raw sensor data -> feature engineering -> diff dataset -> LSTM training -> rolling forecast
受企业数据保密要求限制,项目所涉及的原始数据集及中间数据产物不予公开;本文仅围绕技术方案、建模流程与工程实现进行讨论。
本项目面向化工行业碳化塔工艺,核心目标是对碳化取出液温度进行未来30分钟的滚动预测,并基于预测残差实现设备异常预警与预测性维护。
碳化塔是氨碱法生产纯碱的核心设备,其取出液温度直接反映塔内反应热平衡状态。温度异常波动往往意味着冷却系统效率下降、进气配比失衡或塔内结垢等潜在故障。传统DCS系统仅提供实时监测与固定阈值报警,无法实现趋势预判。
项目采用Seq2Seq思路,将工业传感器历史上下文映射到未来状态变化,通过直接多步预测学习设备运行趋势,从而实现对设备劣化趋势的提前感知
- 时间跨度:1个月连续运行数据(约30天)
- 原始采样频率:2秒/点,单变量约100万行,总数据量1300万条
- 降采样后:1分钟/点,单变量约43,200行
- 数据格式:工业DCS系统导出的CSV,以
|或,分隔,包含时间戳、质量戳、数据值等字段
项目经历了两次关键的数据集扩充:
第一阶段(5变量): 最初仅使用5个基础测点:出口尾气压力、CO2进气压力、碳化取出液温度(目标)、反应段中部温度、液位。
第二阶段(16变量): 发现5个变量与目标温度均为同步相关(Lag=0),缺乏物理上的"先行预告牌",导致模型预测存在滞后。遂扩充至覆盖碳化塔完整工艺闭环的16个测点:
| 类别 | 变量名 | 物理意义 |
|---|---|---|
| 进气系统 | CO2气进气压力 | 反应驱动力 |
| 反应系统 | 反应段中部温度 | 反应进程指示 |
| 进料系统 | 进塔氨母液II流量/阀位 | 进料控制 |
| 进料系统 | 进塔碳氨母液II流量/阀位 | 进料控制 |
