Esse é o projeto final do bootcamp de Engenharia de Dados da Soulcode Academy. Nele colocamos em prática os conhecimentos adquiridos durante o curso.
O projeto consiste em escolher datasets sobre o tema pré-determinado, extraí-los de bancos de dados públicos, carregá-los no ambiente da Google Cloud Platform (GCP), tratar seus dados com o uso de bibliotecas Python e carregar esses dados, agora tratados, em databases na GCP e no MongoDB. Por fim, as especificações do projeto preveem ainda analisar os dados tratados, em busca de insights relevantes acerca do tema.
Nosso grupo é composto por 5 pessoas - Daniel Campos, Fernanda Martins, Lucas Sobral, Mayara Dantas e Stefany Gracy - e a ele foi designado o tema Clima.
Quanto ao nosso planejamento para execução do projeto, definimos as etapas a serem cumpridas, a distribuição de tarefas necessárias para o cumprimento de cada etapa e o tempo estimado de conclusão para cada tarefa, as quais estão detalhadas nesta página.
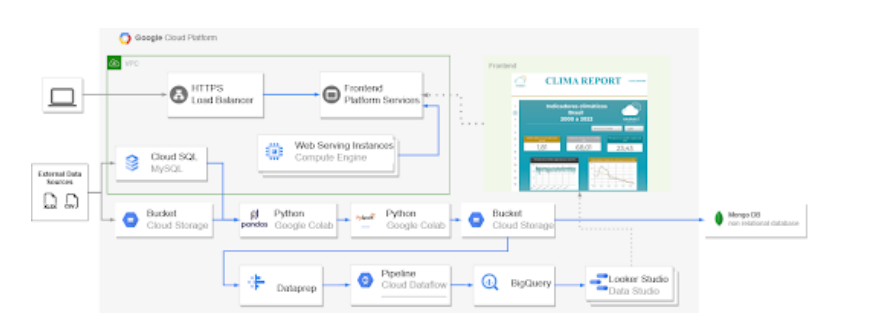
A primeira etapa de nosso projeto foi a criação da infraestrutura, com todos os serviços, aplicações e ambientes de que necessitaríamos para realizá-lo.
Conforme estabelecido nas orientações repassadas a nós, trabalharíamos com a Google Cloud Platform, portanto nosso primeiro passo foi criar o projeto na GCP, com o título de projeto-final-ed7. Em seguida, configuramos os acessos a ele, por meio do serviço de Identity and Access Manager (IAM), disponibilizado pela plataforma. Todos os membros da equipe receberam o acesso de owner e tiveram acesso à key da service account, criada para que pudéssemos acessar a GCP por ambientes externos, tais como o Google Colab.
Ainda na GCP, definimos um orçamento para o projeto, configurando alertas para que fôssemos informados caso nossos gastos atingissem certos montantes. Além disso, criamos um bucket, no Cloud Storage, e um servidor MySql, na mesma plataforma, para que pudéssemos armazenar os datasets originais.
Ademais, criamos um cluster no MongoDB para carregamento dos dados tratados e uma aplicação web, para a convergência de todos os produtos do projeto em um único lugar, de modo a tornar mais prático o acesso dos clientes a eles.
Criada a infraestrutura, trabalhamos simultaneamente na definição dos datasets que seriam utilizados e na escolha do nome e da identidade visual do grupo.
A partir do tema que nos foi atribuído, elencamos questões que poderiam nos gerar desdobramentos interessantes e escolhemos, como pergunta central: “Quais foram as alterações mais significativas nos indicadores climáticos do Brasil nos últimos anos?”.
Elencamos também outras perguntas, que julgamos se relacionar com a questão central. Foram elas:
- Qual a relação entre umidade, temperatura e precipitação?
- Houve eventos extremos? Se sim, quais as possíveis causas?
- Os desastres naturais têm relação com as mudanças nos indicadores climáticos observados? Se sim, quais?
- Qual o prejuízo financeiro dos desastres que aconteceram nesse período?
- Os indicadores de emissão de CO2 relacionam-se com os indicadores climáticos?
