Excluded dataset page for vp-comparefits #2387
Conversation
| current_thcovmat = current_runcard.get("theorycovmatconfig") | ||
| reference_thcovmat = reference_runcard.get("theorycovmatconfig") | ||
|
|
||
| same_theoryid = current_runcard.get("theory").get("theoryid") == reference_runcard.get("theory").get("theoryid") |
There was a problem hiding this comment.
| same_theoryid = current_runcard.get("theory").get("theoryid") == reference_runcard.get("theory").get("theoryid") | |
| same_theoryid = current_runcard.get("theory", {}).get("theoryid") == reference_runcard.get("theory", {}).get("theoryid") |
|
|
||
| same_theoryid = current_runcard.get("theory").get("theoryid") == reference_runcard.get("theory").get("theoryid") | ||
| same_datacuts = current_runcard.get("datacuts") == reference_runcard.get("datacuts") | ||
| same_thcovmat = (current_thcovmat == reference_thcovmat or (current_thcovmat is None and reference_thcovmat is None)) |
There was a problem hiding this comment.
| same_thcovmat = (current_thcovmat == reference_thcovmat or (current_thcovmat is None and reference_thcovmat is None)) | |
| same_thcovmat = (current_thcovmat == reference_thcovmat ) |
If they are both None they are equal.
That said, if the theory covmat adds any kind of difficulty, I think we can skip the theory covmat check and just make sure that in the page it is stated clearly that this is only the experimental covmat.
Because otherwise you will need to decide from which fit you are getting the covmat (even if the settings are the same, the theory covmat itself will be different because the datasets are different).
 scarlehoff
left a comment
scarlehoff
left a comment
There was a problem hiding this comment.
Thanks. Seems to work fine (see img below)

The two comments are 1) the necessary change to vp_comparefits to make it work, and 2) a comment on what we meant by excluded. Other than that this is good ^^
(btw, I understand the frustration when dealing with reportengine, I was there many moons ago, but you are navegating it quite well so don't get discouraged! After a while you learn to appreciate the guardrails and tools it offers, I promise!)
| args['config_yml'] = comparefittemplates.template_with_excluded_path | ||
| return args | ||
|
|
||
| def complete_mapping(self): |
There was a problem hiding this comment.
This was almost done!
You just need to put the conditional here (well, at the end of this function)
are_the_same = self.check_identical_theory_cuts_covmat()
if are_the_same:
log.info("Using excluded comparecard: identical theory cuts/covmat detected.")
autosettings["template"] = "report_with_excluded.md"
These autosettings of complete_mapping is what is used to complete the template afterwards.
In this particular case (in which you are just changing the template but would be using the exact same runcard for everything else) I would not add a new comparecard_excluded.yaml but just the report_with_excluded.md
fwiw, what you were trying to do you could do instead at get_config, but I think it is better to override the template .md and not the entire runcard.
After we merge this we can think, if you want, about creating a report.md dynamic instead of having several similar ones.
validphys2/src/validphys/config.py
Outdated
| self._check_dataspecs_type(dataspecs) | ||
| loader = Loader() | ||
|
|
||
| implemented = set(loader.implemented_datasets) |
There was a problem hiding this comment.
I don't think we want every dataset excluded, because in general we cannot get predictions for every dataset (to the very least, we have datasets that are polarized and some that are not and those live in different theories).
What we want is the excluded from dataspec 1 that are also in dataspec 2 (and, well, if you have 10 dataspecs, we want those that are not in all 10).
So, very close to what you have, just don't use all the implemented ones as baseline ^^U
There was a problem hiding this comment.
Thanks for the comments, it feels like we are making some nice progress. I thought the whole idea was to also include datasets not used in both fits, bu tit obviously increases the complexity. I think with these suggestions I can make some final changes and make it work.
After a while you learn to appreciate the guardrails and tools it offers, I promise!