| 冷却系统 | 水箱冷却水出口温度 | 换热效率 |
| 冷却系统 | 冷却水压力 | 冷却系统状态 |
| 出料系统 | 取出液流量 | 出料负荷 |
| 目标变量 | 碳化取出液温度 | 被预测对象 |
| 调控变量 | 碳化取出液温度调节阀阀位 | 温控执行机构 |
| 辅助变量 | 液位、出口尾气压力 | 塔内状态 |
关键决策:剔除3个"累计流量"变量(单调递增,无动态信息),实际入模13个有效特征 + 1个目标。
工业现场数据存在典型的"脏数据"陷阱,本项目逐一攻克:
| 问题类型 | 现象 | 解决方案 |
|---|---|---|
| 质量戳误读 | DCS质量戳192被误读为温度值,导致全列均值192°C |
智能识别datavalue列,剔除dataquality列 |
| 死值(冻结值) | 传感器通讯中断时,系统保持最后一次有效值不变 | 检测连续N个采样点数值完全一致,强制置为NaN |
| 时间戳对齐 | 多传感器采样时刻存在秒级偏差 | 外连接(Outer Join)+ 前向填充 + 1分钟重采样 |
| 时区问题 | 时间戳带+08:00时区信息 |
统一剥离时区,转为本地时间索引 |
初始思路:将传感器历史窗口作为模型输入,尝试通过序列建模方式预测未来温度曲线。
遇到的瓶颈:
- 工业数据是连续浮点数,自回归预测容易出现误差累积
- 1个月数据对大规模深度模型相对单薄,易过拟合
- 直接预测逐步未来值时,多步预测误差容易放大
结论:序列建模思想可用,但必须针对工业时序的连续性、物理惯性、噪声特性做深度改造。
在确定最终架构前,对四种技术路线进行了充分论证:
| 流派 | 代表模型 | 优势 | 劣势 | 本项目适用性 |
|---|---|---|---|---|
| 机器学习回归 | XGBoost/LightGBM | 小数据王者、训练极快、可解释性强 | 无法输出连续预测曲线、丢失时序微观形态 | 可作为基线,但非主模型 |