- Qual a relação entre umidade e queimadas?
- De que forma a produção agrária foi afetada pelas variações de precipitação e temperatura?
Diante disso, pesquisamos por datasets em bancos de dados públicos (Kaggle, Dados - GOV, BDMEP, etc.) e escolhemos 6 deles, sobre os quais falaremos mais adiante, para analisarmos.
O nome escolhido foi Amanaci que é a divindade tupi-guarani vinculada às chuvas. Escolhemos esse nome não só porque remete as nossas origens, como também nos traz a ideia de chuva e, portanto nuvem e clima. Nesse sentido, nosso símbolo é uma nuvem, que simultaneamente remete ao tema assim como a ideia de computação em nuvem. A nuvem sobrepõe uma engrenagem, símbolo das engenharias, posicionadas de modo a desenhar a imagem de um céu com sol, o que faz referência aos “dias de sol” e, por extensão, das soluções que propomos. As especificações encontram-se no link.
-
Clima
Esse será o dataset principal que concentrará os dados primordiais para nossas análises. Essa escolha se deve ao fato dele conter bastantes informações diversificadas e aprofundadas sobre indicadores de temperatura, precipitação, umidade, radiação e velocidade dos ventos de diversas cidades brasileiras. Os dados foram medidos por meio de estações automáticas.
Os arquivos originais estavam no formato CSV. (Fonte: Kaggle - Clima)
-
Emissão de CO2
Fala sobre a emissão de carbono no mundo inteiro, do ano de 1960 até 2021. Foi escolhido com o propósito de comparar as mudanças climáticas apontadas no dataset clima com as emissões de carbono e verificar se há correlações. Embora os dados sejam globais usaremos apenas as emissões no Brasil.
O arquivo original estava no formato XLSX. (Fonte: CO2 )
-
Queimadas
Possui dados do INPE (Instituto Nacional de Pesquisas Espaciais) sobre a incidência de queimadas e incêndios florestais no território brasileiro coletados por meio de imagens de satélite. O site do programa dá acesso ao banco de dados e permite a seleção de quais dados serão extraídos. Optamos por extrair apenas os dados de ocorrências no Brasil uma vez que é nosso foco de análise. O objetivo desse dataset é relacionar a incidência de queimadas com as mudanças ocorridas no clima.
Os arquivos originais estavam no formato CSV. (Fonte: INPE - Banco Geral/Por Estados)
-
Produção agraria
Traz dados sobre produção de café, cana, milho e soja no Brasil. Escolhido com o objetivo de analisar as possíveis influencias das mudanças climáticas na produção dessas commodities. Optamos por trabalhas apenas com essas commodities pois são as principais em produção e exportação do Brasil.
Os arquivos originais estavam no formato CSV. (Fonte: SIDRA - IBGE )
-
Desastres Naturais
Aqui temos dois datasets sobre desastres naturais, um que traz o tipo de ocorrência e a quantidade de pessoas afetadas ou mortas e outro que traz o custo financeiro dos desastres. Foi selecionado para levantar a correlação com as mudanças climáticas assim como levantar seu impacto econômico. A fonte original possui dados de toda América Latina porém realizamos a extração apenas dos referentes ao Brasil por conta do nosso foco de análise.
Os arquivos originais estavam no formato XLSX. (Fonte: CEPAL - ONU)
Após selecionados os datasets que trabalharemos realizamos o envio deles para uma bucket no Google Cloud Storage. Uma vez na bucket enviamos cada dataset como uma tabela diferente para um banco de dados no MySQL hospedado na Google Cloud Platform.
Esse dataset é referente às Informações meteorológicas do Brasil, levantadas pelo INMET (Instituto Nacional de Meteorologia) referente aos anos de 2000 a 2022. Os dados disponíveis nele foram coletados pelo BDMEP (Banco de Dados Meteorológicos) e englobam apenas as estações automáticas em funcionamento no país, sendo a primeira medição executada no dia 2000-05-07 e a ultima no dia 2022-10-31.
