I plan to fill this section with what I discovered today - - - AFAP (As Frequently as possible)! These notes are best viewed with MathJax extension in chrome.
"One day I will find the right words, and they will be simple." - Jack Kerouac
"Youth is wasted on the young. Take control! NOW!" - George Bernard Shaw
"Simplicity is Beautiful" - Juergen Schmidhuber
April 5, 2019
msc
- Preparing training data for matrix profile training: subproblem:
- Your network is supposed to find the frame which had the minimum distance to your frame
- Maybe learning weights of a 3D convnet using the matrix profile makes more sense for end to end learning.
- With filters of depth = the length of the entire sequence.
- Or better, just convolutions to the frames! and feeding this to an LSTM for counting class assignment!
April 1,2019
algorithm
- It means find the number which has the same set of digits but is greater than the given number. Link
- Clever tricks: Start iterating from back see if you find a number less than the previous number. Number = 5234976 - Found = 523[4]976
- If you don't, it means the number is the greatest possible number.
- If you do, replace it with the smallest number on it's right. 523[6]97[4]
- And then, ascending sort the numbers on the right! 523[6]479
- You've found the your number 😄
- Python union and intersection: Can't be done with
andandor!set3 = set1.union(set2)is the same asset1 | set2set3 = set1.intersection(set2)
March 27, 2019
algorithm
-
The Dijkstra's algorithm:
-
The
$A^*$ algorithm:
March 26, 2019
algorithm
- One is keep a heap of the first elements from all arrays!
- Better solution:
- Look at the middle element(m) in the largest array, and binary search it's index(i) in all other arrays.
- All elements on the left of that index are less than m and on the right are greater than m.
- See if i1 + i2 + .. == k or < k and based on that update the lists (get rid of elements less than i1, i2 etc. in arrays 1, 2 etc.)!
- Also update k = k - (i1 + i2 + i3)
- Recurse!
- Crazy solution! 💣
- Square matrix ? Think in terms of quad trees! (Split the array in 4 parts!).
- Trap water: Keep track of the left max and right max
- Iterate from the direction whichever is smaller! And keep adding water based on current value - leftmax (if we iterated left)!
- Elegant as 🦆
- Can also use a stack! Less elegant, but works!
March 25, 2019
algorithm
- Common Ancestor: Bottom up! If both left and right subtrees have one of the children, return the current node! else return None!
- Path to a node: BackTracking! Keep appending items to a passed array (by reference) and remove them if result was not found!
- Reverse a linked list inplace: prev, curr, next
while(curr is not None):next = curr.next,curr.next = prev,prev = curr,curr = next- Recursive solutions:
- Head recursive: First and rest: First
reverse(next)then,first.next.next = first, first.next = None.
- Head recursive: First and rest: First
RECURSION TIP: When going bottom up: Store something in a global variable!- Don't always have to return something!
- Return something only when you need like minimums and maximums! like most DPs!
- Stack for building calculator!
- Building your own regex matcher: DP! Build a table with n number of rows and m columns:
- n = length of string + 1
- m = length of pattern + 1
- Didn't quite understand this one!
- Merge Overlapping intervals:
- sort by the starting index before iterating!
- On each iteration, check if the starting index is less than the end of last element in the return array!
- Brilliant! 💡
- Also solves if the person can attend all the meetings!
- When finding the pair (of times etc.) with minimum difference in an array, consider sorting the array first! Then check adjascent elements only ❤️
- Jump game - Maximum jump from a particular position is given. Minimum jumps required to reach end:
- Keep track of current max-reach and last max-reach!
- In each jump-increment-iteration, iterate from i till last max-reach to update the current max-reach!
- Like BFS!
March 24,2019
algorithm
- Bisect - Binary searching and maintaining an ordered list:
import bisectbisect.bisect_left(a,x)will give location where the current element can be inserted in the array! (Before previous occurances)bisect.bisect_right(a,x)will give location where the current element can be inserted in the array! (After previous occurances)bisect.insort_left(a,x)andbisect.insort_right(a,x)actually adds the element!
- Counter - Dictionary of counts of iterable:
- Usage:
c = collections.Counter("reggae") - other methods:
c.update("shark")orc.subtract("lolol")
- Usage:
- Deque - Stacks and Queues - Python Lists are not optimized to perform
pop(0)orinsert(0, x):- Usage:
d = collections.deque(lst, [maxlen]) - Has methods like:
append, appendleft, pop, popleft - Useful methods like
d.rotate(n)Rotate by n steps,d.count(x)count elements equal to x.
- Usage:
- OrderedDict - List of tuples!
- Supports all dictfunctions too!
- Usage:
od = collections.OrderedDict(d)or can submit a dict sorted on keys/vals - useful method:
od.popitem()removes a(k,v)from the end. Can remove from beginning if argumentFalseis passed to it.
- Python reduce has to be imported:
from functools import reduce - Regex:
import rere.searchwill search anywhere in string,re.matchat the beginning (Useless).re.findallwill try to find all occurances!
March 21,2019
algorithm
- Median from a running list ?
- Maintain two heaps! One for smaller elements and one for larger elements! Their tops will contribute to the median.
- Another approach ? Keep a sorted list! Insertion will be O(logn) and median will be the middle of the sorted list! Same complexity simple solution!
- In place array update ? Use an encoding for different cases! (like substitute 2,3,4 when array can actually have only 0s and 1s).
- 2D Matrix with sorted rows and cols. How to find an element in this ?
- O(m + n) soln: Start looking from top right corner: (row=0, col = m)
- If target is bigger -> discard row
- If target is smaller -> discard column
- 🍋
- O(m + n) soln: Start looking from top right corner: (row=0, col = m)
- Rotating an array in place (by k):
a[:k], a[k:] = a[-k:], a[:k]- Or reverse(reverse(
a[:n-k]), reverse(a[n-k:]))
March 21,2019
algorithm
- Is number(n) a power of 3 ? Without loops/recursions ?
- Find biggest power of 3 which is a valid int! (3^19) (call it
a) - Number is a power if
a%n == 0.
- Find biggest power of 3 which is a valid int! (3^19) (call it
- For power of 4, see if number has 1s at odd bit locations!
1, 100, 10000, ..and prepare a mask like10101010101. - Python
a[::2]will give all elements on even locations anda[1::2]will give all on odd locations.a[::-1]will return the reversed array! 🐯a[::2] = some_slice_of_same_sizeinplace! Isn't Python neat ? 🐍
- Dynamic programming: Always use loops to fill up stuff! Instead of recursion!
- Smaller numbers ahead of each number! Loop back from the end and maintain a BST with counts of how many smaller numbers were encountered at each node.
- Increasing subsequence! - DP again! Check sequences of sizes 1 and then 2 etc.
- Keep iterating, if new element is larger than everything, append! else replace/update an existing item in the list! That's it!
- NOTE: the elements will be incorrect, but the length is correct:
- Dry run the seq:
[8, 2, 5, 1, 6, 7, 9, 3]8 -> [8]2 -> [2]5 -> [2, 5]1 -> [1, 5]6 -> [1, 5, 6]7 -> [1, 5, 6, 7]9 -> [1, 5, 6, 7, 9]3 -> [1, 3, 6, 7, 9]Final answer is the length of this sequence found! (The elements in the sequence are incorrect though!)
- A poorer DP O(n^2) solution also exists:
for i in range(len(A))nestfor j in range(0,i), keep track of all the sequences that end atA[i]
March 20,2019
algorithm
- Maximum Length Subarray: (Kanade's algorithm O(n)) Keep track of global minimum subarray and of minLengthSubarray from the left. if sum is +ve of the subarray, it must be added to the right side!
- Best day to buy/sell stocks is also a version of this problem.
- Sharding : Split database by a key (say city ID). That's it, each shard is a different server. Easier to scale! Boom!
- Hash functions : Mod by the maximum number of positions available!
- Consistent Hash Ring : LoadBalancing/Caching/Cassandra uses it too. Instead of looking for the exact key from the hash function output, store the result in the next address-which is bigger than the key! If all locations are smaller, put it in the first element! Hence the ring 💍!
March 19,2019
algorithm
- When finding longest substring, split on problematic point and recurse!
- When having to use a quad loop, see if two double-loops and a dict can suffice!
- Data structure for O(1) insert delete and randomsample = list + dict with keys as items and values as index locations of those items in the list.
- In a 2D array, if rows and columns are sorted, find top n elements! Create the first row as a heap and keep adding the items from the last used column to it!
heapq.heappush and heapq.heappop - Bits! For a 32 bit integer max number = 0x7FFFFFFF (as if the first bit is 1, the number is negative).
- Why do we need this ? If the final result is greater than this max value, that means the number is negative. First, find the absolute value of this -ve number is found which is always: **IN PYTHON: **
-x = complement(x-1) - And then the pythonic complement is found!
~()which will be the actual negative number!
- Why do we need this ? If the final result is greater than this max value, that means the number is negative. First, find the absolute value of this -ve number is found which is always: **IN PYTHON: **
- Recursively reverse an array! =
rev(arr[l/2:]) + rev(arr[:l/2])
March 18, 2019
- Python since 3.6 has static type checking!
from typing import Dict, List, Tuple, Anya: List[Dict[str, int]] = [{"yellow":10}]- Complex types can also be assigned to other variables!