| 深度时序专有 | TCN / PatchTST | 并行计算快、长程依赖强 | 数据量要求大、调参复杂 | 数据量足够后可升级 |
| 异常检测专修 | Autoencoder | 无需预测未来,直接检测异常 | 无法提供"未来趋势"的前瞻性提示 | 仅作辅助 |
| LSTM直接多输出 | Direct Multi-Step LSTM | 一次性输出30分钟曲线、避免自回归误差累积、工业案例丰富 | 对突变响应存在滞后 | 最终选择 |
最终决策:采用 LSTM直接多输出架构 作为基线模型,理由:
- 30天分钟级数据(约4,000+滑动窗口样本,[43200x14])足以支撑LSTM训练
- 工业DCS系统对LSTM的部署和解释成本最低
- 通过后续特征工程和损失函数改造,可弥补LSTM对突变响应慢的缺陷
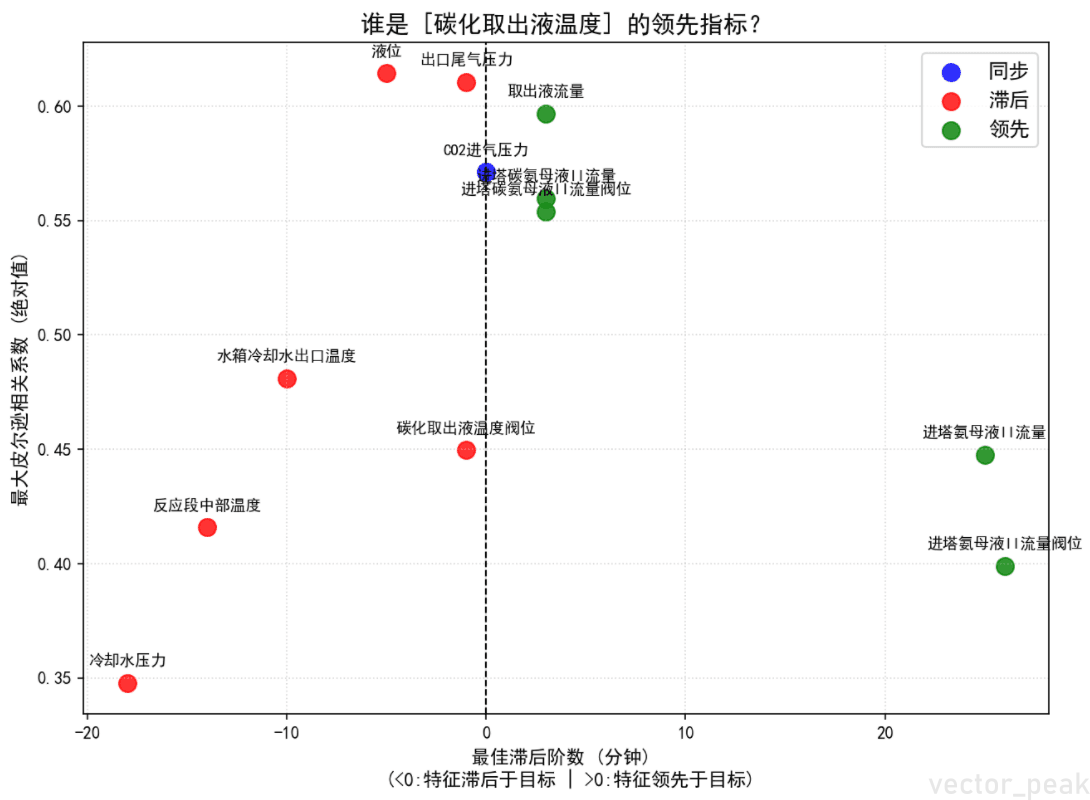
核心发现:Step 2滞后相关性分析显示,所有变量与目标温度的最大相关性均在Lag=0(同步),无明显的物理领先指标。
根因:碳化塔是大惯性系统,物理延迟在秒级,经1分钟降采样后被抹平;且稳态运行占比过高。
解决方案——动量特征注入:
- 为每个原始特征构造 1分钟变化率(diff1) 和 3分钟变化率(diff3)
- 将特征维度从13维扩展至 39维(13原始 + 13_diff1 + 13_diff3)
- 物理意义:即使绝对值同步,"变化率"仍可能提前预示趋势转折(如阀门开度微调→流量变化→温度响应)
关键创新:不预测未来30分钟的绝对温度,而是预测温度变化量(差分)。
传统方案:输入[历史30分钟] → 预测[未来30分钟绝对温度]
本方案: 输入[历史30分钟] → 预测[未来30分钟温度每分钟变化多少]
优势:
- 剥离基线漂移负担(不同批次、季节的温度基线不同,但物理响应规律相同)
- 模型专注学习"扰动响应"而非"记忆当前温度"
