{kind=link}
{kind=link}

Version: 0.5.0 | License: ELv2 | Last Updated: March 7, 2026
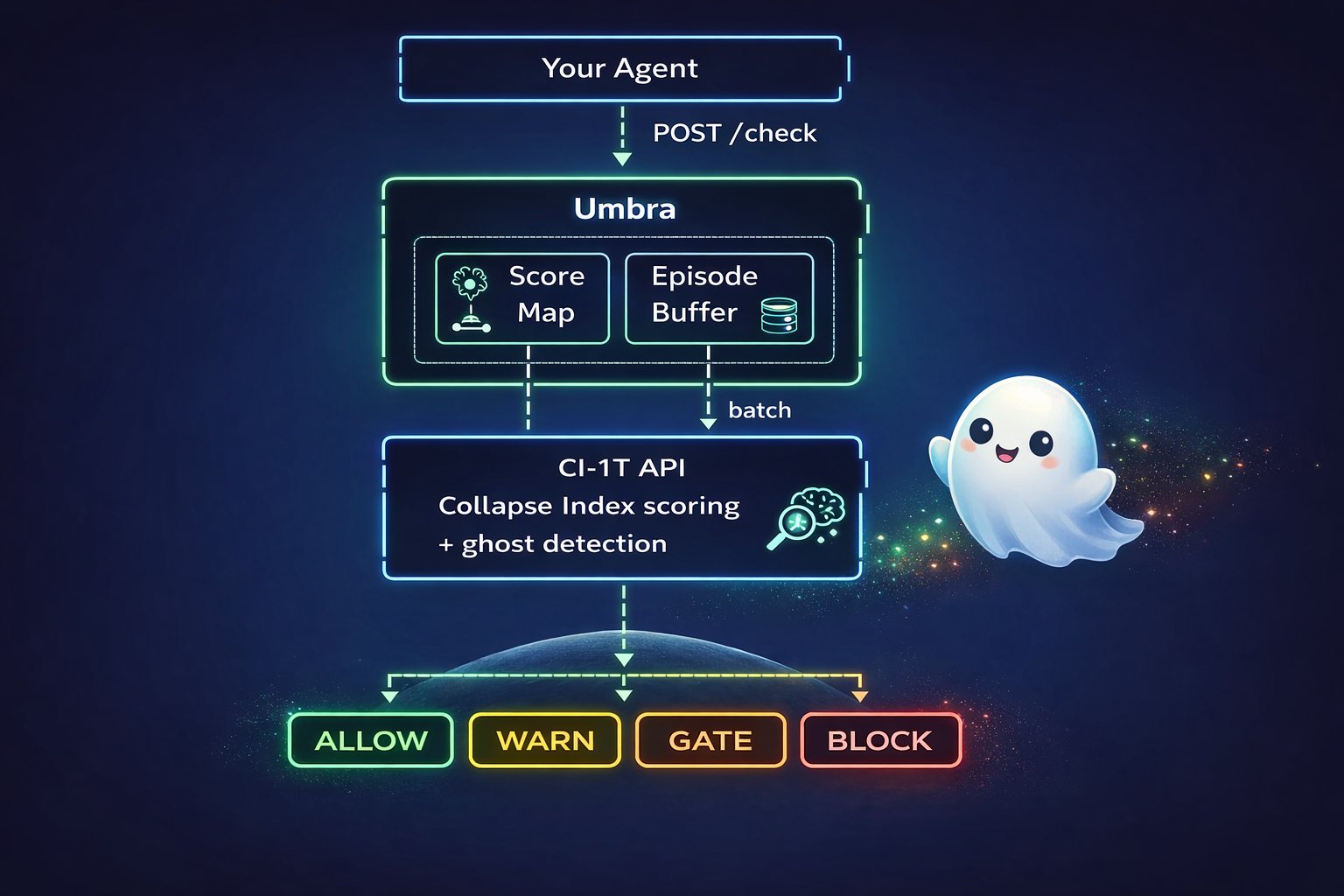
Umbra is a lightweight HTTP server powered by the CI-1T API that sits between your AI agent and the actions it wants to take. Before your agent does anything -- run a command, send a message, delete a file -- it asks Umbra first. Umbra scores the risk, tracks behavioral drift over time, and tells your agent: go ahead, be careful, wait for a human, or stop.