Even though some of its features have been working against me, I definitely appreciate its strengths! It is a powerful framework, and I hope I will come to bless more often than curse it ;-)
There was a problem hiding this comment.
I guess once and only once we have the 4.1 dataset defined we can have a canonical set of data, but at the moment this would be a nightmare because any one dataset or variant or fktables that one has locally and is not online would create problems for everyone else.
There was a problem hiding this comment.
Indeed. We have to make sure it doesn't do anything crazy.
I was also considering the inclusion of a commandline argument for doing an excluded dataset report, which would perhaps protect against these problems. But the code needs to be sound in any case.
There was a problem hiding this comment.
But in any case that we cannot do without a canonical set of data (and theory) because no theory contains fktables for all datasets.
It would also be extremely slow ^^U We might want another script for vp-check-all-data or something. comparefits is supposed to be comparing fits, this is something else.
|
Hi Juan, I still don't think I understand how to go from "returning a list of (pos)dataset names to actually generating plots in the report. I can generate a list of dataset names to be included, as before. But I just don't understand why replacing |
|
I did not try with the positivity ones. Does it work for you with the "normal" datasets? I think I used If you don't manage we can have a meeting next week to finish up the missing pieces. This week is my last of one of the courses and I don't think I can ^^U |
|
No I am now using I assume that we would prefer the latter, in which case we cannot simply use Then I tried also plot_fancy, but since I do not understand what reportengine is doing, I do not know what I need to return from my results for both theory predictions. The problem is that when I use |
|
So, some pointers, but probably better to discuss next week with a bit of calm, I think you are overcomplicating your own life a bit too much here. For now just do the changes necessary to get the list of excluded datasets from the combinations of fits (and not all datasets ) like right now. To do a plot you only need:
Since 1) and 2) you have checked they are the same by this point, you can take them from just one of them and that's perfectly fine. We want that information to come only from one because the other is exactly the same. 3), PDFs, it is set in the comparefit runcard to be a list of the PDFs corresponding to the two fits. And finally, what you need to provide with your function, a With that out of the way, in order to get the (to each of current and reference) That's perfectly fine, since you are matching them you need to have them. And then, from those two lists of so, taking all this in consideration, this should work even if not the most beautiful: def produce_matched_excluded_datasets_by_name(self, dataspecs):
dinputs_a = dataspecs[0]["dataset_inputs"]
dinputs_b = dataspecs[1]["dataset_inputs"]
# some fancy logic
more_info = {
"pdfs": [i["pdf"] for i in dataspecs],
"theoryid": dataspecs[0]["theoryid"],
"fit": dataspecs[0]["fit"] # The fancy logic will put here the _right_ fit since this is used for the cuts
}
return [{"dataset_input": i, **more_info} for i in dinputs_b[1:3]]And in the validphys runcard This is very not-fancy-at-all since I'm returning a list with a lot of information repeated each time. You can probably play with the report and get the information out that way (something like joined_dataspecs: theory: from current, and then use that joined_dataspecs there... but no way I can do that from memory...) (also, please, rebase on top of master... if you need to merge so be it, but a rebase would be much better!) |
|
Thanks for the pointers. Reportengine is a beast, and with some slight changes it now finally produces a report! There is one caveat. Reportengine looks for a filtered dataset in the fit directory of associated dataspecs, so we will have to either restrict the usage to something like "compare [fit with only AB] to [fit with ABC]". (and not the other way around!!) or do some clever check so that it works both ways around. |
This is done, afair, only for the cuts (when you have The snippet of code I wrote before does that in that you have the whole namespace in each item of the list. Not beautiful but it should work. |
|
Hi Juan, this should now be finished. I made an attempt to create an actual extra page wth a Please take a look, I think at this point only perhaps some cleaning up is required. |
No, you need to add it to the dataspec with the same that all other information is added (or from |
|
Ah yes, you are right. This reproduces now a report for me as well. |
|
I haven't looked at the code but if both of them work I would choose either the faster or the one that adds the least amount of lines of code* which usually means it is going to be more maintainable. You choose! *being reasonable I mean, maybe the longer one is obviously easier to read |
|
Unfortunately for me, your function (where we pre-add dataset_inputs from_ fit to dataspecs), is a good 50 seconds faster. |
|
@jekoorn please rebase on top of master and fix the failing tests (perhaps rebasing will fix it already) |
validphys2/src/validphys/config.py
Outdated
| # } | ||
| # return [{"dataset_input": i, | ||
| # "dataset_name": i.name, | ||
| # **more_info} for i in dinputs_b[1:3]] |
There was a problem hiding this comment.