As colunas dos dois datasets eram as seguintes:
- ESTACAO / STATION
- DATA (YYYY-MM-DD) / DATE (YYYY-MM-DD)
- PRECIPITACAO MAXIMA (mm) / rain_max (mm)
- RADIACAO MAXIMA (W/m2) / rad_max (W/m2)
- TEMPERATURA MÉDIA (AUT)(C) / temp_avg (AUT)(C)
- TEMPERATURA MAXIMA (AUT) (C) / temp_max (AUT)(C)
- TEMPERATURA MINIMA (AUT)(C) / temp_min (AUT)(C)
- UMIDADE MAXIMA (AUT) (%) / hum_max (AUT) (%)
- UMIDADE MINIMA (AUT) (%) / hum_min (AUT) (%)
- VENTO, RAJADA MAXIMA (m/s) / wind_max (m/s)
- VENTO, VELOCIDADE MÉDIA (m/s) / wind_avg (m/s)
- ESTADO DO BRASIL (UF) /state
- REGIÃO DO BRASIL/ region
- CIDADE DA ESTAÇÃO/city_station
- LATITUDE (º) /lat (º)
- NIVEL DO MAR /lvl
- LONGITUDE (º) /lon (º)
- PRIMEIRA MEDIÇÃO (YYYY-MM-DD) /record_first (YYYY-MM-DD)
- ULTIMA MEDIÇÃO (YYYY-MM-DD)/record_last (YYYY-MM-DD)
O conjunto de dados é composto por dois datasets: um sobre o clima (que possuía 2685380 linhas e 11 colunas) e outro sobre as estações de medições localizadas no Brasil (com 613 linhas e 9 colunas).
Renomeamos a coluna 'ESTACAO' para 'id_station’ no df_clima, para que fosse idêntica ao nome existente no ‘df_clima_estacoes’. Isso foi feito para podermos executar o merge nos DF’s. Após o merge o novo dataset ficou com 2684220 linas e 19 colunas.
Renomeamos todos os nomes das colunas que estavam originalmente em inglês para suas respectivas traduções para o português.
Com a pré-análise notamos que haviam valores discrepantes de temperaturas, abaixo da normalidade no Brasil, então encontramos uma estação de estudos do Brasil localizada na Antártica, Criosfera. Dropamos todas as informações referente a essa estação.
Encontramos outros dados de temperatura não condizentes com o clima do Brasil e após análise desses dados dropamos por ser possivelmente, frutos de erros de medição dos equipamento.
Referente a coluna de umidade percebemos valores discrepantes e que não haviam sentido como por exemplo cidades litorâneas com umidade abaixo da normalidade aceita. Dropamos essas informações por ser possivelmente erros de medição.
Renomeamos os nomes das regiões pois estavam como siglas e dessa forma não seria muito intuitivo para as análises.
Convertemos as colunas de altitude, longitude e latitude para float e fizemos uma pequena alteração das ‘,’ para ‘.’ (inconsistências) nas colunas de latitude e longitude para não interferir futuramente.
Resetamos o index.
Convertemos as colunas: data_medicao, primeira_medicao e ultima_medicao para datetime.
Dataset é referente a emissão de carbono de todos os países do mundo por ano. As informações foram extraídas do site Global Carbono Atlas. Esse dataset possuía 62 linhas e 218 colunas, com medições de 1960 a 2021.
As colunas desse dataset referem-se ao ano que foram realizadas as medições e os países em que elas foram realizadas.
Com o Pandas renomeamos as colunas que estavam originalmente em inglês com sua tradução para o português.
Como nosso objetivo foi utilizar os dados do Brasil mantemos apenas as colunas que correspondiam a esses dados e dropamos todas as outras. O dataset então ficou com duas colunas e 62 linhas.
Não foram encontradas inconsistências ou duplicatas.
Alteramos a coluna de ano para datetime para seguir a configuração padrão que optamos para todos os datasets.
Com Pyspark atualizamos o tipo de cada coluna e analisamos se havia alguma coluna com dados nulos.
Dataset sobre incidência de queimadas e incêndios florestais ocorridos em solo brasileiro à partir de 1998 até 2023. Inicialmente trabalhamos com um dataset para cada estado brasileiro, pois a extração da fonte original só pode ser realizada dessa forma.
