유튜브 링크 : https://youtu.be/5BqI4m-KHgc
꽃 생장 파악 알고리즘(CNN, Classification etc)권석준, 기계공학부, jun115533@hanyang.ac.kr
김경휘, 기계공학부, kyunghui98@hanyang.ac.kr
홍종호, 기계공학부, hjho6389@hanyang.ac.kr
1. Motivation
2. Datasets
3. Methodology
4. Evaluation & Analysis
5. Result
6. Conclusion : Dicussion
7. Related Works세계적인 식량 문제로 인해, 스마트팜에 대한 관심이 늘어나고 있고 개인용 소형 스마트팜의 보급 및 여러 고부가가치 작물에 대한 기술의 수요가 증가하고 있는 상황입니다. 이러한 상황에서, 꽃의 생장 단계 및 생장 상황을 파악하는 딥러닝 알고리즘에 대한 개발을 시도해보고자 이번 프로젝트를 기획하게 되었습니다.
스마트팜용 꽃 생장 파악 알고리즘
Mission1. 식물의 생장 상황을 파악 : 병들었는지 아닌지 구별
- 팁번 : 나뭇잎 끝이 누렇게 변하는 현상
- 영양분이 부족하거나, 물이 부족하거나 등등의 원인으로 인해 생기는 현상 팁번처럼, 지금 싱싱한지 아닌지를 파악
Mission2. 꽃의 개화 상태를 파악 2. 꽃 사진을 입력했을 때, 이게 꽃이 폈는지 아닌지 파악
- 사진의 색 구성 비율을 분석하여 개화하였는지 아닌지 파악
https://docs.google.com/spreadsheets/d/1mdLbku2yM-XiBmN0Lm_O82xbFbpup1E1mkY1KXwGuds/edit#gid=0
https://www.kaggle.com/datasets/cf488efb70f71b0db8c5a69539ea35874787d4a4ab835126168e7af1723418d7
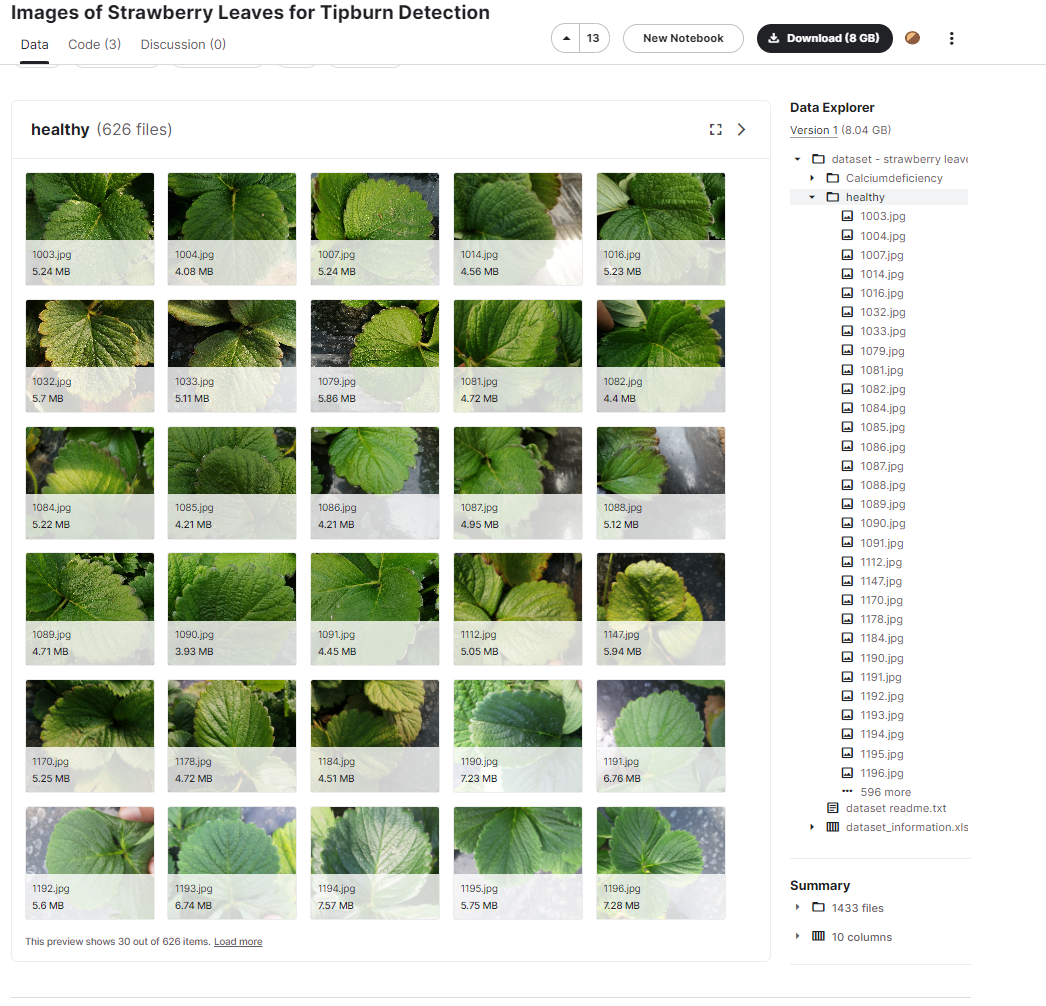