Remove this. We don't want a graveyard of all functions!
| """ | ||
| Like produce_matched_datasets_from_dataspecs, but for excluded datasets from a fit comparison. | ||
| Return excluded datasets, each tagged with the more_info from the dataspecs they came from. Set up to work with plot_fancy. | ||
| """ |
There was a problem hiding this comment.
Here you have two docstr one after the other.
validphys2/src/validphys/config.py
Outdated
| # add (dsin, spec) to the set containing (proc, ds) | ||
| if key not in all_sets: | ||
| all_sets[key] = [] | ||
| all_sets[key].append((dsin, spec)) |
There was a problem hiding this comment.
What are you exactly doing here? If you are just checking the dataset_input from the dataspecs by name you should not need a lot of this.
Note that you are trying to reproduce produce_matched_datasets_from_dataspecs but what you really want is produce_matched_excluded_dataset_inputs_by_name. And what you are really doing, this can be simplified quite a bit.
validphys2/src/validphys/config.py
Outdated
| "pdfs": [i["pdf"] for i in dataspecs], | ||
| "theoryid": dataspec["theoryid"], | ||
| "fit": dataspec["fit"], | ||
| } |
There was a problem hiding this comment.
No need to create a function here. theoryid is fixed (and should come from the outside tbf) pdfs should come from the outside not be part of the output.
validphys2/src/validphys/config.py
Outdated
| "dataset_input": dsin, | ||
| "dataset_name": dsin.name, | ||
| **build_more_info(spec), | ||
| } |
There was a problem hiding this comment.
imho this can be simplified.
Note that at this point what you want for each dataset just the dataset_input itself and a the fit from which you want to take the cuts.
Everything else is shared. If you don't know how to deal with reportengine to do so that's fine, but at least make it explicit that everything else is shared.
With what you have I would've put:
dataset_inputs = dataspecs[0].as_input()["dataset_inputs"]
# Check that `dataset_inputs` is in the dataspec, otherwise raise Exception early.
# Restrict it to two dataspecs
exclusive_dinputs = []
for spec in dataspecs:
for dinput in spec["dataset_inputs"]:
# Check whether it exists in all of the others
if any( dinput not in s["dataset_inputs"] for s in dataspecs ):
exclusive_dinputs.append( (dinput, spec) )
There was a problem hiding this comment.
I see. It's obviously more efficient and simpler to only construct the required objects after knowing what the mismatched datasets are. I have now with your suggestions simplified the function greatly, and added dataset_inputs to dataspecs. This should speed it up considerably.
I am still building the input for plot_fancy myself:
# prepare output for plot_fancy
for dsin, spec in mismatched_dinputs:
res.append(
{
"dataset_input": dsin,
"dataset_name": dsin.name,
"theoryid": spec["theoryid"],
"pdfs": [i["pdf"] for i in dataspecs],
"fit": spec["fit"],
}
)
return res
but in principle it should be clear that everything is shared. I'm not sure what I should do with spec["theoryid"]. From the check in vp_comparefits.py we know that they are the same, but do we want to rely on that check?
In any case I've rebased and pushed some changes. I will try to fix the failing tests asap.
e7878b3 to
04a6a89
Compare
validphys2/src/validphys/fitdata.py
Outdated
| # datasetcomp = match_datasets_by_name() | ||
|
|
||
|
|
||
| # return excluded_set |
| c.update(self.complete_mapping()) | ||
| return self.config_class(c, environment=self.environment) | ||
|
|
||
| def check_identical_theory_cuts_covmat(self): |
There was a problem hiding this comment.