Cada dataset tinha 28 ou 29 linhas, a depender da existência de registros em 2023 ou não. Todos os datasets tinham as mesmas informações de colunas, sendo elas:
Unnamed: 0 Janeiro Fevereiro Março Abril Maio Junho Julho Agosto Setembro Outubro Novembro Dezembro Total
A primeira coluna era ocupada com as informações do ano daqueles registros, o máximo de queimadas registrado, a média ao longo dos anos e outra com o mínimo. As colunas seguintes - colunas de meses - tinham a quantidade de queimadas registradas nos respectivos meses. A última, denominada Total, tinha a soma da quantidade de queimadas daquele ano.
Foi realizado tratamento com Pandas. Como todos os DF’s tinham as mesmas colunas e as mesmas normalizações a serem feitas elas foram realizadas por meio de laços de repetição.
Criamos uma lista com todos os DF’s utilizados, um para cada estado brasileiro.
O nome de cada DF era a sigla do estado correspondente. Criamos outra lista com esses nomes em formato de string e com um for que percorria essa lista colocamos essas strings em caixa alta.
Criamos outro for que percorria a primeira lista, dos DF’s, realizando as seguintes alterações em cada:
- Drop da coluna ‘Total’, que continha a soma de queimadas daquele ano.
- Drop das linhas 25 em diante pois elas tinham dados com os máximos, mínimos e média de queimadas. Embora relevantes esses dados poderiam ser facilmente extraídos nas analises e caso permanecessem no DF tornariam seu uso menos intuitivo. Além disso, os registros do ano de 2023 também foram dropados pois a quantidade de registros ainda é pouca e os outros dados que estamos trabalhando vão até 2022.
- Renomeamos a coluna ‘Unnamed: 0’ para ‘ano’ pois agora os únicos dados que estariam presentes nela era o ano das ocorrências.
- Adicionamos uma coluna chamada ‘uf’ que seria preenchida com os itens da lista mencionada acima, que consistia nas siglas dos estados em formato string.
Além das alterações feitas com o for também foi realizado o pivotamento de cada DF. Dessa forma transformamos as colunas de meses em linhas dentro de uma nova coluna chamada ‘mes’ que seria seguida do registro da quantidade de queimadas registradas nesse mês, também numa nova coluna chamada ‘queimadas’.
Feito essas alterações os DF’s foram concatenados em um único DF com as informações do país todo.
Na coluna queimadas existiam linhas com - apenas. Como o dataset é gerado a partir de imagens de satélite esse registro significa a não ocorrência de uma queimada, de forma que optamos por substituir esse valor por 0. Posteriormente mudamos o tipo da coluna para inteiro.
Na coluna mes substituímos a string com o nome de cada mês para outra string com a data, apenas dia e mês. Para cada mês foi colocado o dia 01. Depois dessa alteração agregamos essa coluna a coluna de ano, que também era string, e colocamos em uma coluna nova chamada data. Por fim a coluna data foi mudada de string para datetime. Essas alterações foram feitas para que no momento da análise no Looker possamos fazer filtros de tempo, o que só é possível com uma coluna do tipo data.
Inicialmente tínhamos 4 datasets, cada um com os dados de produção de uma commodity diferente, sendo elas café, cana, soja e milho. Escolhemos trabalhar com apenas essas porque são centrais na produção e exportação no Brasil.
Cada DF continham 23 colunas, uma chamada Unidade da Federação com o estado do registro em questão e as seguintes eram todas colunas de ano, de 2000 até 2021.
As seguintes alterações foram realizadas individualmente em cada dataset pois seus dados eram padronizados e as normalizações seriam as mesmas.
- Foi adicionada uma nova coluna com o nome da respectiva commodity.
- As colunas de ano foram transformadas em linhas dentro de uma coluna nova chamada ano. Seus respectivos registros foram adicionados em uma nova coluna chamada kg/ha pois contém os dados de quilos por hectares produzidos em cada ano.
- A coluna Unidade da Federação foi renomeada para uf.
