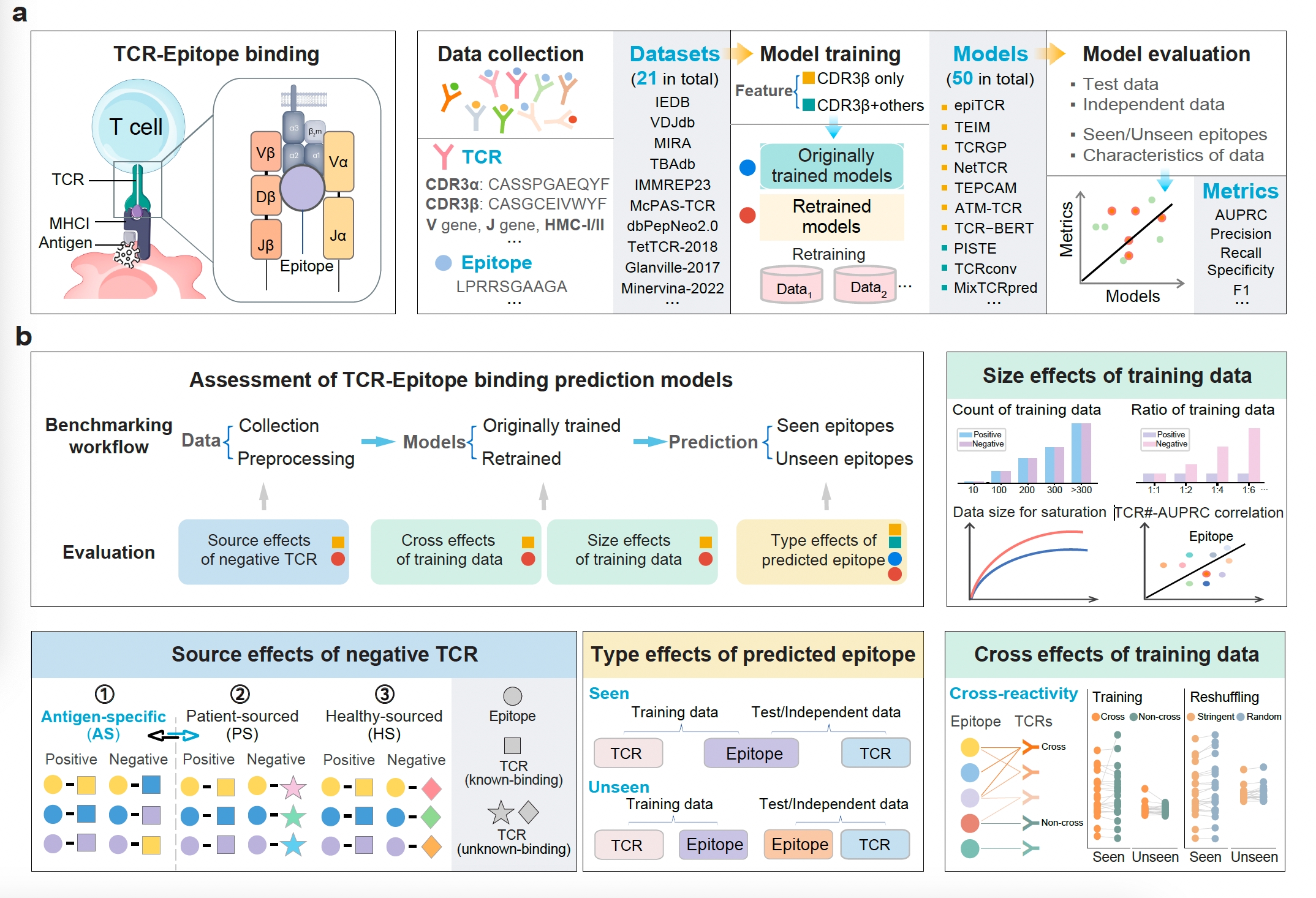
In this study, we conducted a comprehensive evaluation of TCR-epitope binding prediction models, focusing on their performance in both seen and unseen epitope scenarios and identifying key factors that influence model performance.