본 이미지는 kaggle 사이트에서 각 calciumdeficiency 사진 805장과 건강한 잎 626장을 데이터 셋으로 불러왔습니다. 구글 드라이브를 통해 총 1431의 파일을 저장하여 이를 colab으로 불러와 꽃 사진을 분류하는 프로그램을 진행하였고 kaggle 사이트에서 가져온 1431의 사진 파일과 10 columns 뿐만 아니라 구글에서 따로 이미지 크롤링을 python 셀레니움을 통해 자동으로 정리하는 시스템을 갖춰보았습니다.
VSCODE를 사용하여 가상환경에서 셀레니움을 설치한다. 이후 구글에서 이미지 크롤링이 가능한 코드를 입력하여 검색어("Tipburn","Healthy leaf"),를 바꾸어가며 이미지를 수집하고, 사용 가능한 데이터를 정리한다.
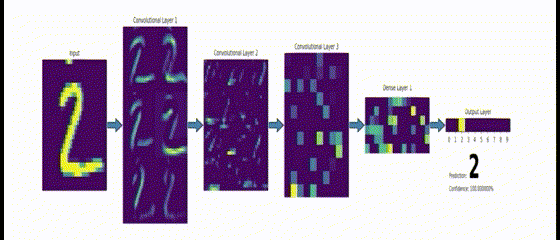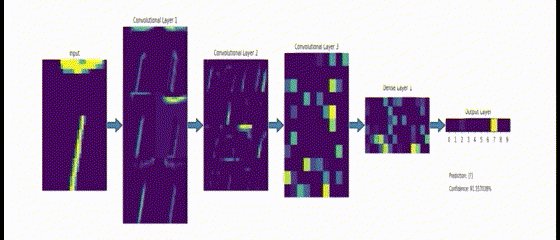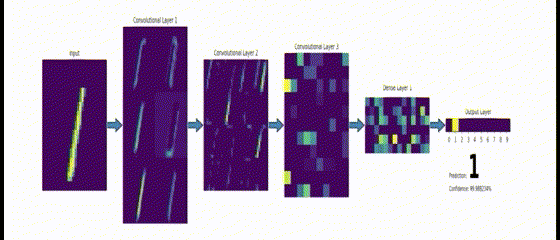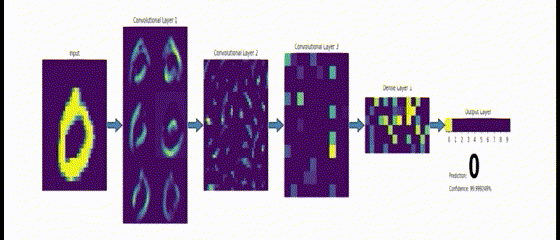
CNN은 Convolutional Neural Networks의 약자로 합성곱 전처리 작업이 들어가는 신경망 모델입니다. 날 것의 이미지를 그대로 받으면서 공간적/지역적 정보를 유지한 채 특성들의 계층을 빌드업하는 형식으로 중요 포인트는 이미지 전체보다는 부분을 보는 것으로 이미지의 한 픽셀과 주변 픽셀들의 연관성을 살립니다. 인간의 시신경 구조를 모방하는 기술인 CNN은 이미지를 인식하기 위해 패턴을 찾는데 특히 유용하며 데이터를 직접 학습하고 패턴을 사용해 이미지의 공간 정보를 유지한 채 학습을 하게 되는 모델입니다.
CNN(Convolutional Neural Network)은 기존 Fully Connected Neural Network와 비교하여 다음과 같은 차별성을 갖습니다.