-
Awesome functions like
.nsmallest(n, iterable)/ .merge(*iterables) -
Use it as:
heapq.heapify(lst) #inplaceThen useheapq.heappush(heap, val)orheappop(heap) -
More python trickery:
print("xyz"*False or "yellow") will print yellow
March 15, 2019
algorithm
- Use 2 dicts to solve this!
- Great Problem
- How to find all possible triplets ?
- Recursively call the function that adds to a global array!
- Append only if the size of the triplet is 3.
- Call the function like merge_sort! without having to return anything!
- If the message exceeds the given max_size, all the messages will be prepended with some text of fixed length!
- Good Problem!
March 11, 2019
algorithm
- This is also known as common child problem. Two strings with deletion allowed, what is the longest list of characters common to both strings (in order ofcourse).
- NP hard problem.
- This has optimal substructure and overlapping subproblems! Enter Dynamic Programming! g4g
- Suppose substrings are lcs(A[:n-1], B[:m-1])
- If the last character is the same, subsequence length = 1 + lcs(A[:n-2], B[:m-2])
- Else it is = max(lcs(A[:n-2], B[:m-1]), lcs(A[:n-1], B[:m-2]))
- Weird Hackerrank bug - when your program times out in
Python3submit the same inPyPy3and see if it runs :|
March 11, 2019
algorithm
- Use List comprehensions (
[x*2 for x in range(256)]) when you need to iterate over the sequence multiple times. - Use Generators (
(x*2 for x in range(256))) (same asyield) when you need to iterate over the sequence once! - xrange uses yielding(generator) and range creates the list. (Python3's range = Python2's xrange)
- Sorting a string in python:
''.join(sorted(a)) - Find all substrings in a string:
- use a nested loop. Inner loop iterating from i to length! (Keep yielding the results)
March 8, 2019
algorithm
- TIP: Don't always think recursively. Think if there is a optimized loop solution possible.
- TIP: Whenever you want parallel execution(inside recursion), think of a queue (like Breadth First Search)!
- Total possible moves by a knight are 8.
- Keep popping elements from this q in a loop.
- For each item popped, add to the q the next possible 8 moves.
- Pythonic: Init a 2D array using array comprehension
[[0]*n for i in range(n)]💣
- Dynamic, High-Level(like Python) JIT compiler and Fast(like C) for scientific computing.
brew cask install julia- GitHub Link
MiniZinc:- Parameters - (Constants that don't change)
int: budget = 1000; - Variables - (Variables that you want to compute)
var 0..1000: a; - Constraints - (Constraints on variables)
constraint a + b < budget; - Solver - (Solve the optimization problem)
solve maximize 3*a + 2*b;orsolve satisfy
- Parameters - (Constants that don't change)
- More MiniZinc Tricks:
enum COLOR = {RED, GREEN, BLUE}then vars can be of typeCOLORlikevar COLOR: a;- To get all solutions run with flag
minizinc --all-solutions test.mzn - Parameters can be given a value later on using a file with extension
.dznlikeminizinc test.mzn values.dzn(The model MUST be provided with the values of the parameters from a single / multiple dzn files) - Array declarations for parameters:
array[range/enum] of int: arr1- 2D
array[enum1, enum2] of float: consumption - Generator operations on arrays:
constraint forall(i in enum)(arr1[i] >= 0)solve maximize sum(i in enum)(arr1[i]*2) < 10
- Array Comprehensions:
[expression | generator, generator2 where condition]- example:
[i+j | i,j in 1..4 where i < j]
- example:
- TLDR:
- enums to name objects
- arrays to capture information about objects
- comprehensions for building constraints
If elsecan be used inside forall blocks and outside the nested forall blocks.if condition then <blah> else <blah2> endif
March 7, 2019
- Use Pyglet for making graphics in Python.
- Use Q-Learning! It's great!
- This code-bullet video is great!
- Pythonic way to do it:
reversed(list(enumerate(lst)))
March 6, 2019
algorithm
- Transpose first -
- You transpose only on one side of the diagonal. (Inner loop should be
for j in range(i,n)- OR -for j in range(0,i))
- You transpose only on one side of the diagonal. (Inner loop should be
- Then reverse column order
- Easy Peasy!
- Pythonic array init
a = [0]*10 - Pythonic
for i in range(a,b)Remember that b in this is not inclusive! - Suppose, in an array, something(x) is added from range p to q for each test-row. Find maximum element in the final array:
- Store x in arr[p] and -x in arr[q], so while iterating from left to right, the items will be +x only in the range p to q. 😮
March 4, 2019
msc
- This paper for Visual Rhythm Prediction with Feature-Aligning Network seems useful.
- Various features could be used like:
- Original Frames
- Frame Residuals
- Optical Flow Detection
- Scene change detection
- Body Pose detection
- The features could be misaligned as some features just depend on one frame while others depend on multiple frames.
- Solution: Feature Alignment Layer
- Employs Attention mechanism which is a hit in NLP
- Solution: Feature Alignment Layer
- Finally sequence labelling with BiLSTM
- Also a [Conditional Random Field] layer to make prediction aware of consecutive predictions. (Instead of my existing Linear layer ?)
Feb 27, 2019
- Make a function in your server callable through the clients.
- Makes use of Google's protocol buffers instead of (JSON in REST etc.)
- Serve SDKs instead of APIs.
- Nice gRPC python example.
Feb 26, 2019
- Completed video capture and matrix profile generation. (NON REAL TIME)
- Next task is count-classes for sure.
- Batching windows into fixed size regions (100 frames).
- Thinking of using classes 0-10 in this region.
Feb 12, 2019
msc
- Should I keep a fixed window and have classes for respective counts ?
- Should I let the window size be variable and have a moving class count ?
algorithm
- Quicksort - remember
return quicksort(arr[:pivotPosition]) + [pivot] + quicksort(arr[pivotPosition+1:]) - Mergesort - remember
return arr- Calls
mergesort(left)andmergesort(right)internally.
- Calls
Feb 9, 2019
- Google Docs:
Tools > Voice Typing🐙 - Gonna start typing 😉 tonight!
msc
- Decided to use some numpy Gaussian Noise with a decided mean and std to generate noise.
- Applied noise on normalized waves (values between 0 - 1) so, if we decide on a mu/sigma (say 0, 0.1), we'll know that for 60% of the waves a maximum of 10% distortion will be added to the signal.
Feb 3, 2019
- New connections in Cloudera, Goldman.
- Gooogleeee
- GoLang Delve Debugging.
Jan 30, 2019
msc
- Submitted in 2019. Next task = Read this paper.
- "Wavelets in a wave are like words in a sentence" - Jan Van Gemert
- Try adding noise to my sine waves.
- Have counting classes at the end instead of peaks and valleys.
- Read papers Visual Rhythm Prediction and Video CNN
- Maybe also try:
- Training an LSTM from scratch
- Use a stacked LSTM with the first one being my peak detector.
Jan 29, 2019
- It can replace a
try-finallyblock - It is used as a context manager.
- Can be implemented by implementing
__enter__and__exit__methods in a class!
- LSTMs trained just on sine waves showed some good signs on the Matrix Profile ❤️
- Waiting for the meeting to decide how to make it and end to end model!
Jan 22, 2019
- Came across this nice short tutorial for creating my first tiny sublime text plugin.
- I have decided to call it
meow - 🐱
- Finished it. Find it here
msc
- I was expecting LSTMs to be better, (They were probably overfitting). TCNs show a better understanding of the curves (judging by the learned probabilities).
Jan 22, 2019
msc
- Nice blog post
- Given a sequence of occurences, what is the probability that the dice rolled was biassed or unbiassed ? (Could this be used for our scenario ?) Given a sequence of matrix profile inputs, what is the prob that there were 2 peaks, 4 peaks etc. ?
- A Conditional Random Field* (CRF) is a standard model for predicting the most likely sequence of labels that correspond to a sequence of inputs.
Jan 22, 2019
- Poisson ~ counting process.
- Probability of Number of occurences (k) in a small time interval (h).
$P[X(h + s) - X(s) = k]$ =$\frac{(\lambda h)^k e^{-\lambda.h}}{k !}$ - These interval probabilities are conditionally independent!
- Expected Number of occurences in interval (h) =
$\lambda. h$ - Sum of two poisson processes is also a poisson with
$\lambda s$ added. - Uniform distribution: If an event of a Poisson Process occurs during interval [0, t], the time of occurance of this event is uniformly distributed over [0, t].
-
PROBLEMS TAKEAWAY:- Don't forget the law of total probabilities (Summation) for calculating PDFs with a variable input etc. There can be questions with a mixture of Poisson (Probability that Count of something is k) and Bernoulli (Probability that number of successes is k) distributions.
- From a combination of poissons, Given an arrival: prob that arrival was from p1 =
$\frac{\lambda_1}{\lambda_1 + \lambda_2}$ - This will be just a product if not given an arrival. (Bayes! Duh!)
-
A joint flow can also be decomposed with rates
$\lambda.p$ and$\lambda.(1-p)$ (Instead of mixing it up with a binomial).
- Maximising winning probability = equate first derivative to 0 and solve!
- For calculating the prob from x to infinity, don't forget you can always compute it as [ 1 - P(0 to x)].
Jan 17, 2019
- Found an issue to work on in Spotify's Luigi. Working on creating a pull request for the same.
- Currently, a dictionary {bool, worker} is returned along with the worker details.
- an object of type
LuigiRunResultshould be returned
- Got responses from
BeatsandLuigion the PRs. 😍
Jan 15, 2019
msc
- Should I use the (n x n) distance profile for my training ?