There are three modules for each model: (1)original model-based prediction, (2)model retraining, and (3)retrained model-based prediction on both seen and unseen data. You can select either to retrain the model or to generate predictions depending on your requirements. The relevant code for each model, contained in a Jupyter notebook, is saved in a separate folder with a file name that matches the model's name. Additionally, we provide the scripts for preprocessing all original datasets (Note: If the model does not provide the original data or the original trained model, we will directly start retraining from Module 2. If the model does not provide the training code, then we only include the original model prediction of Model 1).
You need to create a separate environment for each model as these models are based on different Python framework and packages. During model evaluation, we configured a separate environment for each model according to the requirements file provided in its GitHub repository. All environments were stored in the environment folder for easy access. The time required to configure the environment depends on factors such as the number of model dependencies, network speed, and hardware performance.
The model input should be a CSV file with the following format:
#1.CDR3β
Epitope,CDR3B,Affinity
#2.CDR3β+others
CDR3A,CDR3B,Epitope,Affinity,TRAJ,TRBJ,TRBV,TRAV,MHC,LongB,LongA
Where the epitope and CDR3B(TCR) are protein sequences and binding affinity is either 0 or 1.
# 1.Example(CDR3β)
Epitope,CDR3B,Affinity
GLCTLVAML,CASSEGQVSPGELF,1
GLCTLVAML,CSATGTSGRVETQYF,0
# 2.Example(CDR3β+others)
CDR3A,CDR3B,Epitope,Affinity,TRAJ,TRBJ,TRBV,TRAV,MHC,LongB,LongA
CGRGGSNYKLTF,CASSTSTGQFSGANVLTF,AGSGIIISD,1,TRAJ53*01,TRBJ2-6*01,TRBV19*01,TRAV8-6*01,HLA-DQA1*01:02/DQB1*06:02,DGGITQSPKYLFRKEGQNVTLSCEQNLNHDAMYWYRQDPGQGLRLIYYSQIVNDFQKGDIAEGYSVSREKKESFPLTVTSAQKNPTAFYLCASSTSTGQFSGANVLTFGAGSRLTVL,AQSVTQLDSQVPVFEEAPVELRCNYSSSVSVYLFWYVQYPNQGLQLLLKYLSGSTLVESINGFEAEFNKSQTSFHLRKPSVHISDTAEYFCGRGGSNYKLTFGKGTLLTVNP
CAGQLAQGGSEKLVF,CSGAPWGTSGRSETQYF,AGSGIIISD,1,TRAJ57*01,TRBJ2-5*01,TRBV20-1*01,TRAV35*01,HLA-DQA1*01:02/DQB1*06:02,GAVVSQHPSWVICKSGTSVKIECRSLDFQATTMFWYRQFPKQSLMLMATSNEGSKATYEQGVEKDKFLINHASLTLSTLTVTSAHPEDSSFYICSGAPWGTSGRSETQYFGPGTRLLVL,GQQLNQSPQSMFIQEGEDVSMNCTSSSIFNTWLWYKQEPGEGPVLLIALYKAGELTSNGRLTAQFGITRKDSFLNISASIPSDVGIYFCAGQLAQGGSEKLVFGKGTKLTVNP
If your data is unlabeled and you are only interested in the function of prediction, simply fill the ‘Affinity’ column with either 0 or 1. The performance statistics can be ignored in this case and the predicted binding affinity scores can be collected from the output files.We have provided all the datasets used in the article. You can download them by visiting this link (https://doi.org/10.6084/m9.figshare.27020455) and accessing the 'data' folder.