Umbra also ships with two optional modules:
- Multi-Agent Coordination -- influence gating, cascade propagation, and consensus authority across multiple agents working together
- CI-C1 (Structural Curiosity) -- background pattern discovery that fingerprints agent behavior and detects when agents start acting alike (or drifting apart) without you having to look
Both are disabled by default and can be turned on in umbra.yml.
It works with any agent framework (CrewAI, AutoGen, LangGraph, OpenClaw, Claude Code, custom) -- if your agent can make an HTTP call, it can use Umbra.
import requests
def safe_exec(agent, action):
r = requests.post("http://localhost:8400/check", json={
"agent": agent, "action": action
}).json()
if r["decision"] in ("gate", "block"):
raise RuntimeError(f"Umbra blocked: {r['decision']}")
return rThat's it. Your agent asks Umbra before every action. Umbra says go or stop.
pip install umbra-gateumbra setupThis walks you through creating umbra.yml -- your API key, policy mode, alerts. Takes about 30 seconds.
Need an API key? Get one free (1,000 credits, no credit card).
umbra serveThat's it. Umbra is now listening on http://localhost:8400.
Want to see a real LLM agent go through Umbra's gate? Add openrouter_key to umbra.yml, start Umbra, then run:
python scripts/demo_openrouter.pyThe demo runs a Claude Sonnet coding agent through three tasks, shows the gate decision for each tool call, and saves a timestamped JSON report in data/generated/.
The simple version:
risk score --> threshold --> ALLOW / WARN / GATE / BLOCK
The full version: every action gets a risk score (from the risk map below). Umbra batches scores into episodes and sends them to CI-1T for evaluation. CI-1T returns a Collapse Index (how unstable your agent's behavior is) and an Authority Level (how much trust to give). Umbra maps that to a decision:
| AL | Meaning | Decision | Your agent should... |
|---|---|---|---|
| 0-1 | High trust | ALLOW | Proceed normally |
| 2 | Moderate | WARN | Proceed, but a warning is logged |
| 3 | Low trust | GATE | Pause and wait for human approval |
| 4 | No trust | BLOCK | Stop immediately |
| -- | Ghost detected | BLOCK | Stop immediately |
Ghost detection catches agents that are suspiciously consistent -- stable, confident, but hiding errors.
Policy modes:
monitor-- log everything, never block (good for testing)enforce-- actually gate/block at AL3+ (production)
POST /check
Call this before your agent executes an action.
{ "agent": "my-agent", "action": "terminal_exec" }Fields:
| Field | Type | Required | Description |
|---|---|---|---|
agent |
string | No | Agent name (default: "default"). Each agent gets its own session. |
action |
string | Yes* | Action type from the risk map (see below) |
escalation |
bool | No | Flag as dangerous (+0.25 risk boost) |
score |
int | Yes* | Raw Q0.16 score (0-65535). Use instead of action for custom scoring. |
*Provide action or score (one is required).
Response (still buffering):
{ "decision": "allow", "buffered": true, "agent": "my-agent" }Response (full evaluation):
{
"agent": "my-agent",
"decision": "gate",
"al": 3,
"al_label": "Low trust -- gating active",
"ci": 0.6872,
"ghost_confirmed": false,
"credits_remaining": 488
}POST /report
Same payload as /check, but returns immediately. Use for actions you want to track but not gate.
GET /status # All agents
GET /status/{agent} # One agent
GET /health
DELETE /sessions/{agent}
Deletes the fleet session on CI-1T and clears all local state for that agent.
