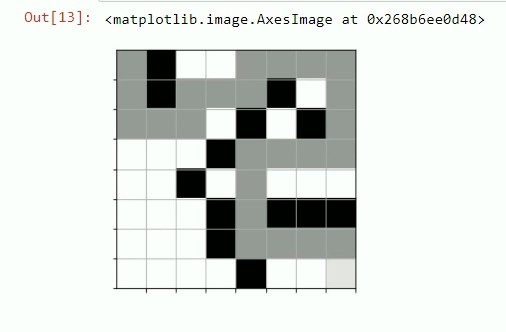
This project uses AI Reinforcement Learning to navigate through a maze. The maze is constructed by a 8x8 multi-dimensional array with 1's representing immovable blocks and 0's representing empty spaces. The goal of the AI is to navigate from the starting point, the top left block of the maze, to the ending point, the bottom right block of the maze. Once the simulation is completed, the maze along with the actions taken by the AI are plotted in a single plot that represents the model generated from the simulation. This final plot is what is shown in the image above.

This shows the statistics that were recorded for the number of iterations (epochs) it took the machine learning algorithm to complete the maze along with the total time it took the algorithm to find a 100% win rate for the maze.
This is a project that I was given from a class taken in artificial intelligence and machine learning. The program uses the Keras library to construct the deep Q-Learning algorithm that is used to solve the maze. Much of the project is starter code, with the main development being focused on the qtrain function within Jupyter Notebook file. The TreasureMaze and GameExperience classes were both starter code.
The TreasureMaze object is for tracking the state of the machine and the total rewards it collects as it progresses through the game.
The GameExperience class works with the state data that is collected in the TreasureMaze object that will hold the data in memory for the machine to use in future iterations.
This algorithm relies on the Bellman Optimality Equation shown below.
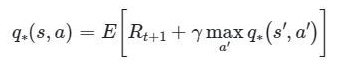
To summarize, this equation predicts the expected reward for any action taken during any given state throughout the iteration of the game. This equation produces Q-values that are used to make a table, known as a Q-Table, for the machine to reference during each decision. The idea is that these Q-values will indicate to the machine what the optimal decision is at any given state. The higher the Q-value, the higher the expected reward for that action. These Q-values are processed and updated throughout the entirety of the game.