- IDEA: Make use of the fact that a repetition means it has a peak and the part after the peak is a mirror of the part before the peak.
- Video by Siraj
- New neural networks for time series datasets. (Uses integral calculus)
- Remember residual nets
$x_{k+1} = x_{k} + F(x_k)$ can be written as$x_{k+1} = x_{k} + h.F(x_k)$ - Find original function by taking integral of the derivative.
- Frame your net as an ODE!
- Use ODE solvers after that like Euler's method or better (Adjoint Method)
- Tutorial
sudo apt-get install build-essential
target: dependency1 dependency2 ...
[TAB] action1
[TAB] action2
- Target can be all, clean etc.
- all/First target is executed if make is run without arguments. Otherwise
make target - Target can also be filenames. If targets and filenames clash, avoid these targets to be treated as files :
.PHONY: all clean - Dry run =
make -n @echo $(shell ls)to print output of ls command- Running make inside subdirectories:
subtargets:
cd subdirectory && $(MAKE)
include 2ndmakefileto halt current makefile execution and execute the other makefile.- Use prefix
-with actions/include to ignore errors.
Jan 13, 2019
- Created a pull request with my new beat 💃
- Following these MIT Lectures for Applied probability
- Poisson is just Bernoulli trials with n (number of trials) (Granularity) approaching infinity.
- Success = Arrival
- Memoryless
- Causal = Based on what has happened before.
Jan 10, 2019
msc
- Golang has tags which are just backticks. These add meta information to struct fields and can be accessed by using the reflect package
import "reflect"type Name struct { VariableName int mytag:"variableName" }obj = Name{12};r = reflect.TypeOf(obj);field, found := r.FieldByName(VariableName)field.Tag.Get("mytag")
- These tags make having a config like .yaml easier!
- Your beat implements ** Run, Stop and New ** methods.
- If you add new configs to .yaml, add them to
_meta/beat.yamland also to the code inconfig/config.go - If you add more fields in the published message, add them to Run method and also in
_meta/fields.yml- Use make update after any of the above changes!
Jan 9, 2019
- I have decided to contribute to Elastic Beats! Cz go go go!
- Following these setup instructions.
- Use EditorConfig file for your open-source projects fellas! Installed the sublime plugin.
magefile= Make like tool for converting go-functions to make-target like executables.- Installed govendor for dependency management.
- Beats contain
- Data collection logic aka The Beater!
- Publisher - (Implemented already by
libbeatwhich is a utility for creating custom beats)
- Bare minimum message requirements:
- Message should be of type
map[string]interface{}(like JSON) - should contain fields
@timestampandtype
- Message should be of type
- Virtual environment python2
go get github.com/magefile/mage- After breaking my head for hours!
- Update in Makefile in
$GOPATH/src/github.com/elastic/beats/libbeat/scripts/Makefile: change this key to:ES_BEATS?=./vendor/github.com/elastic/beats(It has a comment next to it, but this was not mentioned in the docs for some reason) - Install a fresh Python2.7 from conda (I used the bash setup for my Mac)
- Create a virtualenvironment in folder
yourbeat/build/with the namepython-env
- Update in Makefile in
- Run
make setupinside your beat folder - Need to play around with Make!
- Next episode = Writing the Beater!
- Just print the model to see what the architecture looks like.
model.state_dict()contains all the weights (layer-wise)- Use
torchvision.utils.make_gridto plot them all.
Jan 7, 2019
msc
Idea to make it end to end trainable. Can I use policy gradients to make it end to end trainable ? Reward the states which end up in the correct count ? Woah! Can I ?- Policy gradient on top of the matrix profile output ?
- Good Toy task - make the Net remember a sequence of numbers pattern!
- Peak counter presentation link
Jan 6, 2019
Following the Go Tour now!
- Workspace =
~/go/src/( Typically a single workspace is used for all go-programs) (All repositories inside this workspace ) (Usually create a folder structure like~/go/src/github.com/live-wire/project/to avoid clashes in the future)-
$ go env GOPATH(Set the environment variable GOPATH to change the workspace)
-
-
$ go filename.gogenerates an executable binary! -
$ go installin this folder adds that binary to~/go/bin/(Make sure it is added to PATH so you can run the installed packages right away) - Go discourages use of Symlinks in the workspace
- Workspace contains
srcandbin - Use
go buildto see if your program compiles - First line in a Go program must be
package blahwhere the files belonging to this package must all have this. This package name must not always be unique, just the path where it resides should be! Usepackage mainfor executables. - Importing packages
"fmt"
"github.com/live-wire/util" )
fmt.Println(util.something)
- Testing. A file blah_test.go will have the tests:
import "testing" - Looping over variableName which could be an array, slice, string, or map (use range):
for key,value := range variableName {}
- Capitalize the stuff in the file that you want to export to other packages!
- Naked return. Name the return values and assign them inside the function
ret1 = a + b
ret2 = a - b
return
}
var a,b = true, "lol"Usevarover:=everywhere!- If in go can have a small declaration before the condition (whose scope ends with if)
defercalls function after the surrounding function returns! (All defers are pushed to a stack)- Pointers var p *int
- i = 24; p = &i (*p = i)
- Structs = collections of fields
A int
B int
}
- Pointers to structs can access the fields without using the star!
p = *lol; p.A = 12instead of(*p).A = 12 - Slices are just references to the underlying arrays
cats = [3]string{"peppy", "potat", "blackie"}; potat := cats[0:2]Anything can be appended to these slices but not to the arrays.potat = append(potat, "tom") - Maps:
map[keytype]valuetypemake sure to surround it all withmake(..)when initializing - Function pointers:
func (v *Vertex) fun(arg int) {}can be called asv.fun(10)(The star makes it in-place)- define a
String()function for a struct like python's__str__and__repr__functions.
- define a
- Interfaces:
type I interface { M()}Now all variables of type I will have to implement this function. Likefunc (t *T) M() {}now all variables of type T will have a function available called M and can be casted to type I.- Each variable is of type
interface{}
- Each variable is of type
- Errors: cast the erroneous variable with the error class.
- define
type ErrType float64 func (e ErrType) Error()string { return fmt.Sprintf("%f",e) }- Use it as
ErrType(12.23) - It will also be of type error!
- define
- Go Routines:
- Usage
go functionName()
- Usage
- Channels (For communication among go-routines): (Like maps and slices, channels must be created before use)
ch := make(chan int)- Channels need to close themselves by calling when
close(c)when reading in a loop (to exit a range)for i := range c {}
- To select a channel to run:
case res := <-resc:
fmt.Println(res)
case err := <-errc:
fmt.Println(err)
}
}
- This is important as `select` makes the current routine wait for communication on the respective channels! Can be used to make the main thread wait!
- Mutex (Mutual exclusion): Thread safety, sharing resources by locking/unclocking them (Counters)
import "sync"- Create a struct with a field say
muxof typesync.Mutex - This field has functions Lock() and Unlock() attached to it.
- Example:
st.mux.Lock() // Your object Locked
defer st.mux.Unlock() // called after this function ends
st.counter ++
// NEAT!
}
Jan 2, 2019
- [Blog post] by Karpathy on Reinforcement Learning!
- Good video by Xander.
- Deep Q Learning with function approximation (which can be a CNN etc.)
- "Whenever there is a disconnect between how magical something seems and how simple it is under the hood I get all antsy and really want to write a blog post" - Karpathy You Go Boy!
- Policy Gradients are end to end trainable and favourites for attacking Reinforcement Learning problems.
- Needs billions of samples for training as the rewarding set of moves will occur not-so-frequently. And it needs a lot of them to be able to make a policy that leads to rewards.
- Nice take-away = Policy gradients help incorporate stochastic, non-differentiable flows which can be backpropagated through. Stochastic computation paths. These work best if there are a few discrete choices.
- Trust Region Policy is generally used in practice. (Monotonically improves)
- Keyboard/mouse input programatically = Pyautogui
- Applying for AI jobs! In amazing teams? Be useful to them! Read what they must be reading right now!
Jan 1, 2019
msc
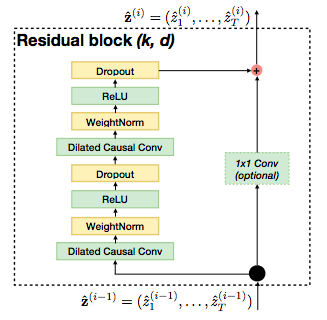
- Could TCNs replace LSTMs for Sequence Tasks ?
- TCNs have a longer memory and have Convolutions (faster to train, fewer parameters)
- TCNs employs residual modules instead of simple conv layers with dilations.
- It employs
Weight Normalization- For each layer, before applying the activations, normalize! ((x - mean) / std)
- Recap:
Batch Normalizationnormalizes values out of the activation function.
- It employs
- I could also try to implement a bi-directional TCN as I did with CNN 😏
- Looking at Copy Memory task from the TCN implementation.
Applying TCN was not learning that well. I used ELU instead of RELU in the TemporalBlock of the TCN implementationIt significantly improved the learning results.- Also implemented the bidirectional variant of TCN and as expected, it does better than the unidirectional one!
- Pretty happy with these TCN results and planning to use this as the peak detection model if not LSTM/GRU!
Align the existing labels of repetitions by dragging them along the time axis such that it minimizes the loss- Think of ways to auto-label the dataset.