POST /consensus
When multiple agents collaborate on a decision, the effective authority is the minimum AL of all contributors. One unstable agent drags down the whole group.
{ "agents": ["coding-agent", "research-agent", "deploy-agent"] }Response:
{
"effective_al": 3,
"explanation": "AL3 (limited by deploy-agent)",
"agents": {
"coding-agent": { "al": 1 },
"research-agent": { "al": 0 },
"deploy-agent": { "al": 3 }
}
}GET /causal/{agent}
Returns the upstream agents that triggered actions in this agent (via triggered_by).
{
"agent": "deploy-agent",
"upstream": [
{ "agent": "coding-agent", "hops": 1 },
{ "agent": "manager-agent", "hops": 2 }
]
}GET /discoveries?agent=bot-1&limit=20
Returns recent pattern discoveries from the curiosity engine. Only available when curiosity.enabled: true.
{
"discoveries": [
{
"match_type": "cross_agent",
"agent_a": "coding-bot",
"agent_b": "deploy-bot",
"similarity": 0.92,
"explanation": "coding-bot and deploy-bot are exhibiting similar behavior (92% match)...",
"cycle": 14,
"window_a": { "start": 1709721600, "end": 1709722200, "index": 0 },
"window_b": { "start": 1709721600, "end": 1709722200, "index": 0 }
}
],
"cycle_count": 14
}Umbra ships with 17 built-in action types. You can override any of them in umbra.yml.
| Action | Risk | Action | Risk | |
|---|---|---|---|---|
file_read |
0.05 | terminal_exec |
0.50 | |
search |
0.05 | bash_execute |
0.50 | |
web_browse |
0.20 | unknown |
0.50 | |
file_write |
0.25 | spawn_agent |
0.60 | |
api_call |
0.30 | config_modify |
0.65 | |
message |
0.40 | permission_change |
0.85 | |
delete_file |
0.40 | credential_access |
0.90 | |
install_package |
0.45 | self_modify |
0.90 | |
external_upload |
0.90 |
Custom actions: Use dotted namespaces for actions not in the default map. Anything Umbra doesn't recognize gets the unknown risk (0.50).
# umbra.yml
risk_map:
cloud.deploy: 0.80
db.query: 0.35
git.push: 0.45
browser.click: 0.15Umbra tracks every decision and episode. Query them at runtime:
GET /decisions Last 100 decisions across all agents
GET /decisions?agent=my-agent Decisions for one agent
GET /episodes Episode history (CI scores, ghost flags)
GET /episodes?agent=my-agent Episodes for one agent
All data is in-memory and resets on restart.
Experimental. This feature is new in v0.4.0. The API surface (field names, endpoint behavior, cascade math) may change in future releases based on real-world usage. Causal graphs and cascade penalties are held in-memory and reset on restart. Not yet battle-tested in high-throughput production environments. If you run into issues, please report them.
When you have multiple agents working together, Umbra can track causal relationships and enforce cross-agent governance. Enable it in umbra.yml:
multi_agent:
enabled: trueThree features, all opt-in:
Agent A at AL3 cannot trigger a high-risk action in Agent B. Authority does not transfer upward. Pass triggered_by on /check:
requests.post("http://localhost:8400/check", json={
"agent": "deploy-bot",
"action": "credential_access",
"triggered_by": "research-bot" # Is research-bot trusted enough?
})If the triggering agent lacks authority, Umbra blocks with influence_gated: true.
| Action risk | Required triggering AL |
|---|---|
| High (> 0.6) | AL 0-1 |
| Medium (0.3-0.6) | AL 0-2 |
| Low (< 0.3) | Any AL |
When Agent C goes unstable and was triggered by Agent A (via Agent B), a penalty score propagates backward through the causal chain:
- Agent B gets 50% of Agent C's instability
- Agent A gets 25% (attenuated by hop distance)
- Max 4 hops, 50% decay per hop
This holds upstream agents accountable for bad delegation without nuking the whole system.