- 각 레이어의 입출력 데이터의 형상 유지
- 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식
- 복수의 필터로 이미지의 특징 추출 및 학습
- 추출한 이미지의 특징을 모으고 강화하는 Pooling 레이어
- 필터를 공유 파라미터로 사용하기 때문에, 일반 인공 신경망과 비교하여 학습 파라미터가 매우 적음
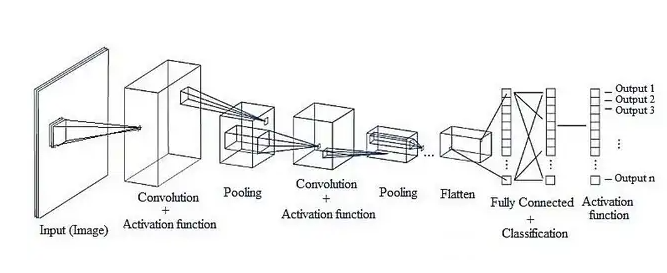
CNN은 위 이미지와 같이 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나눌 수 있습니다. 특징 추출 영역은 Convolution Layer와 Pooling Layer를 여러 겹 쌓는 형태로 구성됩니다. Convolution Layer는 입력 데이터에 필터를 적용 후 활성화 함수를 반영하는 필수 요소입니다. Convolution Layer 다음에 위치하는 Pooling Layer는 선택적인 레이어입니다. CNN 마지막 부분에는 이미지 분류를 위한 Fully Connected 레이어가 추가됩니다. 이미지의 특징을 추출하는 부분과 이미지를 분류하는 부분 사이에 이미지 형태의 데이터를 배열 형태로 만드는 Flatten 레이어가 위치 합니다.

우리는 CNN의 딥러닝 기법을 활용하여 각 잎의 픽셀 별로 공간을 유지한채 색상을 파악할 예정입니다. 그리고 색상에 따라 이것이 건강한 잎인지 아닌지를 구별하면서 모델을 구현하고 추가로 이 CNN을 활용했을 때 나타나는 변수들을 설정하고 그에 따른 결과치를 정확도를 비교하여 분석하였습니다.
OpenCV란? : Open Source Computer Vision의 약자로 다양한 영상/동영상 처리에 사용할 수 있는 오픈소스 라이브러리입니다.

오픈 소스로 현재도 활발하게 개발이 되고 있는 컴퓨터 비전 및 머신 러닝 라이브러리이며 , 약 2500여 개 가 넘는 여러 최신 비전 , 머신러닝 알고리즘과 기본적인 영상처리 , 객체 검출 , 객체 인식 , 객체 추적 등등 영상처리 관련 문제 해결을 위한 알고리즘을 제공하고 현재도 활발하게 여러 알고리즘이 개발이 되고 있습니다.
저희는 OpenCV의 다양한 기능을 활용하여, 이미지의 색깔 비율을 분석(녹색vs비녹색)하고 이 비율에 따라 일정 비율 이상의 비녹색이 검출되었을때 개화로 판단하는 코드를 작성하였습니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
from attr import Attribute
import urllib.request
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&authuser=0&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys("healthy leaf")
elem.send_keys(Keys.RETURN)
SCROLL_PAUSE_TIME = 1
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
driver.find_element(By.CSS_SELECTOR,".mye4qd").click()
except:
break
last_height = new_height
images=driver.find_elements(By.CSS_SELECTOR,'.rg_i.Q4LuWd')
count=1
for image in images:
try:
image.click()
time.sleep(2)
imgUrl=driver.find_element(By.XPATH,"/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div/div/div/div[3]/div[2]/c-wiz/div[2]/div[1]/div[1]/div[2]/div/a/img").get_attribute("src")
urllib.request.urlretrieve(imgUrl,str(count)+".jpg")
count=count+1
except:
pass
driver.close()
from google.colab import drive
drive.mount('/content/drive')Mounted at /content/drive
import os* 드라이브와 OS를 import하면서 사진을 부를 장소를 정합니다. * model1을 제작할때 사용한 코드입니다.