Dec 31, 2018
- Need to play around with the deepdream notebook of google and generate some art!
- Implemented the loss-plotter for plotting the moving average of my bidirectional CNN experiment. My implementation of the bidirectional CNN has more learnable parameters, so not a fair competition!
- See you next year. 🍻
Dec 29, 2018
msc
- Convolutions Visualizer
- Output size after convolutions: discuss.pytorch post
o = [i + 2*p - k - (k-1)*(d-1)]/s + 1(o = output, p = padding, k = kernel_size, s = stride, d = dilation)
- A dilated kernel is a a huge sparse kernel!
- Got a simple CNN with dilations to learn like an LSTM learns a sequence. It is okay but not great! But look at the number of parameters it needs 😮 only 18 compared to over 1000 in LSTMs.
- Reading this paper now and planning to implement TCNs for my sequence modelling task. It should give me a better feel about how to use convolutions with dilations instead of LSTMs. (Bi-directional LSTMs already look promising for the task)
How about a new Convolutional architecture that mimics the bi-directional nature of LSTMs ?- Use
torch.flipto reverse a tensor. link
- Use
- Finished first draft of my own Bidirectional CNN with dilations! It clearly works better than a (conventional) unidirectional CNN without dilations!
- Next experiment = trying TCN
Dec 28, 2018
- Serialization and Deserialization wrapper for several languages!
- Tutorial
- Ideology:
- Low level features are local! (Kernels and Convolutions)
- What's useful in one place will also be useful in another place in the image. (Weight sharing in kernels)
- Smaller kernel = more information = more confusion
- Larger kernel = More information = Less attention to detail
- Output of a convolution layer:
- Depth = Number of filters applied
- Width, Height =
$W=\frac{W−F+2P}{S} + 1$ (where W is current width, F is filter width (receptive field, P = padding, S = Stride)) - Recommended settings for keeping same dimensions = (S = 1) and (P = (F-1)/2)
Dec 23, 2018
- Chat with Juergen Schmidhuber
- Self-Improving computer program that solves problems in an optimal way. Adds a constant overhead (which seems huge/infeasible to us right now for the problems at hand but it is constant.) But if you think of all-problems (Googol problems), this is a big-big thing. Right ?
- LSTMs and RNNs are just looking for local minimums by descending down them gradients. Imbecile! lol!
- Look for a shortest program that can create a universe! Only the random points create problems and big lines of code (not compressible - more bits to be described). The most fundamental things of nature can be described in a few lines of code.
- Seemingly random = Not understood as of now! = UGLY!
msc
- There are other activations like ELU, SELU etc.
- They make RELU differentiable at x=0! (RELU =
$max(0,x)$ , ELU = $max(0,x) + min(0, \alpha*(exp(x)-1))$)
- They make RELU differentiable at x=0! (RELU =
- Learnable parameters in 1D-CNNs = For each kernel: kernel_params + 1 (bias)
- 1D CNN Pytorch:
- Input/Output = (N (Batch size), C(input/output channels), L(length of sequence))
- 1D CNN Pytorch:
Try to make a bidirectional CNN with dilations model!- Looks like I wasn't employing the dilations before. Was just using the FCN. 🙈
Dec 22, 2018
msc
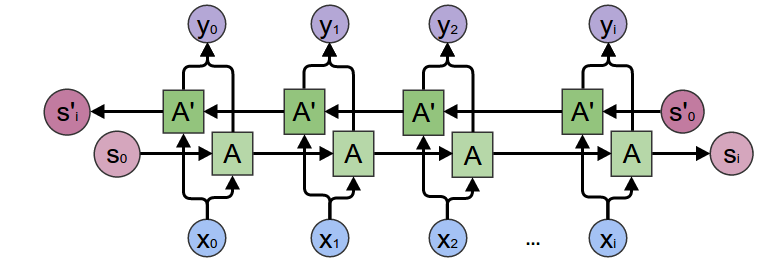
Bidirectional=Truewith same number of hidden parameters (actually multiplied by 2 for both directions), performs much better for peak detection.- Make sure to double the input params of the linear layer that follows it when you make it bidirectional.
- A fair competition would be competing against a regular(unidirectional) LSTM with double the hidden units.
- Calculating parameters in a bidirectional LSTM/GRU/RNN:
- First Layer: 2 * (inp * hidden + hidden) (Multiplied by 2 as bidirectional)
- Output of first/upcoming hidden layers: 2 * (hidden*hidden + hidden)
- Input of second/upcoming hidden layers: 2 * ((hidden+hidden)*hidden + hidden)
- Output same as before.
- 💣
- Model trained on sequence length 50 does alright on sequences of length 100 as well.
- Need to try Convolutions with dilations now.
Dec 17, 2018
- Set up docker for my project community
- Docker networking
ports: [host:container](Compose creates a network in which all the containers reside) docker psshows all containersdocker exec -it <containerid> /bin/bashto open a containerdocker system pruneremove dangling images- Docker volumes = shared storage for containers on the host!
- Docker networking
- TODO: Play around with container networking! (Crucial before setting up some Nginxes)
msc
- Number of parameters in an RNN (LSTM)
torch.nn.Modulemodel is NOT DEPENDENT on the sequence length- Longer the sequence, the harder it will be to understand for a simple model.
- Number of parameters explained:
- Weights multiplied by 4 for all the 4 sets of Weights and Biases
Wlink. Number of weights and biases is multiplied by 3 for GRUs and 1 for regular RNNs. - Into an LSTM layer:
- input --> hidden_dim (input*hidden_dim + hidden_dim) * 4
- Coming out from an LSTM layer:
- It should output something with dimensions = hidden_dim because it also needs to be fed back to possibly more layers!
- hidden_dim --> hidden_dim (hidden_dim*hidden_dim + hidden_dim) * 4
- ⚡
- Weights multiplied by 4 for all the 4 sets of Weights and Biases
- Since the sequence length doesn't account for a change in parameters, the same model can be trained over several sequence lengths to make it more robust!
How to make the final model end to end trainable?
Dec 14, 2018
msc
Idea: Should I one hot encode X values(by categorizing them into range categories) as well ?- ^ ^ Not required I guess! LSTM does well (for small sequences of length 20 or so) using Cross-Entropy-Loss. (Negative log of Softmax! as the loss).
- Followed the following steps:
- Generate class-wise scores using the output of a NN (RNN-LSTM-2 Layers and 10 hidden units for today's experiments)
- Use
torch.nn.CrossEntropyLoss()as thecriterionto get the loss by comparing output and target! - Call
loss.backward()to backpropagate the loss andoptimizer.step()to actually update the weights. - Now your model will output the class scores!
- Use
torch.nn.functional.softmax(torch.squeeze(output), 1)to get an interpretable probabilistic output per class. ❤️
- Rock on 🤘
Dec 11, 2018
algorithm
- Create functions like
__eq__(self, other),__le__(self, other)inside the class to overload the corresponding operators. Compare the objects of your classes like a boss! - Use the decorator
@staticmethodwith a function in a class to mark it as a static method. This will be callable by ClassName.method or classObject.method! - Override methods
__str__to make the object printable when printed directly and__repr__to make the object printable even when a part of an array etc.
Heapify RECAP
- Heapify! = log(n) = (Trickle down! ALWAYS TRICKLE DOWN)
- Insert element at the top and call heapify once.
- Pop element by first swapping the first with the last and removing the last! Then call heapify once.
- BuildHeap = n/2 * log(n) = (Start from bottom) check children for heap property (trickle up)
- loop from items n/2 to 1 and call heapify on all of them! (Called once initially!)
Dec 6, 2018
msc
- combining multiple generators -
from itertools import chaingenerator3 = chain(generator1(), generator2())
- Sine waves - Manual Peak detection can look at the local minimas and maximas! What about the global characteristics ? How to tackle them ? :sad:
- Wrote
sine_generator.pyto generate X, Y from the sine waves generated. -
IDEA: Maybe merge the wavelet peaks that are too close to each other based on a threshold- Or prune based on amplitude/stretch_factor on both sides of the peak.
-
Fourier transform: Get the original bunch of waves from the combination wave
- It will show spikes where the actual components occur.
- Wind the wave into a circle, the center of mass shifts(on changing the wind frequency) only when it finds a component frequency.
- How ?
Integral of -$g(t)e^{2\pi i f t}$ (Depicts the center of mass (scaled)).
Dec 4, 2018
- Amazing project by NVIDIA. It renders the world after training on real videos.
- Want a setup whenever you open python console ?
- Set an environment variable
PYTHONSTARTUPwith the path to a python file that imports stuff! 💣
- Set an environment variable
msc
- Generating sine-wavelets is taking some shape. The variables when generating a combination of sine-wavelets are:
- begin = 0 # Can have values 0 or pi/2 (growing or decreasing function)
- wavelength_factor = 0.5 # chop the wave (values between 0 and 1)
- stretch_factor = 3 # Stretch the wave to span more/less than 2pi
- amplitude_factor = 0.5 # Increase/decrease the height of each curve
- ground = 2 # base line for the wave
Dec 3, 2018
msc
-Yield in Python If a function yields something instead of return, it is a generator function which can be iterated upon. try calling next(f) on f where f = gen_function(). It will return the next value from the generator. - It reduces the memory footprint! and is coool!