- 还原公式:$T_{future} = T_{current} + cumsum(\Delta \hat{y})$
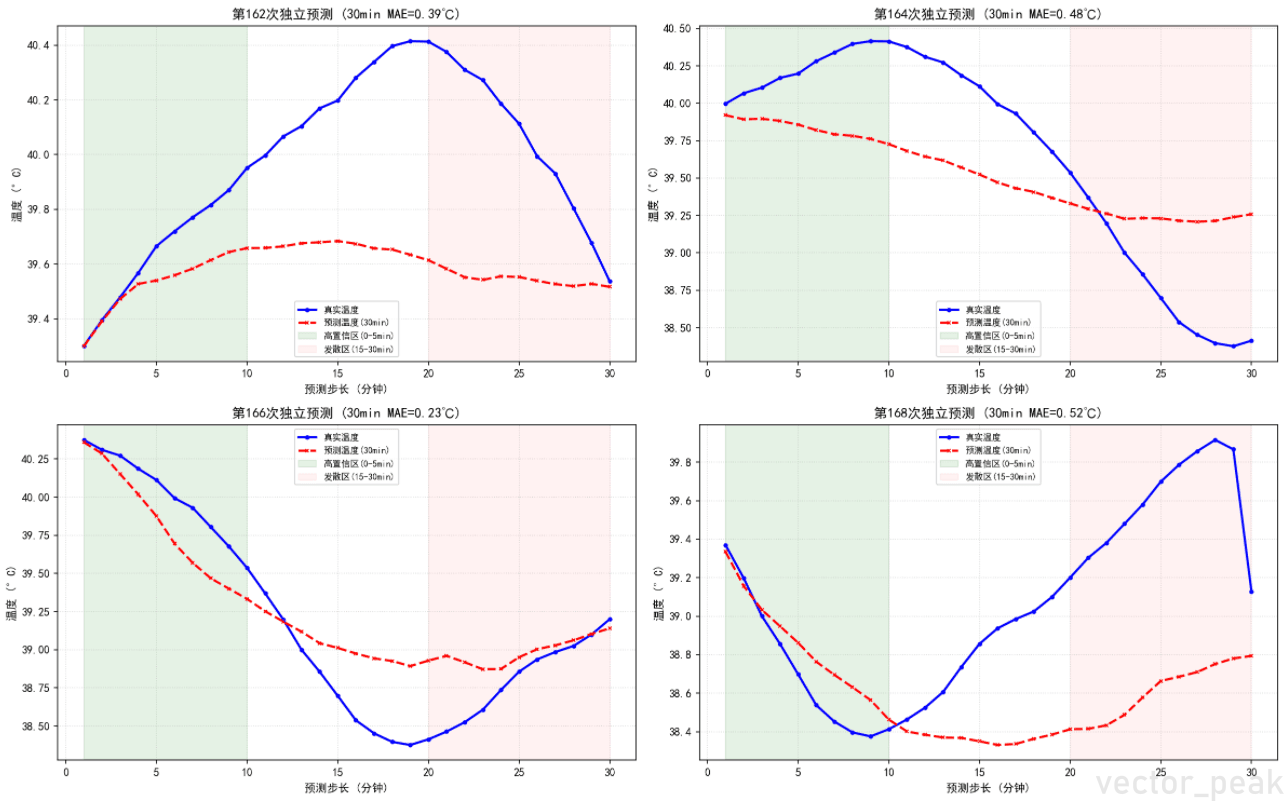
第一次训练(MSE/Huber Loss):
- 稳态段预测完美,但瞬态段(温度骤降)严重滞后
- 模型倾向于预测"安全的平均值"(回归平均化效应)
第二次训练(引入差分损失 TrendAwareLoss):
- 不仅惩罚"温度值不准",更惩罚"温度变化趋势(斜率)不准"
- 逼迫模型在温度急跌时,必须跟上波形的陡峭程度
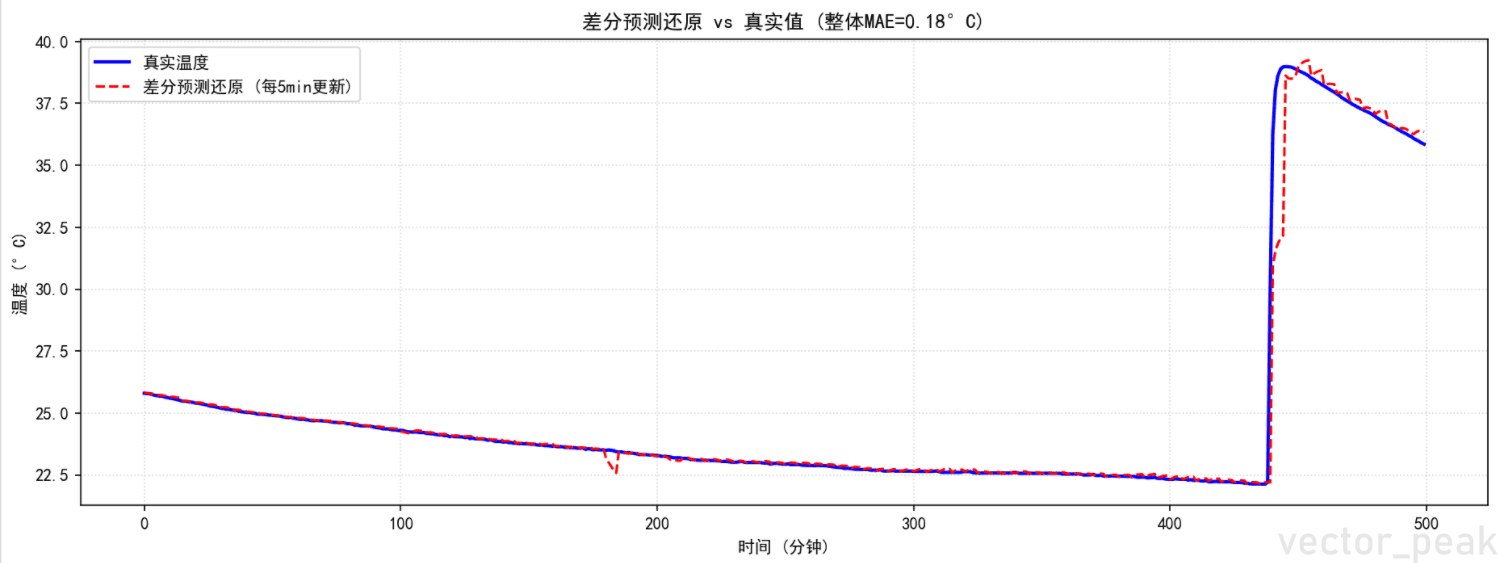
原始评估方式(每5分钟画一条独立预测线)导致操作工无法直观对比预测与真实值。
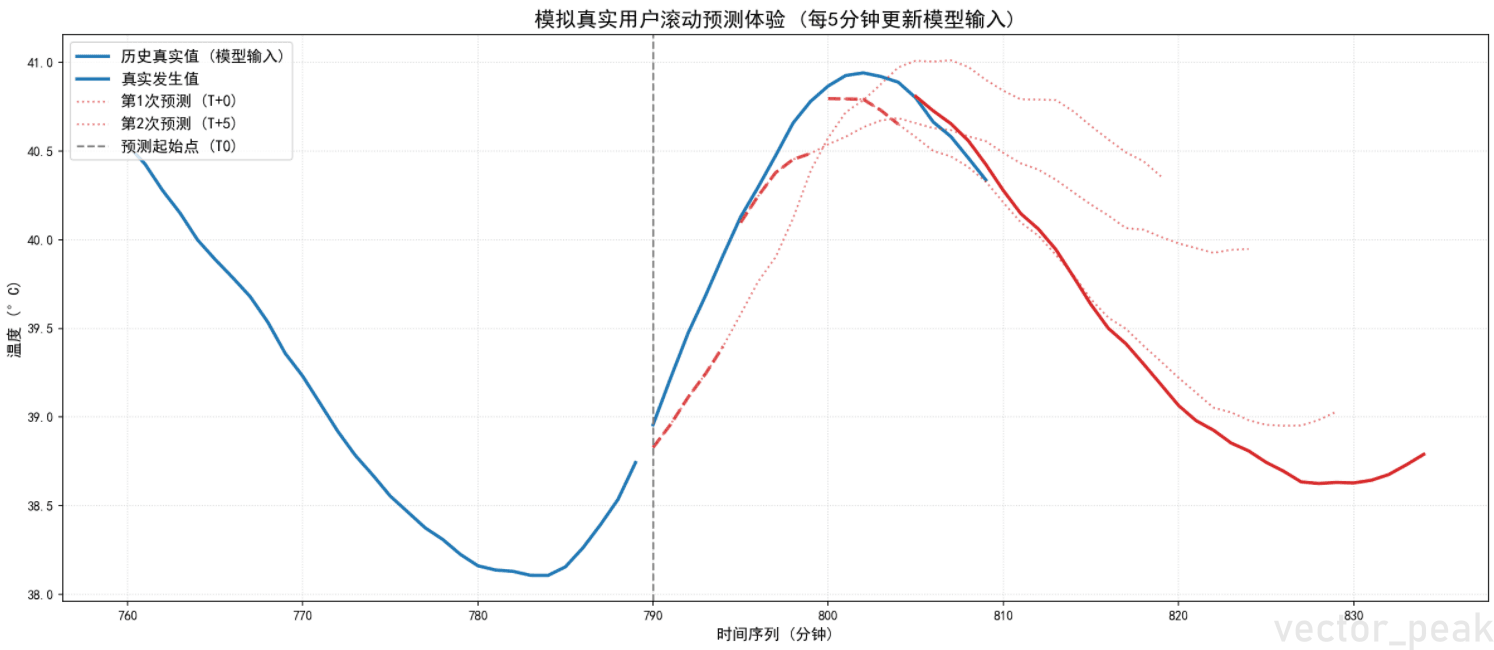
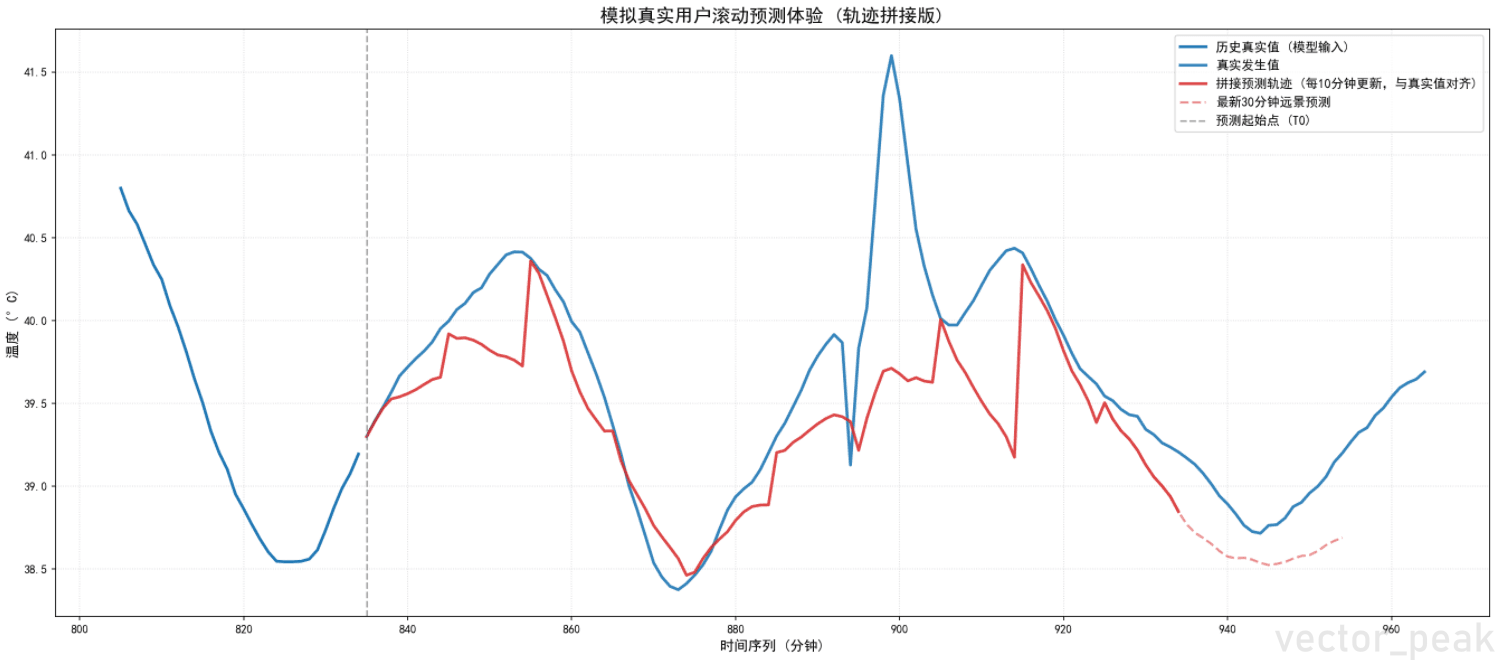
创新——轨迹拼接法:
- 每次推理输出30分钟预测,但只取前
ROLL_STRIDE分钟(如10分钟)作为"可信段",最终项目使用时,单次预测三十分钟,但是每过十分钟重新预测并更新预测曲线 - 将多段可信段按时间轴首尾拼接,形成一条与真实值完全对齐的连续预测曲线
- 剩余未验证段以虚线展示为"远景预测"
运行结果
最终效果
局部MAE评估
【上线模式】滚动预测 (每10分钟更新) 整体指标: MAE (平均绝对误差): 0.2592 ℃
原始CSV (16变量, 2秒采样, 100万行/变量)
│
▼
Step 1: 数据清洗与宽表合并
├── 智能识别 datavalue 列(规避192质量戳陷阱)
├── 死值检测与NaN替换(连续5点不变则冻结)
├── 时间戳对齐 + 1分钟降采样(均值聚合)
└── 输出: merged_wide_table.parquet (43,200行 × 14列)
│
▼