# 수정된 디렉토리
train_healthy_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/train/healthy'
train_tipburn_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/train/tipburn'
val_healthy_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/val/healthy'
val_tipburn_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/val/tipburn'
test_healthy_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/test/healthy'
test_tipburn_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/test/tipburn'print('훈련용 건강 이미지 전체 개수:',len(os.listdir(train_healthy_dir)))
print('훈련용 팁번 이미지 전체 개수:',len(os.listdir(train_tipburn_dir)))
print('검증용 건강 이미지 전체 개수:',len(os.listdir(val_healthy_dir)))
print('검증용 팁번 이미지 전체 개수:',len(os.listdir(val_tipburn_dir)))
print('테스트용 건강 이미지 전체 개수:',len(os.listdir(test_healthy_dir)))
print('테스트용 팁번 이미지 전체 개수:',len(os.listdir(test_tipburn_dir)))
훈련용 건강 이미지 전체 개수: 443
훈련용 팁번 이미지 전체 개수: 568
검증용 건강 이미지 전체 개수: 124
검증용 팁번 이미지 전체 개수: 160
테스트용 건강 이미지 전체 개수: 59
테스트용 팁번 이미지 전체 개수: 77
train_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/train'
val_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/val'
test_dir = '/content/drive/MyDrive/Colab Notebooks/tip burn project/test'- 구글 드라이브에 저장한 건강, 팁번 이미지들을 불러모으고 각각 훈련, 검증, 테스트용으로 분류하고 수량을 파악합니다.
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
val_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')Found 1011 images belonging to 2 classes.
Found 284 images belonging to 2 classes.
for data_batch, labels_batch in train_generator:
print('배치 데이터 크기:', data_batch.shape)
print('배치 레이블 크기:', labels_batch.shape)
break배치 데이터 크기: (20, 150, 150, 3)
배치 레이블 크기: (20,)
- 데이터 전처리를 진행하며 이미지를 1/255로 스케일 조정을 진행합니다.
- 모든 이미지를 150 × 150 크기로 타깃 디레터리를 설정 후 타깃 사이즈와 batch 사이즈를 정해줍니다.
- Binary_crossentropy 손실을 사용하기 때문에 이진 레이블이 필요하다.
- 배치 데이터와 레이블 크기를 확합니다.
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))model.summary()# 결과
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 32) 896
max_pooling2d (MaxPooling2D (None, 74, 74, 32) 0
)
conv2d_1 (Conv2D) (None, 72, 72, 64) 18496
max_pooling2d_1 (MaxPooling (None, 36, 36, 64) 0
2D)
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
max_pooling2d_2 (MaxPooling (None, 17, 17, 128) 0
2D)
conv2d_3 (Conv2D) (None, 15, 15, 128) 147584
max_pooling2d_3 (MaxPooling (None, 7, 7, 128) 0
2D)
flatten (Flatten) (None, 6272) 0
dense (Dense) (None, 512) 3211776
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
- 모델 구성에 있어서 층 개수를 conv2d & maxpooling layer를 추가 또는 Dense를 추가합니다.
- Conv2D의 layer는 64,128,256 중으로 설정을 진행하였고 model을 구사합니다.
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])- adam VS RMSprop를 변수로서 비교해봅니다.
- lr : learning rate로 10^-5 ~ 10^-4로 설정합니다. model1 같은 경우 1e-4로 설정하였습니다.
history = model.fit(
train_generator,
steps_per_epoch=20,
epochs=20,
validation_data=validation_generator,
validation_steps=10)Epoch 1/20
20/20 [==============================]-465s 23s/step-loss: 0.6485-acc: 0.5725-val_loss: 0.7634-val_acc: 0.5300
Epoch 2/20
20/20 [==============================]-311s 16s/step-loss: 0.5611-acc: 0.7033-val_loss: 0.4494-val_acc: 0.9100
Epoch 3/20
20/20 [==============================]-273s 14s/step-loss: 0.4729-acc: 0.7850-val_loss: 0.3925-val_acc: 0.8750
Epoch 4/20