- Generating a bunch of sine-waves today.
np.linspace(start, end, num)gives num values between start and end.tensor.view()is like reshape of numpy (-1 means calculate its value based on the other parameters specified)Prophet: Forecasting procedure implemented by Facebook. link. It's nice for periodic data with a trend. (It assumes there is yearly, monthly, weekly data available). post- Experimenting with sine-wavelets! Trying to create complex randomized sine-waves with varying [amplitude, wavelength (cropping the wave), stretch factor (making the wave span less or more than 2pi) and ground (the base of the wave which is 0 by default)].
Idea: Will it be possible to model the matrix-profile as sine-wavelets using regression ?Idea for RealTime: Learn a wavelet-like-sequence-of-frames from the given video that represents a repetitionIdea: more than one frame at a time to the matrix profile
Dec 2, 2018
msc
- Link to my summary of the paper
- Use softmax to discretize the output and model conditional distributions. If there are way too many output values, use the
$\mu$ -law. (Try Mu-law or some alternative) - Look at LS-SVR Lest square support vector regression.
- Also try the Gated-activation-units (tanh, sigmoid approach like pixelCNN, Wavenet) instead of regular RELUs.
- Seems like WaveNets are cheaper than LSTMs. So my experiments shoule be in this order.
- Skip-Connections: If some future layers(like the fully connected ones) need some information from the initial layers (like edges etc.) that might be otherwise lost/made too abstract.
- Residual Learning: Like skip connections, allow the gradients to flow back freely. Force the networks to learn something new with every new layer added. (Also handle the vanishing gradient problem)
-
Cool Convolutions:
- Kernel for box-blur = np.ones((3,3)) / 9 (Note that sum of all values in the kernel = 1)
- Edge detection: all -1s, center = 8
- Sobel Edge (less affected by noise)= [[-1, -2, -1],[0,0,0],[1, 2, 1]]
Nov 28, 2018
msc
- Link to my summary of the paper
- Reading the paper Conditional Image generation using PixelCNN Decoders. Link
- PixelCNN employs the Conditional Gated PixelCNN on portraits. It uses Flicker Images and crops them using a face detector!
- Face Embeddings are generated using a triplet loss function which ensures that embeddings for one person are further away from embeddings for other people. (FaceNet link)
- Use Linear Interpolation (between a pair of embeddings) to generate a smooth output from one to the next generation. Looks beautiful! DeepMind's generations.
Nov 28, 2018
msc
- Idea - find the sequence of images in the video that show the maximum similarity when super-imposed on the upcoming frames.
- Activation functions and derivatives:
-
Sigmoid(0 to 1):$f(x) = \frac {1}{1+e^{-x}}$ and$f'(x)=\frac{f(x)}{1-f(x)}$ (Useful for probabilities, though softmax is a better choice) -
TanH(-1 to 1):$f(x)=\frac{e^x - e^{-x}}{e^x + e^{-x}}$ and$f'(x)=1 - f(x)^2$ -
RELU(0 to x):$f(x) = max(0, x)$ and$f'(x) = 1 if x>0 else 0$
-
-
LSTM: link
Notations:$h_t$ = output at each time step,$C_t$ = Cell State,$x_t$ = Input at a time step.- Forget Gate: I consumes the previous time step, merges it with current input, passes it through a sigmoid gate output(0 to 1) and pointwise multiplies the result with the cell state. (It specifies how much needs to be passed to the next state).
$f_t = \sigma (W_f[h_{t-1}, x_t] + b_f)$ (This square brackets means the h and x are concatenated and more weights for W_f to learn) - Cell state: It decides what needs to be saved in the current state. It takes the output from pointwise multiplication of forget gate and old cell-state and then adds (the tanh of current input and sigmoid of current input(for making it range from 0 to 1))
$i_t = \sigma (W_i[h_{t-1}, x_t] + b_i)$
$C_t^{-} =tanh(W_c[h_{t-1}, x_t] + b_c)$
$C_t = C_t^{-} * i_t + f_t * C_{t-1}$ (Here * is pointwise multiplication) (This is the state stored for this cell that is forwarded to the next time-step) - Output: We still haven't figured out what to output (
$h_t$ ). Now take this computed cell state, tanh it to make it span from -1 to 1 and pointwise multiply it with the sigmoid of current input.
$h_t = tanh(C_t) * \sigma (W_o[h_{t-1}, x_t] + b_o)$ This output is then sent upward (out) and also to the next time step. - Easy peasy 🍋 squeezy!
- Forget Gate: I consumes the previous time step, merges it with current input, passes it through a sigmoid gate output(0 to 1) and pointwise multiplies the result with the cell state. (It specifies how much needs to be passed to the next state).
-
LSTM Variants:
- There is a variant which uses coupled forget and input gates: merges sigmoids for
$f_t$ and$i_t$ and uses$1 - f_t$ instead of$i_t$ . - There is a variant which uses peep-hole connections everywhere (Adds State value C_t everywhere in all W[]s)
-
GRU:
- No Cell state variable to be forwarded through timesteps.
- Only output is generated which is propagated up and to the next timestep.
- Lesser parameters to train.
- Uses the coupled forget and input gates idea.
-
$f_t = \sigma (W_f[h_{t-1}, x_t] + b_f)$
$c_t = \sigma (W_c[h_{t-1}, x_t] + b_c)$
$h_t^{-} = tanh (W_o[c_t * h_{t-1}, x_t] + b_o)$
$h_t = (1 - f_t)*h_{t-1} + f_t * h_t^{-}$ -> This is the output that is forwarded upwards and into the next time step.
- Probably experiment with this as well, as it has lesser parameters to train for the small dataset we have.
- There is a variant which uses coupled forget and input gates: merges sigmoids for

Nov 27, 2018
algorithm
- Making your implementation of (say a LinkedList) iterable in Python:
- Declare a member variable which contains the current (
__current) element (for iterations) - Declare function
__iter__which inits the first element in__currentand returns self! - Declare function
__next__which callsStopIteration()or updates the__currentand returns the actual item(node)! - 💣 You can now do a
for node in LinkedList:(elegant af)
- Declare a member variable which contains the current (
-
Self-balancing trees : (AVL Trees, Red-Black Trees, B-trees)
-
B-Trees link: Generalization of a 2-3 tree (Inorder traversal = sorted list. Node can have 1 (and 2 children) or 2 keys (and 3 children))
- All leaves must be at the same level
- Number of children = x is
$B<= x < 2B$ (Note the < sign in upper bound) - If B = 2, It is a 2-3 tree (2 Keys, 3 children)
- Insertion is okay, when overflows (more elements in a node than the allowed number of keys), move the middle element up. If keeps overflowing, keep going up till you reach the root.
- Deletion - Trickier! Delete the node, Rotation!
- Why? - Large datasets - On-disk data structure (not in-memory). It makes fewer larger accesses to the disk! - they are basically like maps with sorted keys (that can enable range operations)!
- Databases nowadays usually implement B+ trees (store data in leaves and don't waste space) and not B-trees.
-
B-Trees link: Generalization of a 2-3 tree (Inorder traversal = sorted list. Node can have 1 (and 2 children) or 2 keys (and 3 children))
Nov 26, 2018
- Autoencoders: Lower dimensional latent space link
- Variational Autoencoders: Instead of bottleneck neurons, a distribution is learned (mean and variance) (Backpropagation Reparamatrized trick is used where the stochastic part is kept separate from mean and std. so gradients can flow back)
- New Type: Disentangled Variational Autoencoder - Changing the latent variables leads to interpretable things in the input space (few causal features from a high dimensional space - latent variables (and understandable)).
Nov 25, 2018
msc
- Link to my summary of the paper
- Going through the PixelRNN paper as it is kind of a prerequisite for WaveNet.
- Latent Variables: link
- Latent variable is not directly observable by the machine (potentially observable - hypothesis - using features and examples)
- In most interesting datasets, there are no/missing labels!
- Principal Component Analysis / Maximum Likelihood estimation / Variational AutoEncoders. We use it when some data is missing! Who else uses this ? - Auto Encoders.
- Latent variables capture, in some way, an underlying phenomenon in the system being investigated
- After calculating the latent variables in a system, we can use these fewer number of variables, instead of the K columns of raw data. This is because the actual measurements are correlated with the latent variable
- Two Dimensional RNNs link used for generating patterns in images.
- Autoregressive - A value is a function of itself (in a previous timestep). AR(1) means the process includes instance of t-1.
- Uber's pyro - Probabilistic programming (Bayesian statistics) with PyTorch. Build Bayessian Deep learning models.
- Traditional ML models like XGBoost and RandomForests don't work well with small data. source
- Used for Semi-supervised learning.
- Variational inference models for time-series forecasting ? SVI ? (IDEA ?
msc?)
Nov 14, 2018
algorithm
- Decision Trees:
Baggingmight not necessarily give better results but the results will have lower variance and will be more reliable / reproducible. - Checking if a tree is a BST: Keep track of the min and max value in the subtree! That's all!
Nov 12, 2018
msc
- Crazy reddit post
- Papers to read series: PixelRNN/PixelCNN/WaveNet/ByteNet
- ConvNets haven't been able to beat RNNs in question answering (Can't keep running hidden state of the past like RNNs)
IDEA: Try to generate a sine wave based on the number of repetitions in the duration specified! Minimize Loss somehow! How to deal with repetitions of varying lengths though ?IDEA: Think of a minimum repetition wave, try to minimize loss by varying the wavelength. The entire signal could be a combination of such wave-lets(scaled)
Nov 9, 2018
Maths Numbers Primes
- The
$\zeta(s) = \frac{1}{1^s} + \frac{1}{2^s} + \frac{1}{3^s} + \frac{1}{4^s} ...$ - This is undefined for real numbers <=1 and is convergent for any values greater.