Step 2: 领先指标挖掘与特征筛选
├── 计算13个特征对目标变量的 -30~+30分钟滞后相关性
├── 剔除滞后指标(Lag<0)和弱相关(|corr|<0.35)
├── 发现全部特征均为同步/弱相关 → 启动动量特征工程
└── 输出: feature_config.json (特征→滞后阶数映射)
│
▼
Step 3: 动量增强与数据集构造
├── 注入 diff1 / diff3 动量特征 (13维 → 39维)
├── 按配置平移特征列(防数据泄露)
├── 时序切分: 训练(14天) | 验证(2天) | 演示(7天)
├── Z-score标准化(仅训练集统计量)
└── 滑动窗口切分: 输入[30,39] → 输出[30] (步长5分钟)
│
▼
Step 4: 直接多输出LSTM训练
├── 模型: LSTM(39→64→30) + Linear(64→30)
├── 损失: TrendAwareLoss (绝对值 + 差分趋势双惩罚)
├── 优化: Adam + ReduceLROnPlateau + 早停(EarlyStopping)
└── 输出: best_lstm_model.pth
│
▼
Step 5: 差分还原与滚动评估
├── 加载标准化参数 → 反标准化 → cumsum还原绝对温度
├── 轨迹拼接: 每10分钟取可信段,拼成连续预测线
├── 指标: MAE、RMSE(真实物理单位℃)
└── 可视化: 历史真实值 + 拼接预测轨迹 + 远景虚线
| 场景 | 预测 horizon | 误差指标 | 价值解读 |
|---|---|---|---|
| 稳态运行 | 未来30分钟 | MAE ≈ 0.16°C | 预测曲线与真实曲线几乎重合,可用于趋势确认 |
| 瞬态波动 | 未来30分钟 | MAE ≈ 2.06°C | 能捕捉趋势方向,但存在轻微滞后,可用于劣化预警 |