20/20 [==============================]-235s 12s/step-loss: 0.4515-acc: 0.8075-val_loss: 0.6618-val_acc: 0.5750
Epoch 5/20
20/20 [==============================]-223s 11s/step-loss: 0.4510-acc: 0.7852-val_loss: 0.3226-val_acc: 0.9050
Epoch 6/20
20/20 [==============================]-217s 11s/step-loss: 0.3914-acc: 0.8286-val_loss: 0.3777-val_acc: 0.8050
Epoch 7/20
20/20 [==============================]-216s 11s/step-loss: 0.3870-acc: 0.8363-val_loss: 0.2941-val_acc: 0.9150
Epoch 8/20
20/20 [==============================]-211s 11s/step-loss: 0.3699-acc: 0.8107-val_loss: 0.3181-val_acc: 0.8800
Epoch 9/20
20/20 [==============================]-216s 11s/step-loss: 0.3739-acc: 0.8389-val_loss: 0.2470-val_acc: 0.9250
Epoch 10/20
20/20 [==============================]-210s 11s/step-loss: 0.3467-acc: 0.8491-val_loss: 0.3798-val_acc: 0.8200
Epoch 11/20
20/20 [==============================]-208s 11s/step-loss: 0.3650-acc: 0.8275-val_loss: 0.2437-val_acc: 0.9350
Epoch 12/20
20/20 [==============================]-212s 11s/step-loss: 0.3645-acc: 0.8325-val_loss: 0.2999-val_acc: 0.8800
Epoch 13/20
20/20 [==============================]-209s 11s/step-loss: 0.3255-acc: 0.8491-val_loss: 0.2548-val_acc: 0.9150
Epoch 14/20
20/20 [==============================]-206s 11s/step-loss: 0.3061-acc: 0.8696-val_loss: 0.2315-val_acc: 0.9250
Epoch 15/20
20/20 [==============================]-211s 11s/step-loss: 0.3108-acc: 0.8525-val_loss: 0.2508-val_acc: 0.9250
Epoch 16/20
20/20 [==============================]-211s 11s/step-loss: 0.3152-acc: 0.8650-val_loss: 0.4235-val_acc: 0.8100
Epoch 17/20
20/20 [==============================]-206s 10s/step-loss: 0.2784-acc: 0.8824-val_loss: 0.3082-val_acc: 0.8500
Epoch 18/20
20/20 [==============================]-204s 10s/step-loss: 0.2979-acc: 0.8696-val_loss: 0.2377-val_acc: 0.9200
Epoch 19/20
20/20 [==============================]-204s 10s/step-loss: 0.2837-acc: 0.8645-val_loss: 0.2524-val_acc: 0.9100
Epoch 20/20
20/20 [==============================]-206s 10s/step-loss: 0.2850-acc: 0.8798-val_loss: 0.2320-val_acc: 0.9250
- steps per epoch : 한 epoch에서 몇 단계로 학습을 할 것인지 결정합니다.
- epoch수와 배치수라는 parameter를 조정하면서 오차를 개선할 것입니다.
from keras.models import load_model
model.save('/content/drive/MyDrive/Colab Notebooks/tip burn project/model/model.h5')from keras.models import load_model
model = load_model('/content/drive/MyDrive/Colab Notebooks/tip burn project/model/model.h5')
model.summary()#결과
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 32) 896
max_pooling2d (MaxPooling2D (None, 74, 74, 32) 0
)
conv2d_1 (Conv2D) (None, 72, 72, 64) 18496
max_pooling2d_1 (MaxPooling (None, 36, 36, 64) 0
2D)
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
max_pooling2d_2 (MaxPooling (None, 17, 17, 128) 0
2D)
conv2d_3 (Conv2D) (None, 15, 15, 128) 147584
max_pooling2d_3 (MaxPooling (None, 7, 7, 128) 0
2D)
flatten (Flatten) (None, 6272) 0
dense (Dense) (None, 512) 3211776
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
- 변수들을 설정한뒤 다시 모델을 불러옵니다.
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()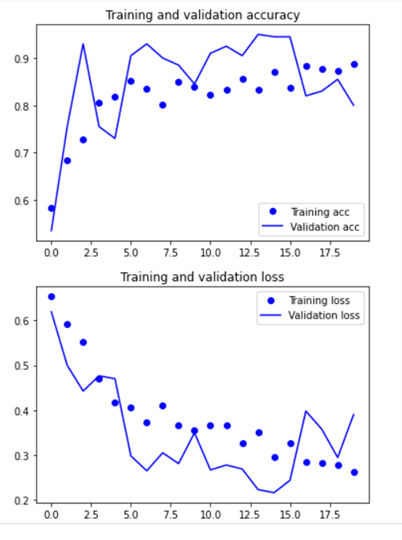
- 최종적으로 matplotlib를 불러와 플롯을 통해 정확도를 측정합니다.
- 오차를 줄이되, 안정성을 유지하고 과적합을 일어나지 않게 하는 방향으로 지속적으로 개선을 시켰습니다.
- 모델을 개선시킴에 따라 생긴 변화를 관찰하여, 모델의 성능 개선에 도움이 된 변화만 지속적으로 채택하였습니다.