- Great video.
- Where is this function zero apart from the trivial(-2, -4, -6 etc.) ones. (On the strip between zero and 1 somewhere)
- Rieman's hypothesis = they lie on the line where the real-component = 1/2. This tells us something about the distribution of primes.
- Take away: How many primes are less than x ?
$\frac{x}{ln(x)}$ 💣 and the prime density is$\frac{1}{ln(x)}$
msc
- How can I use the repeating properties of a sine wave for repetition counting ? Generate some features ?
October 26, 2018
Algorithm Puzzle
- The Graph needs to have all nodes with even degree and only zero or 2 nodes with odd degree for the Eulerian Walk to be possible. (Same as being able to draw a figure without lifting the pencil or drawing on the same line again)
October 25, 2018
- Tinkercad by Autodesk - Awesome for prototyping 3D models for 3Dprinting
- Ostagram Style transfer on images.
- Distances (Minimize both of these during optimization):
-
$D_s$ - Style Distance -
$D_c$ - Content Distance
-
- It is amazing how easy it was to run this :O (Loving PyTorch 🔥)
msc
torchvision.transformscontains a bunch of image transformation options- Chain them up using
transforms.Composelike this:
loader = transforms.Compose([
transforms.Resize(imsize), # scale imported image
transforms.CenterCrop(imsize), # Center crop the image
transforms.ToTensor()]) # transform it into a torch tensor
unloader = transforms.ToPILImage()
and use it like:
def image_loader(image_name):
image = Image.open(image_name)
# fake batch dimension required to fit network's input dimensions
image = loader(image).unsqueeze(0)
return image.to(device, torch.float)
- Import a pre-trained model like: (link)
cnn = torchvision.models.vgg19(pretrained=True).features.to(device).eval()
# In Pytorch, vgg is implemented with sequential modules containing _features_ and _classifier_(fully connected layers) hence the use of ".features"
These models expect some normalizations in the input
- Finished a wrapper around the neural style transfer tutorial code. ❤️
October 24, 2018
msc
- Preprocessing:
- Using Bresenhem's Line algorithm to sample representative elements from a list.
- Sample m items from n:
lambda m,n: [i*n//m + n//(2*m) for i in range(m)] - Finally sampling 10fps for all videos using this technique
- Sample m items from n:
- Making images Black&White
- Resizing images to 64x64 for now (Toy Dataset)
- Using Bresenhem's Line algorithm to sample representative elements from a list.
October 23, 2018
- DCM files(from both MRI and CT scans) contain pixel_array for each slice.
- A different file contains information about the contours of tumour - corresponding to the slices.
- Learnings:
- Fail Fast, Move on, Don't try to protect your code
- Spend time on MLH challenges, win cool stuff like the Google home mini 😉
- Check out Algolia (Hosted search API) for quick prototyping
Link to the problem.
- Solution:
- No one can move more than two positions backwards (2 bribes each) (Break if someone does)
- Start from the back: See how many bribes the small number took to reach there. If the number at the end is 4, see from 4-2= 2 to end-1 if there are numbers bigger than 4 and keep a count :happy:
October 14, 2018
- Two types of TTS(text to speech):
- Concatenative TTS: Basically needs a human sound database (from a single human) (Ewww)
- Parametric TTS: Model stores the parameters
- PixelRNN, PixelCNN - Show that it is possible to generate synthetic images one pixel at a time or one color channel at a time. (Involving thousands of predictions per image)
- Dilated convolutions support exponential expansion of the receptive field instead of linear
- Saves memory, but also preserves resolution.
- Parametrising convolution kernels as Kronecker-products is a cool idea. (It is a nice approximation technique - very natural)
- Reduces number of parameters by over 3x with accuracy loss of not over 1%.
- Convolutions arithmetic. Link

October 12, 2018
msc
- Things to try:
October 11, 2018
msc
- When you have bias in the number of classes in your training data:
- Oversample smaller classes
- Use
WeightedRandomSampler
- Transfer Learning is the way to go most of the times. Don't always freeze the pretrained convnet when you have a lot of training data
- Always try to overfit a small dataset before scaling up. 💥
October 10, 2018
msc
- Discuss about IndRNN (Long sequence problems for Recurrent neural network)
- Plot activations in layers(one by one) over timesteps. Activation vs Timestep.
- NEWMA - online change point detection
- Logistic classifier vs LDA: LDA assumes
$p(x/w)$ (class densities) is assumed to be Gaussian. It involves the use of marginal density$p(x)$ for the calculation of unknown parameters but for Logistic,$p(x)$ is a part of the Constant term. LDA is the better approach if Gaussian Assumption is valid. - L1-distance =
$\sum_p (V_1^p - V_2^p)$ , L2-distance =$\sqrt{(\sum_p (V_1^p - V_2^p)^2)}$ - Square-root is a monotonic function (Can be avoided when using L2)
- KNN is okay in low dimensional datasets. Usually not okay with images.
- Linear Classifier:
- Better than KNN because
- parameters need to be checked instead of all existing images.
- Template is learned and negative-dot-product is used as distance with the template instead of L1, L2 distances like in KNN
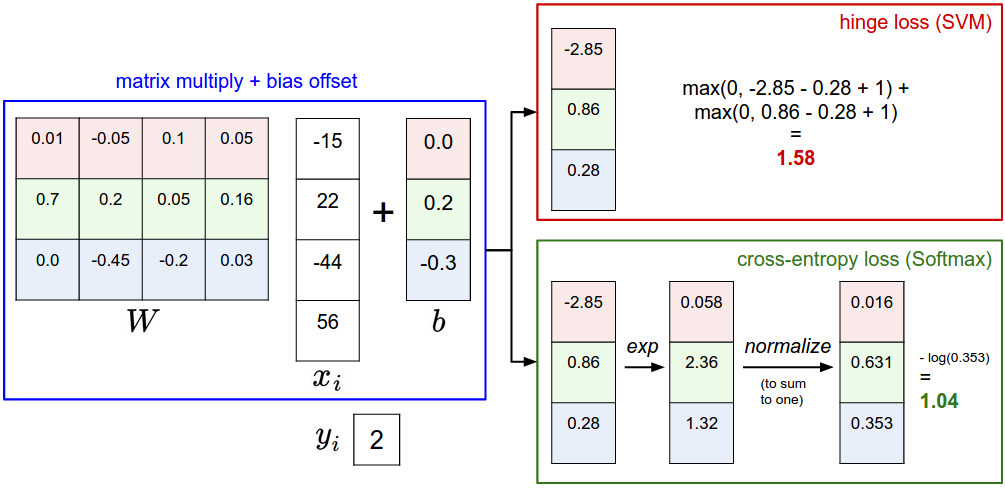
- The class score function has the form
$Wx_i + b$ . You get scores for each class. - If you plot a row of W, it will be a template vector for a class. Loss is a different thing be it SVM(hinge loss) or softmax (cross-entropy).
- And once you have the loss, you can perform optimization over the loss.
- Better than KNN because
- Lagrange Multipliers - awesome MIT video.
- BOTTOM LINE - Helps find points where Gradient(first partial derivatives) of a function are parallel to the gradients of the constraints and also the constraints are satisfied. post
October 5, 2018
- Brute-Force -
$2^n$ (For each item, decide take/no-take) - Greedy approach - Sort based on a criteria (weight, value or value/weight) - complexity = nlogn for sorting
- You could get stuck @ a local optimum
- these approaches often provide adequate/often not optimal solutions.
- Build a tree - Dynamic Programming - (Finds the optimal solution)
- Left means take element and right means no-take
-
Dynamic programming:
- Optimal Substructure
- Overlapping subproblems
- At each node, given the remaining weight, just maximize the value by chosing among the remaining items.
- Variants:
subset sum,scuba divlink etc.
October 3, 2018
msc
-
Even the
nn.LSTMimplementation gives bad results. I suspect this could be because the sequence length is too huge? Trying to generate a sequence with a smaller length. -
Maybe look at some other representation of the 1D signal ? (Like HOG ?)
-
PvsNP - What can be computed in a given amount of space and time ? (Polynomial vs Non Deterministic Polynomial)
- P = Polynomial, NP = Non Polynomial but the answer can be checked in polynomial time.
- NP-complete = Hardest problem in NP
- Can prove a problem is np-complete if it is in NP and is NP-hard
- NP complete problems can be used to solve any problems in NP 👑
- If A can be converted to B in Poly, A >= B
"If P = NP, then there would be no special value in creative leaps, no fundamental gap between solving a problem and recognising a solution once its found. Everyone who could appreciate a symphony would be Mozart and everyone who could follow a step by step argument would be Gauss!" - Scott Aronson
October 2, 2018
- Python style guide
- MIT Algorithm assignments page.
- Example coding interview
- Interview prep blog post
- Topics importante:
- Complexity
- Sorting (nlogn)
- Hashtables, Hashsets
- Trees - binary trees, n-ary trees, and trie-trees
- Red/black tree
- Splay tree
- AVL tree
- Graphs - objects and pointers, matrix, and adjacency list
- breadth-first search
- depth-first search.
- computational complexity
- tradeoffs
- implement them in real code.
- Dijkstras
- A*
- Make absolutely sure you can't think of a way to solve it using graphs before moving on to other solution types.