| 长程发散 | 15-30分钟 | MAE逐渐增大 | 越远预测越保守,符合物理不确定性规律 |
-
从"事后报警"到"事前预警"
- 传统DCS:温度超限才报警(已发生损失)
- 本系统:提前30分钟预测温度走势,在偏离初期即触发预警
-
动态残差异常检测
- 正常运行时,预测残差在0附近随机波动
- 设备劣化时,残差呈现系统性同向偏移(如连续5分钟预测值系统性高于真实值)
- 基于残差分布的动态阈值(μ±3σ)报警,避免固定阈值误报
-
DCS组态画面集成
- 蓝色实线:历史真实温度
- 红色实线:已验证的拼接预测轨迹(每10分钟更新)
- 红色虚线:最新30分钟远景预测
- 操作工可直观看到"系统认为未来会怎么变"
-
工艺优化辅助
- 通过分析阀门开度-温度响应的滞后关系,优化PID控制参数
- 识别冷却水压力波动对温度的影响时滞,指导设备维护周期
受企业数据保密要求限制,项目所涉及的原始数据集及中间数据产物不予公开;本文仅围绕技术方案、建模流程与工程实现进行讨论
industrial_predictor/
├── raw_data/ # 原始16变量CSV文件
│ ├── A-1CO2气进气压力.csv
│ ├── A-1出口尾气压力.csv
│ ├── A-1反应段中部温度.csv
│ ├── ...
│ └── A-1碳化取出液温度.csv # 目标变量
│
├── processed_data/ # Step 1 中间输出(单变量降采样后)
│ ├── CO2进气压力.parquet
│ ├── 出口尾气压力.parquet
│ └── ...
│
├── merged_data/ # Step 2 输出
│ └── merged_wide_table.parquet # 14列宽表(13特征 + 1目标)
│
├── config/ # 配置与参数
│ ├── feature_config.json # Step 2: 特征滞后配置