(1) parameter :
- image size : 150 X 150
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : RMSprop
- lr = 1e-4
- steps_per_epoch = 20 & epochs = 20
(1) parameter :
- image size : 150 X 150
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : RMSprop
- lr = 1e-4
- steps_per_epoch = 30 & epochs = 15
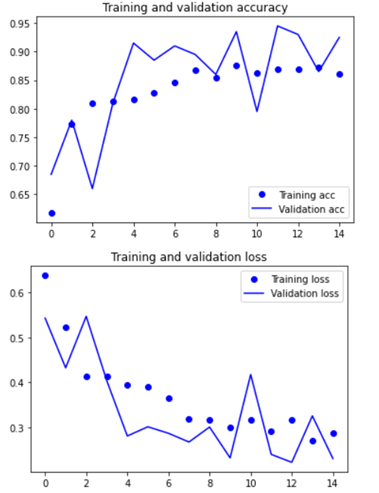
(1) parameter :
- image size : 150 X 150
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : RMSprop
- lr = 1e-4
- steps_per_epoch = 30 & epochs = 15
- Data augmentation 추가
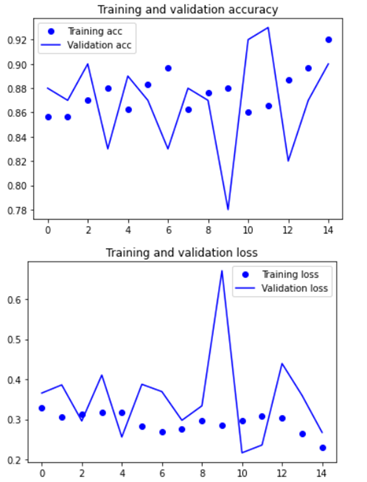
(1) parameter :
- image size : 150 X 150
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : RMSprop
- lr = 1e-5
- steps_per_epoch = 30 & epochs = 15
- Data augmentation 추가
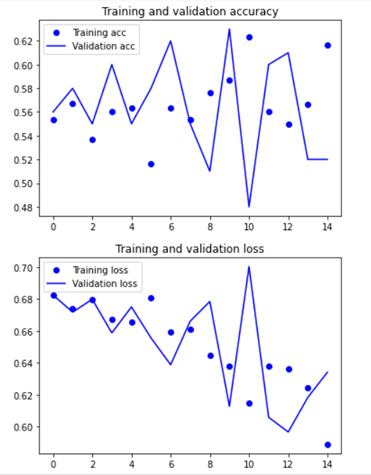
(1) parameter :
- image size : 150 X 150
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : RMSprop
- lr = 5e-5
- steps_per_epoch = 30 & epochs = 15
- Data augmentation 추가
(1) parameter :
- image size : 300 X 300
- batch_size : 20
- model composition :deeper
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(300, 300, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid')) - optimizers : RMSprop
- lr = 1e-4
- steps_per_epoch = 30 & epochs = 15
- Data augmentation 추가
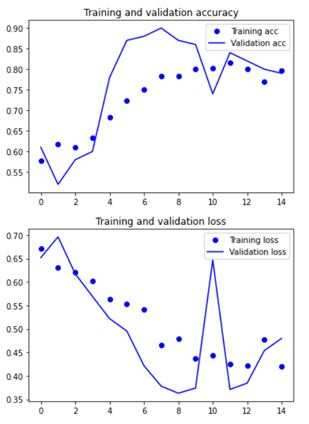
insight : lr 다시 1e-4로 & cnn모델 deeper & 이미지 사이즈 300X300 으로 증가, model2와 비교했을 때, cnn 모델을 깊게하고, 이미지 사이즈를 증가시켰을 때 증가하는 경향은 개선됐지만, 진동과 acc 측면에서 아쉬웠음.