The code for making predictions using original models has been encapsulated into a function named Original_model_prediction. You can directly call this function in the first module of the Jupyter notebook within the respective model folder. As an illustration, the original ATM-TCR model can be used with the following code snippet (Both the CDR3β and CDR3β+others models use the following processing methods):
testfile_path="../data/test.csv"
modelfile_path="../Original_model/ATM_TCR.ckpt"
result_path="../result_path/Original_model_prediction"
Original_model_prediction(testfile_path,modelfile_path,result_path)
Except for the ATM_TCR model, the other original models have been uploaded to the figshare website. You can download them by visiting this link (https://doi.org/10.6084/m9.figshare.27020455) and navigating to the 'Original_model' folder under the 'models' folder.
We have refactored the training and testing code for each model into a function named Model_retraining. You can directly call this function in the second module of the Jupyter notebook within the respective model folder. As an illustration, the ATM-TCR model can be retrained using the following code snippet (Both the CDR3β and CDR3β+others models use the following processing methods):
trainfile_path ="../data/train.csv"
testfile_path="../data/test.csv"
save_model_path="../Retraining_model/ATM_TCR.ckpt"
result_path="../result_path/Retraining_model_prediction"
Model_retraining(trainfile_path,testfile_path,save_model_path,result_path)
If you want to use your own trained model for prediction, you can call the Retraining_model_prediction function in the third module of the Jupyter notebook. As an illustration, the retrained ATM-TCR model can be used with the following code snippet (Both the CDR3β and CDR3β+others models use the following processing methods):
testfile_path="../data/Validation.csv"
modelfile_path="../Retraining_model/ATM_TCR.ckpt"
result_path="../result_path/Retraining_model_prediction"
Retraining_model_prediction(testfile_path,modelfile_path,result_path)
We have uploaded the retrained models to the figshare website. You can download them by visiting this link (https://doi.org/10.6084/m9.figshare.27020455) and accessing the 'Retrained_model' folder within the 'models' folder.
The prediction results of each model are stored in the result_path directory, comprising the columns Epitope, CDR3B,y_true, y_pred, and y_prob. Here, y_prob represents the predicted probability of TCR binding to the epitope, and y_pred indicates the binding status (“1”-binding, “0”-not binding) based on the probability. If y_prob is greater than or equal to 0.5, y_pred is set to 1; otherwise, y_pred is set to 0 (Both the CDR3β and CDR3β+others models output the following content).
# Example
Epitope,CDR3B, y_true, y_pred, y_prob
GLCTLVAML,CASSEGQVSPGELF,1,1,0.89
GLCTLVAML,CSATGTSGRVETQYF,0,1,0.68
If you already know the actual TCR and epitope binding labels, you can calculate the model prediction accuracy using the Jupyter notebook file named Evaluation_metrics_calculation . You can directly call the calculate function from that file using the following code snippet (Both the CDR3β and CDR3β+others models use the following processing methods):
data_path="../result_path/predition.csv"
result_path="../result_path/predition"
column='epitope'
calculate(data_path, result_path, column)
Note: Due to code permission issues, the models DLpTCR-FULL, DLpTCR-CNN, and DLpTCR-RESNET can only be accessed and used via the GitHub repository (https://github.com/JiangBioLab/DLpTCR/); the models PiTE−epiSplit, PiTE−tcrSplit and PiTE can only be accessed and used via the GitHub repository (https://github.com/Lee-CBG/PiTE); the models vibtcr and vibtcr-AB can only be accessed and used via the GitHub repository (https://github.com/nec-research/vibtcr); the model pMTnet can only be accessed and used via the GitHub repository (https://github.com/tianshilu/pMTnet); the model pMTnet−omni can only be accessed and used via the GitHub repository (https://github.com/Yuqiu-Yang/pMTnet_Omni_Document); the model MixTCRpred can only be accessed and used via the GitHub repository (https://github.com/GfellerLab/MixTCRpred); the model PanPep can only be accessed and used via the GitHub repository (https://github.com/bm2-lab/PanPep); Since the TCRfinder model does not provide a LICENSE, it can be accessed from https://zhanggroup.org/TCRfinder.