- NP-completeness
- traveling salesman
- knapsack problem
- Greedy approaches
- Math
- Combinatorics
- Probability link
- Operating System
- Threads, Processes
- Locks, mutexes, semaphores and monitors
- deadlock, livelock
- context-switching
- Scheduling
- Algo books
September 26, 2018
msc
- If you share the weights across time, then your input time sequences can be a variable length. Because each time before backpropagating loss, you go over atleast a sequence.
- Shared weights means fewer parameters to train.
- IDEA! - For longer sequences, maybe share less weights across time.
- nn.LSTM: Suppose we have 2 layers.
- Input to L1 = input, (h1, c1)
- Output from L1 = (h1_, c1_)
- Input to L2 = h1_, (h2, c2)
- Output from L2 = (h2_, c2_) ==> final output = h2_
tensor.size()=np.shape||tensor.view(_)=np.reshape- From what I've found out, batching in pytorch gives a speedup when running on GPU. Not very critical while prototyping on toy-datasets.
September 25, 2018
msc
- Recursive network that is going to be trained with very long sequences, you could run into memory problems when training because of that excessive length. Look at truncated-BPTT. Pytorch discussion link.
- Ways of dealing with looooong sequences in LSTM: link
- TBPTT (in the point above)
- Truncate sequence
- Summarize sequence
- Random sampling
- Use encoder decoder architecture
September 24, 2018
- Tried to generate a sine wave and make a Neural Net predict the number of valleys in the wave (Could be a useful step while calculating the final count from the 1D signal in the matrix profile)
- I assumed a signal of a fixed length (100). I trained a simple MLP on it assuming 100 features in the input. (Overfits and fails to generalize -- as expected)
- I want to train an LSTM/GRU on it now. Since it learns to generate a sine wave (as some of the online examples show). I am hoping it will be able to learn counting.
os.cpu_count()gives the number of cores.- threading.Thread vs multiprocessing.Process nice video
- Use Threading for IO tasks and Process for CPU intensive tasks.
- Threading makes use of one core and switches context between the threads on the same core.
- Processing makes use of all the cores (Like a badass)
September 23, 2018
msc
- This video by Andrej Karpathy.
- Idea about the thesis project:
- Karpathy uses a feature vector (one-hot vecotor for all characters possible)-->(feature vector from a CNN) for each timestep.
- In the output layer, would it be better to have a one-hot vector representing the count instead of a single cell which will calculate the count ?
- Should I pad the input sequence with 0s based on the video with the maximum number of points in the matrix profile ? (For a fixed
seq_length) ? - To make the learning process for blade-counting online, need an RNN with 3 outputs, clockwise-anticlockwise-repetition
-
seq_lengthin the RNN is the region where it can memorize.(size of input sequence (batch size of broken input)) - Gradient clipping for exploding gradients (because while backpropagating, same matrix(
$W_h$ ) is multiplied to the gradient several times ((largest eigenvalue is > 1))) - LSTM for vanishing gradients (same reason as above (largest eigenvalue is < 1))
- LSTMs are super highways for gradient flow
- GRU has similar performance as LSTM but has a single hidden state vector to remember instead of LSTM's (hidden-state-vector and c vector)
- During training, feed it not the true input but its generated output with a certain probability p. Start out training with p=0 and gradually increase it so that it learns to general longer and longer sequences, independently. This is called schedualed sampling. paper
September 19, 2018
- When someone says random variable, it is a single dimension!
- Central limit theorem: If any random variable is sampled infinitely, it ends up being normally distributed
- Expectation values:
-
Discrete
$E[x] = \mu = \frac {1}{n}\sum_{i=0}^n x_i$ $E[(x-\mu)^2] = \sigma^2 = \frac{1}{n}\sum_{i=0}^{n}(x-\mu)^2$
-
Continuous:
$E[x] = \mu = \int_{-\infty}^{+\infty} x.p(x)dx$ $E[(x-\mu)^2] = \sigma^2 = \int_{-\infty}^{+\infty} (x-\mu)^2.p(x)dx$
-
Discrete
- Multivariate Gaussian:
$p(x) = \frac{1}{\sqrt{2\pi\Sigma}}\exp\big{(}-\frac{1}{2}(x-\mu)^T\Sigma(x-\mu))\big{)}$ - Covariance Matrix:
$\Sigma$ - $\Sigma = E[(x-\mu)(x-\mu)^T] = E\big{[}\begin{bmatrix} x_1 -\mu_1\ x_2 - \mu_2 \end{bmatrix}\begin{bmatrix} x_1 - \mu_1 & x_2 - \mu_2 \end{bmatrix}^T\big{]} = \begin{bmatrix}\sigma_1^2 & \sigma_{12}\ \sigma_{21} & \sigma_2^2 \end{bmatrix}$
- Always symetric and positive-semidefinite (Hermitian) (All the eigen values are non-negative).
- For a diagonal matrix, the elements on the diagonal are the eigen values.
- You can imagine the distribution (for 2D features) as a hill by looking at the covariance matrix.
- Normally distributed classes:
- Use formula
$(x-\mu)^T\Sigma^{-1}(x-\mu) = C$ to get the equation of an ellipse(the iso curve thatseaborn.jointplotplots). - The orientation and axes of this ellipse depend on the eigen vectors and eigen values respectively of the covariance matrix.
- Use formula
September 17, 2018
- Different parts of the image are masked separately
- Image segmentation
- Multi class classification inside a single image
- Data is value - Andrew Trask (OpenMind) video
This Recurrent net is a classifier and classifies names of people to its origins
- First pytorch RNN implementation using this tutorial
- Only used linear (fully connected layers in this)
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
- The hidden component obtained after each output-calculation is fed back to the next input
- For this sequence of words, at each epoch, hidden layer is re-initialized to zeros (
hidden = model.initHidden()) and model's gradients are reset (model.zero_grad()) - Training examples are also randomly fed to it
- Negative Log Likelihood loss (
nn.NLLLoss) is employed as it goes nicely with a LogSoftmax output (last layer). - Torch
.unsqueeze(0)adds a dimension with 1 in 0th location. (tensor(a,b) -> tensor(1,a,b))
- Use
read_only_fieldsin theMetaclass inside a serializer to make it non-updatable - Views should contain all access-control logic
September 12, 2018
- Link to MathJax's landing page.
- Download the chrome extension from here.
- Bayes
$P(w/x) = \frac{P(x/w). P(w)}{P(x)}$ - Normal (Univariate)
$N(\mu, \sigma) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp{-\frac{(x - \mu)^2}{2\sigma^2}}$ -
Decision theory:
- An element(x) belongs to class1 if
$P(w_1 | x) > P(w_2 | x)$ (posterior probability comparison) - i.e.
$P( x | w_1) P(w_1) > P( x | w_2) P(w_2)$ - where
$P(x | w_1) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp{-\frac{(x - \mu)^2}{2\sigma^2}}$ - Boom!
- An element(x) belongs to class1 if
- Use
np.random.normal(self.mean, self.cov, self.n)for univariate andnumpy.random.multivariate_normalfor multivariate data generation
- Multivariate contours:
sns.jointplot(x="x", y="y",kind="kde", data=df); - Visualizing distributions 1D:
sns.distplot(np.random.normal(0, 0.5, 100), color="blue", hist=False, rug=True);
September 9, 2018
Karpathy's talk and ofcourse his unreasonable blog post.
- RNNs are freaking flexible:
- one to many -> Image Captioning (image to sequence of words)
- many to one -> Sentiment Classification (seq of words to positive or negative sentiment)
- many to many -> Machine Translation (seq of words to seq of words)
- many to many -> Video classification (using frame level CNNs)
- These carry state unlike regular NNs. Might not produce the same output for the same input
- Rules of thumb:
- Use RMSProp, Adam (sometimes SGD)
- Initialize forget gates with high bias (WHAT ?)
- Avoid L2 Regularization
- Use dropout along depth
- Use clip gradients (to avoid exploding gradients) (LSTMs take care of vanishing gradients)
- You can look for interpretable cells (Like one of the cell fires when there is a quote sequence going on)
- When using RNN with CNN, plug extra information(CNN's output) directly to a RNN's (green - recurrent layer)
- Use Mixture Density Networks especially when generating something.
September 8, 2018
msc
- Earned basic badge in pytorch forum.
- Finished plotting utility of train, test accuracy vs epochs and train vs test accuracy
- Finished plotting utility of loss vs epochs
- Finished plotting of Learning rate vs epochs
- To get reproducible results with torch:
torch.backends.cudnn.deterministic = True torch.manual_seed(1973) - Call
model.train()before training andmodel.eval()after training to set the mode. (It matters when you have layers like Batchnorm or Dropout) - Use
torch.nn.functional.<methods>for non linear activations etc. where the model parameters like (training=True/False) doesn't matter. If using it with dropout make sure to pass arguments training=False or use the corresponding torch.nn. (Layers).
September 2, 2018
- Finished Routing
- Permissions / Groups
- TODO
September 1, 2018
- Django Rest Framework tutorials are amazing.
- TokenAuthentication is needed for multipurpose API (But this doesn't support browsable APIs). Solution: Use SessionAuthentication as well (But this needs CSRF cookie set) Solution: Extend SessionAuthentication class and override enforce_csrf function and just return it. Boom! Browsable API with TokenAuthentication.