Add a docstr to explain what this is doing.
| with open(current_runcard_path) as fc: | ||
| with open(reference_runcard_path) as fr: | ||
| current_runcard = yaml_safe.load(fc) | ||
| reference_runcard = yaml_safe.load(fr) |
There was a problem hiding this comment.
I think once you have used loader.check_fit above, you can, instead of using .path/filter.yml use directly as_input() to avoid having to open both runcards yourself.
| are_the_same = self.check_identical_theory_cuts_covmat() | ||
| if are_the_same: | ||
| log.info("Adding mismatched datasets page: identical theory cuts/covmat detected") | ||
| autosettings["template"] = "report_mismatched.md" |
There was a problem hiding this comment.
Instead of changing the whole template (and then needing a whole new report) you can change directly the mismatched_report part.
e.g., if are_the_same is True then the template part under mismatched_report stays, otherwise you drop it and change it to `template_text: "Difference settings, mismatched page cannot be added".
There was a problem hiding this comment.
I am not really sure how to do this. I understand the need, since we don't want 30 different report-xx.md tempalates. You mean take the existing report.md and then add something like the following?
report.update(
"""
Mismatched datasets
--------------------------
{@with mismatched_datasets_by_name@}
[Plots for {@dataset_name@}]({@mismatched_report report@})
{@endwith@}
"""
)
Ideally I wouldn't want to add this page all at the bottom, but somewhere after the other datasets.
Or is there a better way, where we replace only the [Plots for {@dataset_name@}]({@mismatched_report report@}) line with some text like "Different settings, no mismatched datasets can be added". I'm just not sure how to do this :-)
There was a problem hiding this comment.
There might be a better / more beautiful way but what I would do is (with minimal modification to what you already did) to add the following to report.md:
[Mismatched report]({@mismatched_information report@})
--------------------
And then to comparecard.yaml
mismatched_information:
meta: Null
actions_:
- report
# Datasets will go to their own page
mismatched_report:
meta: Null
template: mismatched.md
template_text: |
Mismatched datasets
---------------------
The following plots corresponds to datasets which are not available in one of the fits.
{@with mismatched_datasets_by_name@}
[Plots for {@dataset_name@}]({@mismatched_report report@})
{@endwith@}and finally, to vp_comparefits.py
are_the_same = self.check_identical_theory_cuts_covmat()
if are_the_same:
log.info("Adding mismatched datasets page: identical theory cuts/covmat detected")
else:
autosettings["mismatched_information"] = {"template_text": "Mismatched datasets cannot be shown due to cuts or theory not being identical"}In other words, if they are not the same, the template_text gets effectively dropped. You still get a "Mismatched Report" link to nowhere though, but I think that's better than having two reports that are basically the same thing.
Ideally I wouldn't want to add this page all at the bottom
I would actually prefer it very much at the bottom, after the list of datasets that are identical/mismatched so you get "Here's everything that's the same, same cuts and same everything, now click here".
But ok, your report your rules :P
There's the alternative of taking the template as a really template and put in the middle
MISMATCHED_PLACEHOLDER
and then do a search and replace of the placeholder with what you already have. That would also be ok for me.
There was a problem hiding this comment.