When multiple agents collaborate, the effective authority is the minimum AL of all participants. One unstable agent drags down the group:
requests.post("http://localhost:8400/consensus", json={
"agents": ["coding-bot", "review-bot", "deploy-bot"]
})
# -> {"effective_al": 3, "explanation": "AL3 (limited by deploy-bot)"}Check this before executing a group decision. If one agent is untrusted, wait for it to stabilize or exclude it.
multi_agent:
enabled: true # Enable multi-agent coordination (default: false)
cascade: true # Enable cascade propagation (default: true)
influence_gating: true # Enable influence gating (default: true)
cascade_decay: 0.5 # Attenuation per hop (default: 0.5)
cascade_max_hops: 4 # Max causal chain depth (default: 4)
causal_edge_ttl: 600 # Seconds before causal edges expire (default: 600)Experimental. CI-C1 is new in v0.5.0. Behavioral fingerprinting and pattern matching are performed in-memory and reset on restart. Discovery explanations are template-based (no LLM calls). The fingerprint dimensions, similarity math, and cooldown logic may change in future releases.
Traditional monitoring tells you when something goes wrong. CI-C1 tells you when something looks familiar. If your coding agent starts behaving like your deploy agent did right before it went unstable last Thursday, CI-C1 catches that. If two agents that shouldn't be related start drifting in lockstep, CI-C1 catches that too. It finds the patterns you didn't know to look for, before they become incidents.
The problem it solves: rule-based detectors only catch what you anticipated. CI-C1 watches behavioral shape across time and across agents, surfacing structural similarities that no one wrote a rule for. A single agent running alone gets self-temporal matching (is it repeating a past failure pattern?). A fleet gets cross-agent and cross-temporal matching on top of that.
Works with a single agent or an entire fleet. No configuration beyond enabled: true.
Enable it:
curiosity:
enabled: trueEvery cycle_interval seconds (default: 60), CI-C1:
- Fingerprints each agent's recent behavior over a sliding window (default: last 10 episodes). Each fingerprint captures 8 dimensions: mean CI, CI variance, trend (slope), volatility (direction changes), max/min CI, AL transition rate, and ghost rate.
- Compares fingerprints pairwise using structural similarity (a blend of cosine for shape and euclidean distance for magnitude, so agents at different CI levels don't false-match).
- Surfaces discoveries above the similarity threshold (default: 0.75).
Three match modes:
| Mode | What it finds | Example |
|---|---|---|
| Self-temporal | Agent's current behavior matches its own past pattern | "bot-1's current trajectory (89% match) resembles its own pattern from 2h ago" |
| Cross-agent | Two agents exhibiting similar behavior right now | "coding-bot and deploy-bot are behaving similarly (93% match)" |
| Cross-temporal | Agent A now matches Agent B's past pattern | "bot-1's current behavior (85% match) resembles bot-2's pattern from 45m ago" |
Self-temporal skips the immediately previous window (always trivially similar for stable agents) and only compares against windows 2+ back, so it catches recurrence after change, not steady-state confirmation.
A cooldown mechanism (default: 5 cycles) prevents the same match from flooding discoveries.
resp = requests.get("http://localhost:8400/discoveries", params={"agent": "bot-1"})
for d in resp.json()["discoveries"]:
print(f"[{d['match_type']}] {d['explanation']}")curiosity:
enabled: true # Enable the curiosity engine (default: false)
cycle_interval: 60 # Seconds between cycles (default: 60)
window_size: 10 # Episodes per fingerprint window (default: 10)
history_depth: 20 # Past windows kept per agent (default: 20)
similarity_threshold: 0.75 # Minimum cosine similarity (default: 0.75)
cooldown_cycles: 5 # Cycles before re-reporting same pair (default: 5)Each window of N episodes produces an 8-value vector:
| Dimension | What it captures |
|---|---|
mean_ci |
Average CI score (0.0-1.0) |
std_ci |
Score variance within the window |
trend |
Linear slope: negative = improving, positive = degrading |
volatility |
Direction changes / (n-2): 0 = monotone, 1 = zigzag |
max_ci |
Worst CI score in window |
min_ci |
Best CI score in window |
al_changes |
Authority level transitions / n |
ghost_rate |
Fraction of episodes flagged as ghost suspects |
Comparing two fingerprints is 8 multiplies + a square root + a magnitude penalty on 4 dimensions. At 50 agents with 20 historical windows each, the entire matching cycle runs in microseconds.
