Introduction
Ce projet a abordé l'aspect crucial de la programmation répartie : le calcul parallèle, plus spécifiquement, la parallélisation des données. L'objectif était de réaliser un traitement intensif de données, compliqué à accomplir sur un ordinateur personnel. Pour cela, nous avons utilisé un ensemble de machines pour décomposer le calcul en plusieurs parties, chacune étant transmise à une machine différente pour être calculée. Les résultats ont ensuite été combinés pour obtenir le résultat final.
Dans ce projet, nous nous sommes concentrés sur une tâche qui nécessite une grande quantité de cycles CPU : la synthèse d'images, plus précisément, le tracé de rayon (raytracing). Nous avons utilisé une implantation en Java d'un algorithme de synthèse d'images. La scène calculée était décrite dans le fichier simple.txt.
En expérimentant avec différents paramètres du programme, nous avons observé le temps d'exécution en fonction de la taille de l'image calculée.
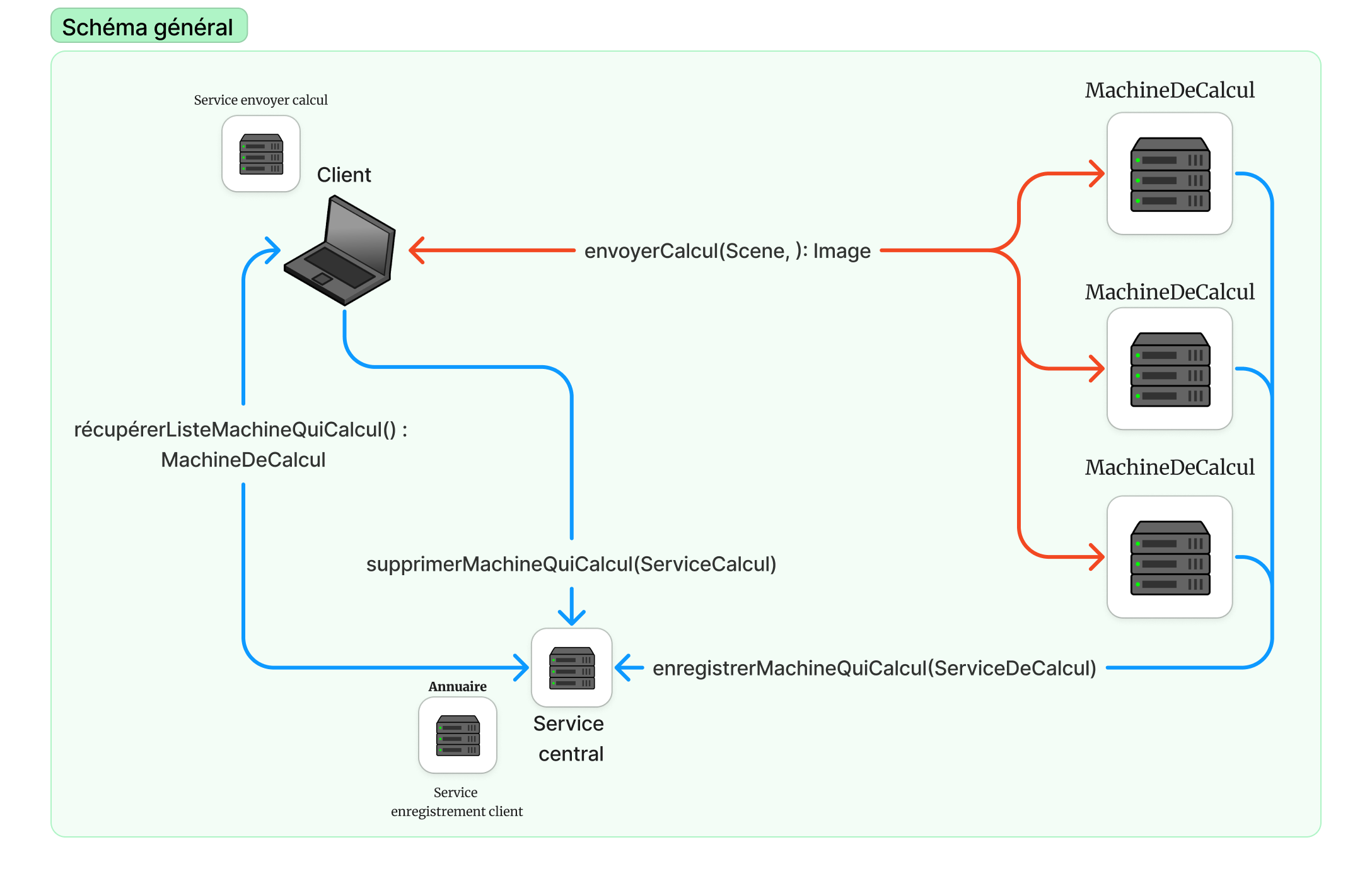
Le constat a été que le calcul d'une image de haute résolution demandait beaucoup de temps. Pour y remédier, nous avons décidé de paralléliser les calculs sur un ensemble de machines. L'architecture consistait en :
Un ensemble de nœuds de calcul, capable de calculer une partie d'une scène (Le service calcul),
Un serveur pour récupérer les nœuds de calcul (Le serveur central),
Un programme pour découper le calcul, récupérer les coordonnées des nœuds disponibles, envoyer un calcul sur chacun et afficher le résultat (Le client).
En faisant cela, nous avons réussi à accélérer les calculs en distribuant les tâches sur plusieurs machines, prouvant ainsi l'efficacité de la parallélisation des données.