Done, waiting for the tests to finish now.
|
Thanks, did you test it and checked that it worked as expected? |
|
Yes, I forgot to attach the report. See below: |
|
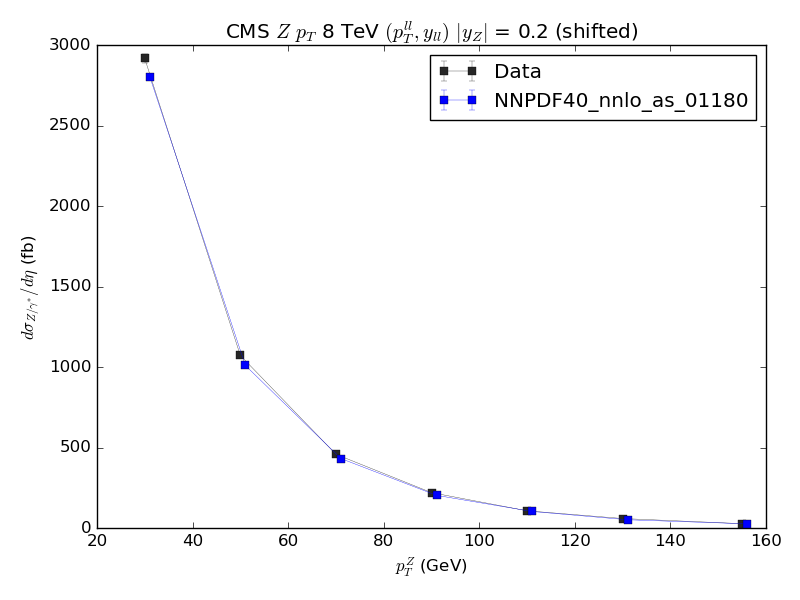
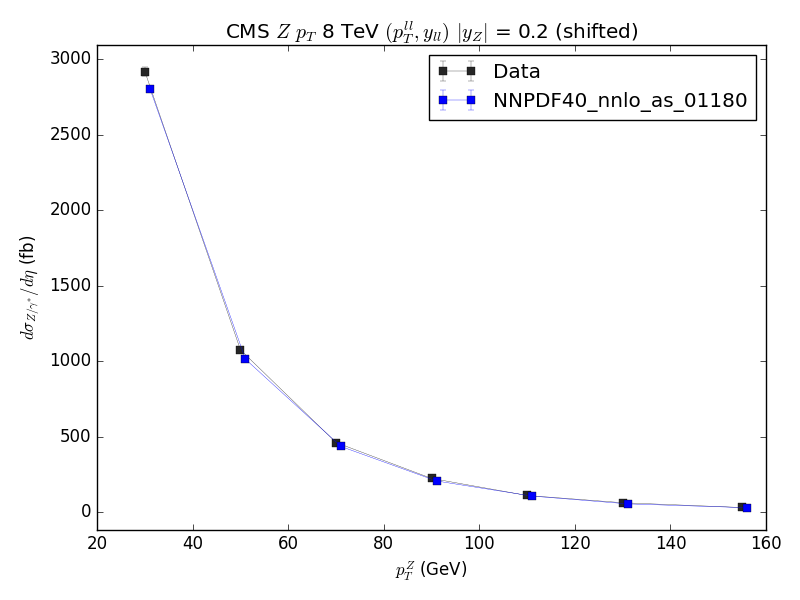
Hi, I am now going through the failed checks, that I managed to reproduce locally. In particular, a plot_fancy plot fails because it doesn't look similar enough. See here the baseline, the result and the failed difference. The only difference is a small lack of space below the y=0 axis. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
Was this needed before or does it happen only for the new page that has been added? |
|
Only for the new page. |
|
Then you should either find the reason (why does it happen for the new page but not for the old one?) or at the very least wrap it so that it is done only for the new page. Otherwise you should consider comparing side by side all ratio plots and look at them one by one... because it already happened in the past that one of this changes looked good for a subset of plots but they were not all checked and quite a few were actually broken (and there are many observables and many plots ^^U, my recommendation is to go with either understanding the problem or leaving it only for the new page) |
d867ebc to
a32dc03
Compare
|
Greetings from your nice fit 🤖 !
Check the report carefully, and please buy me a ☕ , or better, a GPU 😉! |
PR for the excluded (positivity) datasets in a vp-comparefits report.
This page is added if and only if the theory id, datacuts, and theory covmat (if present) are identical between fits.