Uma vez normalizados esses dados nos DF’s individuais os 4 foram concatenados em um único DF com as informações unificadas.
Nesse DF foi verificado que haviam campos com os dados - e … que foram substituídos para nulos.
Na coluna UF foi encontrado um valor chamado Guanabara que, além de não se tratar de um estado, não possuía nenhum valor, de forma que todas suas ocorrências foram dropadas.
A coluna ano foi convertida em datetime para facilitar na hora da análise.
Na coluna uf foram renomeados os estados. Estavam escritos por extenso e foram substituídos pelas suas respectivas siglas.
Foram realizados alguns plots com Pandas, como:
- a quantidade de produção de cana-de-açúcar ao longo dos anos em todo o Brasil e nos estados de São Paulo, Goiás e Minas Gerais;
- a quantidade de produção de café ao longo dos anos em todo o Brasil e nos estados de Minas Gerais, Espírito Santo e São Paulo;
- a quantidade de produção de milho ao longo dos anos em todo o Brasil e nos estados de Mato Grosso, Paraná e Mato Grosso do Sul;
- a quantidade de produção de soja ao longo dos anos em todo o Brasil e nos estados de Bahia, Tocantins e Piauí.
A escolha desses plots em específico se dá pelo fato deles serem referência na produção das commodities em questão.
Os datasets apresentam, respectivamente, os registros de ocorrências de desastres naturais acontecidos no Brasil entre os anos de 1990 e 2021 e o impacto econômico estimado desses eventos, no referido país, entre os anos de 1970 e 2022.
Eles foram extraídos do banco de dados da Comissão Econômica para a América Latina e o Caribe da Organização das Nações Unidas (CEPAL-ONU).
O conjunto de dados de ocorrências se concentra em fenômenos tais como inundações, secas, tempestades, etc. Já o de impacto econômico concentra-se nas dimensões patrimoniais, infra estruturais e emergenciais dos eventos.
De lá, após extraí-los, por meio da biblioteca Pandas, no ambiente de execução da Google Colab, a equipe checou o schema e a tipagem das colunas, bem como a presença e o número de valores nulos.
Seguindo, nós conferimos os valores das colunas individualmente, utilizando, entre outros recursos, os métodos pd.unique(), sorted() e df.loc[].
Nessa conferência, identificamos a possibilidade de dropagem de algumas colunas: ‘indicator’,’País_ESTANDAR’,’unit’,’notes_id’ e ‘source_id’, ato que foi realizado. No caso das quatro últimos colunas citadas, isso se deveu ao fato de não apresentarem informações relevantes para nós, seja porque eram colunas de controle, seja porque só possuíam valores NaN. Já no caso de ‘indicator’, havia outra coluna ‘Indicador__Desastres_Naturales’ com o mesmo tipo de informações, porém mais completas.
Durante a conferência, verificamos, ainda, algumas possíveis inconsistências: na coluna 'Años__ESTANDAR’ faltava o ano de 1993 e nas colunas ‘value’ haviam valores muito altos, tais como 27000000, 4000000 e 10000000. No primeiro caso, não houve problema, pois definimos previamente que nossa análise abrangeria o período de 2000 a 2022. Já no segundo, verificamos o tipo de indicador a que esses valores se referiam e constatamos que eram sobre pessoas afetadas (somatório de pessoas que ficaram feridas, tiveram algum tipo de dano patrimonial, ficaram desabrigadas, etc.), o que, embora sejam números altos, torna-os críveis.
Em seguida, tendo já realizado a dropagem das colunas que não precisaríamos, renomeamos as colunas restantes, já com nomenclaturas em Português do Brasil, da seguinte forma: 'Tipo de desastre' - 'tp_desastre', 'Indicador__Desastres_Naturales' - 'indicador','Años__ESTANDAR' - 'ano', 'value' - 'qtde’; tomando o cuidado de obedecer às convenções de boas práticas de nomenclatura (nomes em minúscula, sem espaços ou símbolos especiais, entre outros).