- Views can be Class based or function based. ViewSets are even a further abstraction over class based views (Class based views can make use of generics and mixins).
- URLs are defined separately in a file usually called
urls.py. (Use Routers if you're using ViewSets). - Model is defined by extending django.db.models.Model. All the field types are defined here:
code = models.TextField() - Serializer has to be defined for the model by extending rest_framework.serializers.HyperlinkedModelSerializer / ModelSerializer . Primary key relations etc are defined here. Serializer and Views are where the API is brewed.
- project/project/settings.py contains all the project settings and resides in
django.conf.settings.
Useful commands: - django-admin.py startproject projectname - django-admin.py startapp appname - python manage.py makemigrations - python manage.py migrate - python manage.py runserver
August 28, 2018
msc
Amazing video by Karpathy. (Timing: 1:21:47)
- Convolutional net on the frame and the low-level representation is an input to the RNN
- Make neurons in the ConvNet recurrent. Usually neurons in convnets represent a function of a local neighbourhood, but now this could also incorporate the dotproduct of it's own or neighbours previous activations making it a function of previous activations of the neighbourhood for each neuron. Each neuron in the convnet - Recurrent!
** An idea for repetition estimation: Maybe look for activation spikes in the deepvis toolbox by Jason Yosinski and train a simple classifier on them. **
- Used the
LeNetarchitecture. - Got
95%test and99%train accuracy. Is it still an overfit ?
- Coordconv layers - for sharper object generation (GANs), Convolutional Neural Networks too and definitely Reinforcement learning. Paper here
- Intrinsic Dimension - Lower Dimension representation of neural networks (Reduces Dimensions). Paper here
August 24, 2018
msc
- Implemented a Dynamic Neural Network using Pytorch's amazing dynamic Computation graphs and
torch.nn. - Fully Connected layers using
torch.nn.Linear(input_dimension, output_dimension) - Autograd is epic.
- Implemented a reusable save_model_epochs function to save model training state
- Cool Findings:
- A fairly simple Dynamic net crushes the Spiral Dataset!
- Tried the Dynamic Net (Fully connected) on Sign Language Digits Dataset and it seems to overfit (Train: 99%, Test: 85%) as expected.
- Will try to build a new net(
TenNet) to crush this set now.
- Tried Spotify's Luigi for workflow development
- Tried Threading module and decorators and ArgumentParser.
August 15, 2018
- A ConvNet architecture is in the simplest case a list of Layers that transform the image volume into an output volume (e.g. holding the class scores)
- There are a few distinct types of Layers (e.g. CONV/FC/RELU/POOL are by far the most popular)
- Each Layer accepts an input 3D volume and transforms it to an output 3D volume through a differentiable function
- Each Layer may or may not have parameters (e.g. CONV/FC do, RELU/POOL don’t)
- Each Layer may or may not have additional hyperparameters (e.g. CONV/FC/POOL do, RELU doesn’t)
- Filter = Receptive Field
- In general, setting zero padding to be P=(F−1)/2 when the stride is S=1 ensures that the input volume and output volume will have the same size spatially.
- We can compute the spatial size of the output volume as a function of the input volume size (W), the receptive field size of the Conv Layer neurons (F), the stride with which they are applied (S), and the amount of zero padding used (P) on the border. How many neurons “fit” is given by (W−F+2P)/S+1
- Parameter sharing scheme is used in Convolutional Layers to control the number of parameters. It turns out that we can dramatically reduce the number of parameters by making one reasonable assumption: That if one feature is useful to compute at some spatial position (x,y), then it should also be useful to compute at a different position (x2,y2). Only D unique set of weights (one for each depth slice)
- It is worth noting that there are only two commonly seen variations of the max pooling layer found in practice: A pooling layer with F=3,S=2 (also called overlapping pooling), and more commonly F=2,S=2. Pooling sizes with larger receptive fields are too destructive.
- Rules of thumb CNN architecture:
- The input layer (that contains the image) should be divisible by 2 many times.
- The conv layers should be using small filters (e.g. 3x3 or at most 5x5), using a stride of S=1, and crucially, padding the input volume with zeros in such way that the conv layer does not alter the spatial dimensions of the input.
- The pool layers are in charge of downsampling the spatial dimensions of the input. The most common setting is to use max-pooling with 2x2 receptive fields (i.e. F=2), and with a stride of 2 (i.e. S=2). Note that this discards exactly 75% of the activations in an input volume
- Keep in mind that ConvNet features are more generic in early layers and more original-dataset-specific in later layers.
- Transfer learning rules of thumb:
- New dataset is small and similar to original dataset. Use CNN codes (CNN as a feature descriptor)
- New dataset is large and similar to the original dataset. We can fine-tune through the full network.
- New dataset is small but very different from the original dataset. It might work better to train the SVM classifier from activations somewhere earlier in the network.
- New dataset is large and very different from the original dataset. We can fine-tune through the full network with initialized weights from a pretrained network.
- It’s common to use a smaller learning rate for ConvNet weights that are being fine-tuned, in comparison to the (randomly-initialized) weights for the new linear classifier that computes the class scores of your new dataset.
August 13, 2018
- The Bayes error defines the minimum error rate that you can hope toachieve, even if you have infinite training data and can recover the true probability distribution.
- Stochastic Gradient Descent approximates the gradient from a small number of samples.
- RMSprop is an adaptive learning rate method that reduces the learning rate using exponentially decaying average of squared gradients. Uses second moment. It smoothens the variance of the noisy gradients.
- Momentum smoothens the average. to gain faster convergence and reduced oscillation.
- Exponential weighted moving average used by RMSProp, Momentum and Adam
- Data augmentation consists in expanding the training set, for example adding noise to the training data, and it is applied before training the network.
- Early stopping, Dropout and L2 & L1 regularization are all regularization tricks applied during training.
- To deal with exploding or vanishing gradients, when we compute long-term dependencies in a RNN, use LSTM.
- In LSTMs, The memory cells contain an element to forget previous states and one to create ‘new’ memory states.
- In LSTMs Input layer and forget layer update the value of the state variable.
- Autoencoders need an encoder layer that is of different size
than the input and output layers so it doesn't learn a one on one representation
- Denoising Autoencoder: The size of the input is smaller than the size of the hidden layer (overcomplete).(use regularization!)
- Split-brain auto encoders are composed of concatenated cross-channel encoders. are able to transfer well to other, unseen tasks.
- GANs
- Unsupervised Learning:
- It can learn compression to store large datasets
- Density estimation
- Capable of generating new data samples
- "Inverse Compositional Spatial Transformer Networks." ICSTN stores the geometric warp (p) and outputs the original image, while STN only returns the warped image (Pixel information outside the cropped region is discarded).
- Fully convolutional indicates that the neural network is composed of convolutional layers without any fully-connected layers or MLP usually found at the end of the network. The main difference with CNN is that the fully convolutional net is learning filters every where. Even the decision-making layers at the end of the network are filters.
- Residual Nets - Two recent papers have shown (1) Residual Nets being equivalent to RNN and (2) Residuals Nets acting more like ensembles across several layers. The performance of an network depends on the number of short paths in the unravelled view. 1.The path lengths in residual networks follow a binomial distribution.
- Capsule - A group of neurons whose activity vector represents the instantiation parameters of a specific type of entity.
- Receptive field networks treat images as functions in Scale-Space
- Pointnets PointNets is trained to do 3D shape classification, shape part segmentation and scene semantic parsing tasks. PointNets are able to capture local structures from nearby point and the combinatorial interactions among local structures. PointNets directly consumes unordered point sets as inputs.
- Hard attention focus on multiple sharp points in the image, while soft attention focusses on smooth areas in the image
- YOLO limitations: Inappropriate treatment of error, Generalizing errors, Prediction of objects
- Curriculum Learning - Easier samples come at the beginning of the training.
July 23, 2018
Nice Numpy tricks.
- A * B in numpy is element wise and so is +, -, /, np.sqrt(A) (It will broadcast if shape not same)
- np.dot(A,B) = A.dot(B) --> Matrix Multiplication
- Use Broadcasting wherever possible (faster)
- If the arrays do not have the same rank, prepend the shape of the lower rank array with 1s until both shapes have the same length.
- In any dimension where one array had size 1 and the other array had size greater than 1, the first array behaves as if it were copied along that dimension
- One Hidden Layer NN is a universal approximator
- Always good to have more layers. (Prevent overfitting by using Regularization etc.)
-
Initialization:
- For Activation tanh =
np.random.randn(N)/sqrt(N) - For RELU =
np.random.randn(n)*sqrt(2/n) - Batch Norm makes model robust to bad initialization
- For Activation tanh =
-
Regularization: (ADDED TO LOSS at the end)
- L2 - Prefers diffused weight vectors over peaky weights = 1/2 (Lambda.W^2)
- L1 - Makes weight vectors sparse (invariant to noisy inputs) (Only a subset of neurons actually matters)
- Dropout(p=0.5) with L2(lambda cross validated) => In Practice
-
Loss = Average of losses over individual runs(training points)
$L = 1/N \sum{L_i}$ - Hinge Loss - (SVM) =>
$L_i = \sum_{j \ne y}{max(0, f_j - f_y + \delta)}$ . (Squared hinge loss also possible) ($\delta = margin$ ) - Cross Entropy - (Softmax) =>
$L_i = -log(e^{f_y} / \sum{e^{f_j}})$ - Large number of classes (Imagenet etc.) use Hierarchial Softmax.