(1) parameter :
- image size : 300 X 300
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(300, 300, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : RMSprop
- lr = 7e-5
- steps_per_epoch = 30 & epochs = 15
- Data augmentation 추가
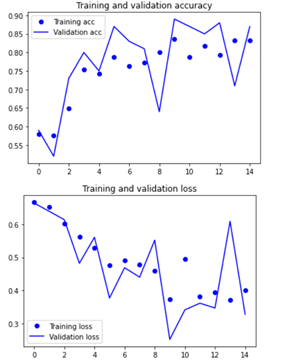
(1) parameter :
- image size : 300 X 300
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(300, 300, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : Adam
- lr = 7e-5
- steps_per_epoch = 30 & epochs = 15
- Data augmentation 추가
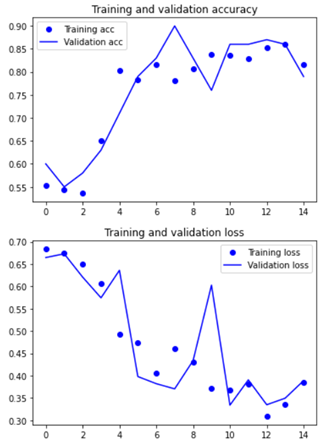
(1) parameter :
- image size : 300 X 300
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(300, 300, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : Adam
- lr = 1e-4
- steps_per_epoch = 30 & epochs = 15
- Data augmentation 추가
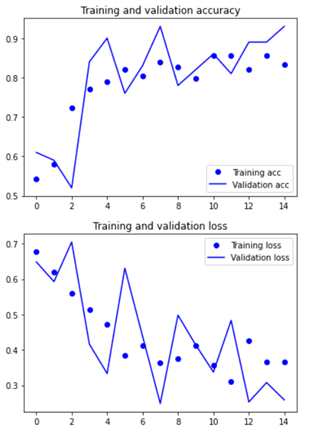
(1) parameter :
- image size : 300 X 300
- batch_size : 20
- model composition :
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(300, 300, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- optimizers : Adam
- lr = 1e-4
- steps_per_epoch = 30 & epochs = 15
- Data augmentation 제외
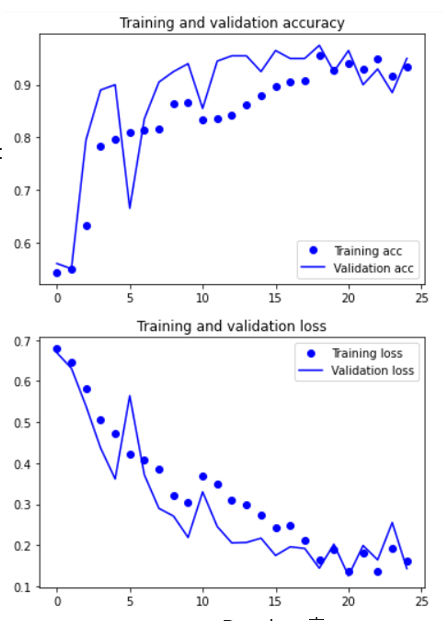
<OpenCV를 통해 개화를 판단하는 알고리즘 만들기>
import cv2
from google.colab.patches import cv2_imshow
hsvFrame = cv2.cvtColor(imageFrame, cv2.COLOR_BGR2HSV)
# Set range for red color and
# define mask
red_lower = np.array([136, 87, 111], np.uint8)
red_upper = np.array([180, 255, 255], np.uint8)
red_mask = cv2.inRange(hsvFrame, red_lower, red_upper)
# Set range for green color and
# define mask
green_lower = np.array([25, 52, 72], np.uint8)
green_upper = np.array([102, 255, 255], np.uint8)
green_mask = cv2.inRange(hsvFrame, green_lower, green_upper)
# Set range for blue color and
# define mask
blue_lower = np.array([94, 80, 2], np.uint8)
blue_upper = np.array([120, 255, 255], np.uint8)
blue_mask = cv2.inRange(hsvFrame, blue_lower, blue_upper)
kernal = np.ones((5, 5), "uint8")
# For red color
red_mask = cv2.dilate(red_mask, kernal)
res_red = cv2.bitwise_and(imageFrame, imageFrame, mask = red_mask)
# For green color
green_mask = cv2.dilate(green_mask, kernal)