Após, traduzimos os valores das colunas de tipo string (indicador e tp_desastre) do Espanhol para o Português do Brasil, nessa ordem, conforme a relação: 'Personas afectadas' - 'Pessoas afetadas', 'Perdidas Humanas' - 'Perdas humanas’, 'Tormentas' - 'Tempestade', 'Inundaciones' - 'Inundação', 'Desplazamiento de masa húmeda' - 'Deslizamento de terra', 'Sequías' - 'Seca', 'Incendios' - 'Incêndio’. Vale ressaltar que determinados valores, tais como ‘Número de desastres’ não precisaram ser alteradas, pois a grafia em Espanhol e em Português do Brasil é a mesma.
Por fim, realizamos o cast da coluna ‘ano’, que originalmente estava tipada como int64, para datetime, a fim de facilitar a análise e a inserção dos dados no LookerStudio.
A exemplo dos demais datasets, o arquivo original foi enviado para a Google Cloud Storage (GCS) e para um servidor MySql, também hospedado na Google Cloud Platform (GCP).
De lá, após extraí-los, por meio da biblioteca Pandas, no ambiente de execução da Google Colab, a equipe checou o schema e a tipagem das colunas, bem como a presença e o número de valores nulos.
Seguindo, nós conferimos os valores das colunas individualmente, utilizando, entre outros recursos, os métodos pd.unique(), sorted() e df.loc[].
Nessa conferência, identificamos a possibilidade de dropagem de algumas colunas: ‘indicator’,’País_ESTANDAR’,’unit’,’notes_id’ e ‘source_id’, ato que foi realizado. No caso das quatro últimos colunas citadas, isso se deveu ao fato de não apresentarem informações relevantes para nós, seja porque eram colunas de controle, seja porque só possuíam valores NaN.
Durante a conferência, verificamos, ainda, algumas possíveis inconsistências: na coluna 'Años__ESTANDAR’ faltavam os anos de 1972, 1976 e 1993 e na coluna ‘value’ havia valores zerados. No primeiro caso, não houve problema, pois definimos previamente que nossa análise abrangeria o período de 2000 a 2022. Já no segundo, os valores se referiam a anos em que houve desastres, de modo que não é possível que não tenha havido gastos. Desse modo, optamos por excluir esses registros.
Em seguida, tendo já realizado a dropagem das colunas que não precisaríamos, renomeamos as colunas restantes, já com nomenclaturas em Português do Brasil, da seguinte forma: 'Tipo de desastre' - 'tp_desastre', 'Años__ESTANDAR' - 'ano', 'value' - ‘custo’; tomando o cuidado de obedecer às convenções de boas práticas de nomenclatura (nomes em minúscula, sem espaços ou símbolos especiais, entre outros).
Após, traduzimos os valores das colunas de tipo string (tp_desastre) do Espanhol para o Português do Brasil, do seguinte modo: ''Relacionados con Cambio Climático' - 'Relacionados com mudanças climáticas’. Vale ressaltar que determinados valores, tais como ‘Geofísicos’ não precisaram ser alteradas, pois a grafia em Espanhol e em Português do Brasil é a mesma.
Por fim, realizamos o cast da coluna ‘ano’, que originalmente estava tipada como int64, para datetime, a fim de facilitar a análise e a inserção dos dados no LookerStudio.
Já com os todos os datasets tratados e padronizados de acordo com as escolhas do grupo enviamos cada um para o bucket, o BigQuery e para um banco de dados no Mongo DB.
No caso do Mongo DB foi necessário o uso de 3 contas para o envio do dataset de clima, pois o tamanho dele excedia a capacidade de armazenamento da cluster disponível na versão gratuita do serviço. Após testes percebemos que ele adicionava no máximo 1.050.000 documentos. Dessa forma as duas primeiras contas têm essa quantidade e a terceira 583795, totalizando 2.683.795 documentos que corresponde ao número de linhas no DF final.
Além disso particionamos o dataset em diversas partes pois ao tentar envia-lo inteiro excedíamos a RAM e dava um erro. Para isso foi criado um laço de repetição que criava o código necessário para, à partir do DF inteiro, criar um DF menor a cada intervalo de 50.000 linhas. Também foi criado outro laço de repetição para criar o código necessário para transformar esses DF’s já divididos em dicionários e envia-los à coleção no MongoDB.
