다 실행하면 battlelog테이블을 비운다.- sqoop
import -connect jdbc:mysql://localhost/brawlstars -table re_battlelog -m 1 -username sqoop_brawl -password-file /user/maria_dev/.password -delete-target-dir -target-dir data/re_battlelogsqoop을 이용해 mysql의 re_battlelog테이블을 data/re_battlelog경로로 옮긴다.
이때 스쿱실행시 해당 디렉토리가 존재하면 오류가 나기때문에 delete-target-dir을 이용해 전에 있던 디렉토리를 삭제한다.- hdfs
hadoop fs -mv /user/maria_dev/data/re_battlelog/part-m-00000 /user/maria_dev/battlelog/$(date +"%G%m%d")Hadoop fs -mv명령어를 이용해 re_battlelog경로 안에 있는 로그 데이터를 /user/maria_dev/battlelog디렉토리로 이동한다.
이때 파일명은 날짜로 변경한다.
데이터를 hive에 바로 insert할 수 있지만 디렉토리 만들어 저장하는 이유는 hive외부테이블을 이용하기 위함이다.
hive내부 테이블 사용시 insert된 데이터는 warehouse로 이동하고 테이블 삭제 시 같이 삭제되기 때문에
데이터를 좀 더 안전하고 편리하게 저장하기 위해 외부 테이블을 사용했다.