import requests
def check(action, agent="my-agent", escalation=False):
resp = requests.post("http://localhost:8400/check", json={
"agent": agent, "action": action, "escalation": escalation
})
return resp.json()
result = check("terminal_exec")
if result["decision"] in ("gate", "block"):
print(f"Blocked: AL={result.get('al')}")const resp = await fetch("http://localhost:8400/check", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ agent: "my-agent", action: "terminal_exec" }),
});
const { decision } = await resp.json();curl -X POST http://localhost:8400/check \
-H "Content-Type: application/json" \
-d '{"agent": "test", "action": "terminal_exec"}'umbra.yml is created by umbra setup. Here's the full schema:
port: 8400
host: "0.0.0.0"
# CI-1T API key (or use CI1T_API_KEY env var)
api_key: ""
api_url: "https://collapseindex.org/api"
# "monitor" = log everything, never block (safe for testing)
# "enforce" = gate at AL3, block at AL4 and confirmed ghosts (production)
policy: "monitor"
# Actions per evaluation round (2-8, default: 3)
# Lower = faster reactions but noisier, higher = smoother but slower to catch drift
episode_size: 3
# Override risk scores (0.0 = no risk, 1.0 = maximum risk)
risk_map:
terminal_exec: 0.70
file_read: 0.02
# Alerts (all opt-in)
alerts:
min_level: "AL3" # Minimum authority level to trigger alerts
slack:
webhook_url: "https://hooks.slack.com/services/..."
email:
smtp_host: "smtp.gmail.com"
smtp_port: 587
smtp_user: "you@gmail.com"
smtp_pass: ""
from_addr: "umbra@yourdomain.com"
to_addrs: ["ops@yourdomain.com"]
sms:
account_sid: ""
auth_token: ""
from_number: "+15551234567"
to_numbers: ["+15559876543"]
# Credit monitoring
credits:
low_warning: 100 # Alert when credits drop below this
check_interval: 10 # Check credits every N episodes
# Multi-agent coordination (disabled by default)
multi_agent:
enabled: false
cascade: true # Propagate instability to upstream agents
influence_gating: true # Block cross-agent actions above triggering agent's AL
cascade_decay: 0.5 # Attenuation per hop (50%)
cascade_max_hops: 4 # Max causal chain depth
causal_edge_ttl: 600 # Seconds before causal edges expire
# CI-C1: Curiosity engine (disabled by default)
curiosity:
enabled: false
cycle_interval: 60 # Seconds between curiosity cycles
window_size: 10 # Episodes per behavioral fingerprint
history_depth: 20 # Past windows to keep per agent
similarity_threshold: 0.75 # Minimum structural similarity to surface
cooldown_cycles: 5 # Cycles before re-reporting same match
# OpenRouter key (optional, for demo scripts)
# Can also use OPENROUTER_API_KEY env var
# openrouter_key: "sk-or-..."| Variable | Overrides |
|---|---|
CI1T_API_KEY |
api_key in config |
CI1T_SLACK_WEBHOOK |
alerts.slack.webhook_url |
CI1T_SMTP_PASS |
alerts.email.smtp_pass |
CI1T_TWILIO_SID |
alerts.sms.account_sid |
CI1T_TWILIO_TOKEN |
alerts.sms.auth_token |
OPENROUTER_API_KEY |
openrouter_key (used by demo scripts) |
docker run -d \
-e CI1T_API_KEY=ci_your_key \
-p 8400:8400 \
-v ./umbra.yml:/app/umbra.yml:ro \
collapseindex/umbraOr build locally:
docker build -t umbra .
docker compose up -dumbra setup Create umbra.yml interactively
umbra serve Start the server
umbra serve --port 9000 Override port
umbra serve --policy enforce Override policy mode
umbra status Check a running server's status
umbra --version Print version
Passed full automated audit: bandit (0 findings), flake8 (0 errors), pip-audit (0 vulnerabilities).