res_green = cv2.bitwise_and(imageFrame, imageFrame, mask = green_mask)
# For blue color
blue_mask = cv2.dilate(blue_mask, kernal)
res_blue = cv2.bitwise_and(imageFrame, imageFrame, mask = blue_mask)
# Creating contour to track green color and red color
contours_G, hierarchy = cv2.findContours(green_mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(imageFrame, contours_G, -1, (0,255,0), 3 )
contours_R, hierarchy = cv2.findContours(red_mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(imageFrame, contours_R, -1, (0,0,255), 3 )
cv2_imshow(imageFrame)
area_G = 0
area_R = 0
for i in range(len(contours_G)):
area_G += cv2.contourArea(contours_G[i])
for i in range(len(contours_R)):
area_R += cv2.contourArea(contours_R[i])
white = (255, 255, 255)
font = cv2.FONT_HERSHEY_PLAIN
img2 = cv2.putText(imageFrame, "GREEN:" + str(round((area_G/786432)*100, 2))+"%" , (550, 900), font, 2, white, 2, cv2.LINE_AA)
img3 = cv2.putText(img2, "RED:" + str(round((area_R/786432)*100, 2))+"%" , (550, 930), font, 2, white, 2, cv2.LINE_AA)
cv2_imshow(img3)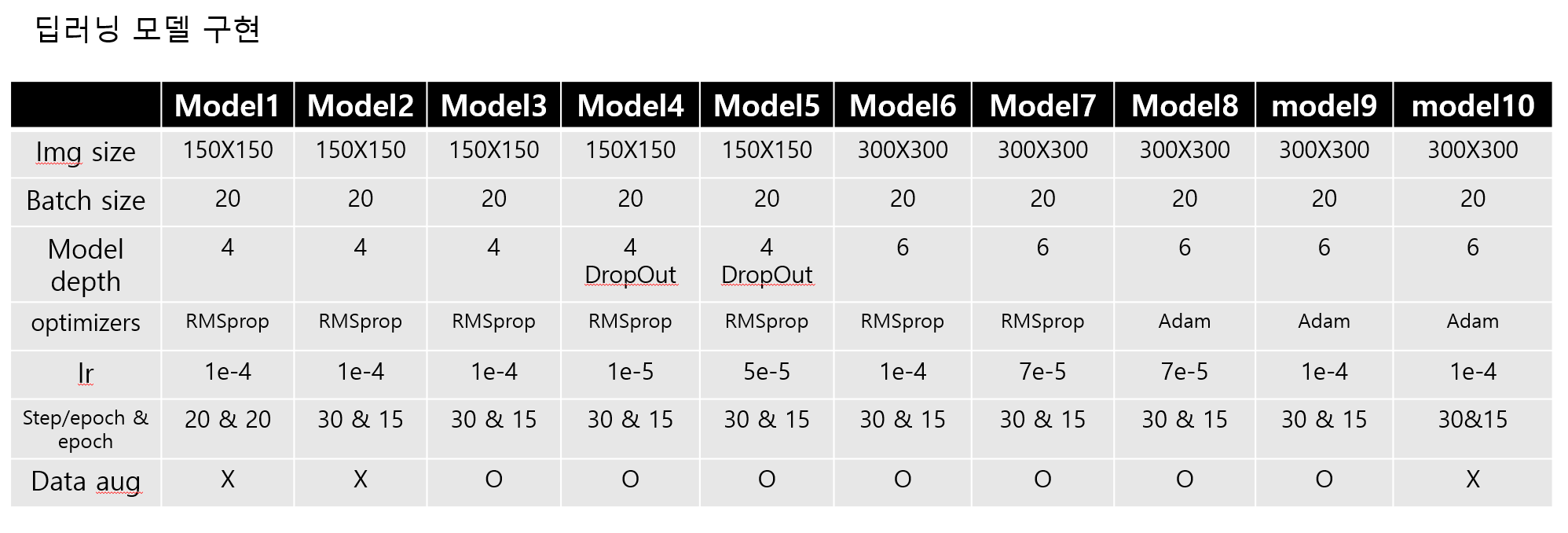
- Insight를 모델1~9까지 develop하면서 성능이 개선되었던 포인트만 반영했더니 최고의 결과가 나왔음
- 이미지 사이즈를 확대하고, 모델의 깊이를 증가 => 성능 및 안정성 개선
- optimizers를 RMSprop 에서 Adam 으로 변경 => 학습 능력 개선
- 가장 학습에 알맞았던 learning rate 1e-4로 진행
- step per epoch 와 epoch 를 각각 30 과 25 로 진행하여, 충분한 학습이 이뤄지도록 함.
- Data augmentation은 적은 데이터수에 비해 과하게 다양한 학습을 일으켜 학습 성능을 저해시켰던 경험을 반영하여 삭제하였음.
최종적으로 구현한 모델에서 과적함을 극복하고 accuracy와 val_accuracy 모두 안정적으로 증가하는 경향을 보였습니다.. 정확도 93.47%와 val acc가 95%로 모델의 오차를 안정적으로 줄이는데 성공하였습니다.

- OpenCV의 여러 라이브러리를 통해 사진을 색을 기준으로 경계선으로 나누고, 경계선으로 나뉜 부분의 넓이를 이용하여 비율을 계산한후 녹색과 비녹색의 비율을 표현함과 동시에, 이를 활용하여 개화유무를 판단할 수 있는 가능성을 제시하였습니다.
- https://goldsystem.tistory.com/822
- https://www.kaggle.com/code/mrisdal/exploring-survival-on-the-titanic/report
- https://www.kaggle.com/datasets/cf488efb70f71b0db8c5a69539ea35874787d4a4ab835126168e7af1723418d7
- http://taewan.kim/post/cnn/
- https://rubber-tree.tistory.com/entry/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-CNN-Convolutional-Neural-Network-%EC%84%A4%EB%AA%85
- https://opencv.org/
- 원영준 교수님 딥러닝 강의자료
유튜브 링크 : https://youtu.be/5BqI4m-KHgc