│ ├── norm_params.json # Step 3: Z-score标准化参数
│ └── lag_correlation_plot.png # Step 2: 滞后相关性可视化
│
├── dataset/ # Step 3 输出(模型可直接读取)
│ ├── train_data.npz # 训练集 (X, Y)
│ ├── val_data.npz # 验证集 (X, Y)
│ └── demo_data.npz # 演示集 (X, Y)
│
├── models/ # Step 4&6 输出
│ ├── best_lstm_model.pth # 最优模型权重
│ ├── loss_curve.png # 训练Loss曲线
│ └── prediction_vs_real.png # 预测效果对比图
│
├── step1_merge_16_vars.py # 数据清洗与宽表合并(修复datavalue识别)
├── step2_feature_selection_lag_correlation.py # 滞后相关性分析与特征筛选
├── step3_dataset_diff_prediction.py # 滑动窗口切分与标准化
├── step4_model_training.py # LSTM直接多输出训练
├── step5_rolling_evaluation.py # 差分还原、滚动评估与可视化
│
└── README.md # 本文件
- 工业数据预处理占70%工作量:质量戳识别、死值清洗、时间对齐,每一步都决定模型上限
- 没有领先指标时,创造动量指标:当物理延迟被采样频率抹平,变化率(diff)是最后的"先知"
- 差分预测是工业大惯性系统的最优解:预测"变化"比预测"绝对值"更符合物理直觉
- 损失函数决定模型性格:MSE让模型保守,Huber+差分Loss让模型敏锐
- 可视化必须服务于操作工:轨迹拼接的连续曲线,比离散的预测条带更有工程价值