Highlights:
- API keys masked in all logs, repr, and tracebacks
- Input validation on all fields (agent names, action types, scores, body size)
- YAML loaded with
safe_load()only - Rate limiting (200 req/60s) on POST endpoints
- Max 500 concurrent sessions, 1MB config limit
- Error responses never leak internal details
- All alert channels (Slack, email, SMS) are opt-in
Run it yourself:
python -m bandit -r umbra/ -q
python -m flake8 umbra/ --max-line-length 120
python -m pip_audit -r requirements.txt
python -m pytest tests/ -qReport vulnerabilities to ask@collapseindex.org (not public issues).
umbra/
__init__.py config.py scorer.py alerts.py
__main__.py server.py policy.py setup.py
sessions.py multi.py curiosity.py
tests/
test_core.py test_server.py test_multi.py test_curiosity.py
scripts/
demo_curiosity.py # Multi-agent CI-C1 demo
demo_openrouter.py # Live LLM agent demo (Claude via OpenRouter)
umbra.example.yml Dockerfile docker-compose.yml
pyproject.toml requirements.txt
- CI-C1: Structural Curiosity Engine. Background pattern discovery across agent behavioral trajectories
- 8-dimensional behavioral fingerprinting (mean CI, variance, trend, volatility, max/min, AL changes, ghost rate)
- Three match modes: self-temporal, cross-agent, cross-temporal
- Structural similarity: 40% cosine (shape) + 60% magnitude penalty so agents at different CI levels don't false-match
- Cooldown-based dedup to prevent discovery flooding
- New endpoint:
GET /discoveries curiosityconfig section inumbra.yml(disabled by default)openrouter_keyconfig field for live LLM demo scripts- OpenRouter demo script: test real LLMs (Claude Sonnet 4) through Umbra's gate
- 50 new tests (153 total)
- Security audit: sanitized all path/query params, body size validation on raw bytes before JSON parse, removed error info disclosure, default example host to 127.0.0.1
- Passed bandit, flake8, pip-audit (0 findings)
- Multi-agent coordination: influence gating, cascade propagation, consensus authority
- New endpoints:
POST /consensus,GET /causal/{agent} - New
triggered_byfield on/checkfor declaring causal relationships multi_agentconfig section inumbra.yml(disabled by default)- 36 new tests (103 total)
- Architecture diagram in README
- 30-second integration snippet
- Simplified how-it-works mental model (risk score -> threshold -> decision)
- Dotted action namespaces (
cloud.deploy,db.query) with domain fallback - Observability endpoints:
GET /decisionsandGET /episodeswith agent filtering - Custom actions section in docs
- 8 new tests (67 total)
- Renamed project from ci1t-gate to Umbra
- PyPI:
umbra-gate/ CLI:umbra/ Config:umbra.yml/ Import:from umbra import ...
- Full security audit (bandit, flake8, pip-audit -- all clean)
- Added key masking, input sanitization, rate limiting, session limits
- Fixed error info leaks, header injection, Content-Length crash
- 22 new security tests (59 total)
- Initial release -- HTTP server, fleet sessions, risk scoring, policy enforcement, ghost detection, alerts (Slack/email/SMS), setup wizard, Docker
Copyright 2026 Alex Kwon (Collapse Index Labs)
Elastic License 2.0 (ELv2) -- free to use, modify, and self-host. The only restriction is you can't offer Umbra as a hosted/managed service.
"though love is hard to see, you're still real here with me."