Os certificados para acesso às contas utilizadas encontram-se aqui.
Concluídos os tratamentos, passamos para a etapa de análise dos dados. Nosso questionamento inicial era quais foram as alterações nos indicadores climáticos do Brasil no período de 2000 a 2022. Desse desdobramento, surgiram outros:
- Qual a relação entre umidade, temperatura e precipitação?
- Houve eventos extremos? Se sim, quais as possíveis causas?
- Os desastres naturais têm relação com as mudanças nos indicadores climáticos observados? Se sim, quais?
- Qual o prejuízo financeiro dos desastres que aconteceram nesse período?
- Os indicadores de emissão de CO2 relacionam-se com os indicadores climáticos?
- Qual a relação entre umidade e queimadas?
- De que forma a produção agrária foi afetada pelas variações de precipitação e temperatura?
Orientados pelas questões, iniciamos a análise dos dados. Essa etapa foi realizada com o auxílio da biblioteca Pandas, de queries no BigQuery (Google Cloud Platform) e de gráficos no LookerStudio, esse último tendo sido usado também para a visualização final de nossos dados.
Nossas primeiras análises se concentraram nos indicadores climáticos gerais do Brasil (velocidade dos ventos, temperatura, precipitação e umidade) no período de 2000 e 2022. Dessa análise pudemos extrair que:
- À primeira vista, houve certa variação na linha de temperatura média, para a série histórica, com anos mais ou menos quentes, porém há uma tendência de crescimento. Tais quedas de temperatura concentram-se em períodos em que houve fenômenos climáticos atípicos, tais como entre os anos de 2019 a 2021, marcados pela ocorrência do La Niña (arrefecimento das temperaturas do oceano Pacífico, que provoca a formação de massas de ar frio);
- Em oposto à temperatura, a velocidade média dos ventos diminuiu ao longo dos anos, possivelmente porque, em temperaturas mais altas, a velocidade dos ventos tende a ser menor (o ar quente é mais pesado, logo mais lento);
- A umidade e a temperatura médias para o período mantiveram-se amenas, em torno de 68% para a umidade e de 23ºC para a temperatura. Tais valores são coerentes, tendo em vista que a cada 1ºC de aumento de temperatura, aumenta-se, em média, 7% a umidade
O total gasto dentro da GCP foi R$ 229,28. Consideramos um valor razoável, uma vez que nesse valor está incluso todos os requisitos do projeto e também a hospedagem de website criado pelo grupo.
Porém otimizações que poderiam ser feitas é a realização de alguns testes em conta separada, pois nem todos foram feitos dessa forma, e o carregamento para o MySQL apenas dos dados tratados pois o volume de dados seria menor e consumiria menos espaço e processamento.
https://climateknowledgeportal.worldbank.org/country/brazil/extremes
http://www.fbds.org.br/cop15/FBDS_MudancasClimaticas_EN.pdf
https://www.preventionweb.net/news/extreme-weather-and-climate-events-brazil
https://portal.inmet.gov.br/uploads/notastecnicas/Aquecimento_v2-_m_2022-02-01-191552_mvwb.pdf
http://www.cprm.gov.br/publique///Mapas-e-Publicacoes/Atlas-Pluviometrico-do-Brasil-1351.html
http://climanalise.cptec.inpe.br/~rclimanl/boletim/cliesp10a/chuesp.html
https://edisciplinas.usp.br/pluginfile.php/4250725/mod_resource/content/1/umidade do ar.pdf
https://uc.socioambiental.org/pt-br/noticia/180861
https://www.istoedinheiro.com.br/mudanca-climatica-ampliou-eventos-climaticos-extremos-em-2014/
https://mundoeducacao.uol.com.br/geografia/influencia-el-nino-no-brasil.htm
https://revistas.ufrj.br/index.php/aigeo/article/view/27682
http://climanalise.cptec.inpe.br/~rclimanl/revista/pdf/30anos/Coelhoetal.pdf