- Use python=3.10
- pip install packages from requirements.txt
- Set / export the parent folder of
srctoPYTHONPATH. - Update the
src_diranddata_dirofsrc.utils.filepathsaccordingly (should point to yoursrcfolder and yourdatafolder accordingly. - Set / export the OPENAI_API_KEY variable
-
Run
src.runmepython path/to/src/runme.py
-
To score the dataset (after running the
runme.pyfile to generate the output files required for scoring), runsrc.utils.scoringpython path/to/src/utils/scoring.py
-
Run
src.app.clipython path/to/src/app/cli.py record_file_name
where
record_file_nameis the filename of the record (e.g.Single_UNP/2014/page_35.pdf-3)
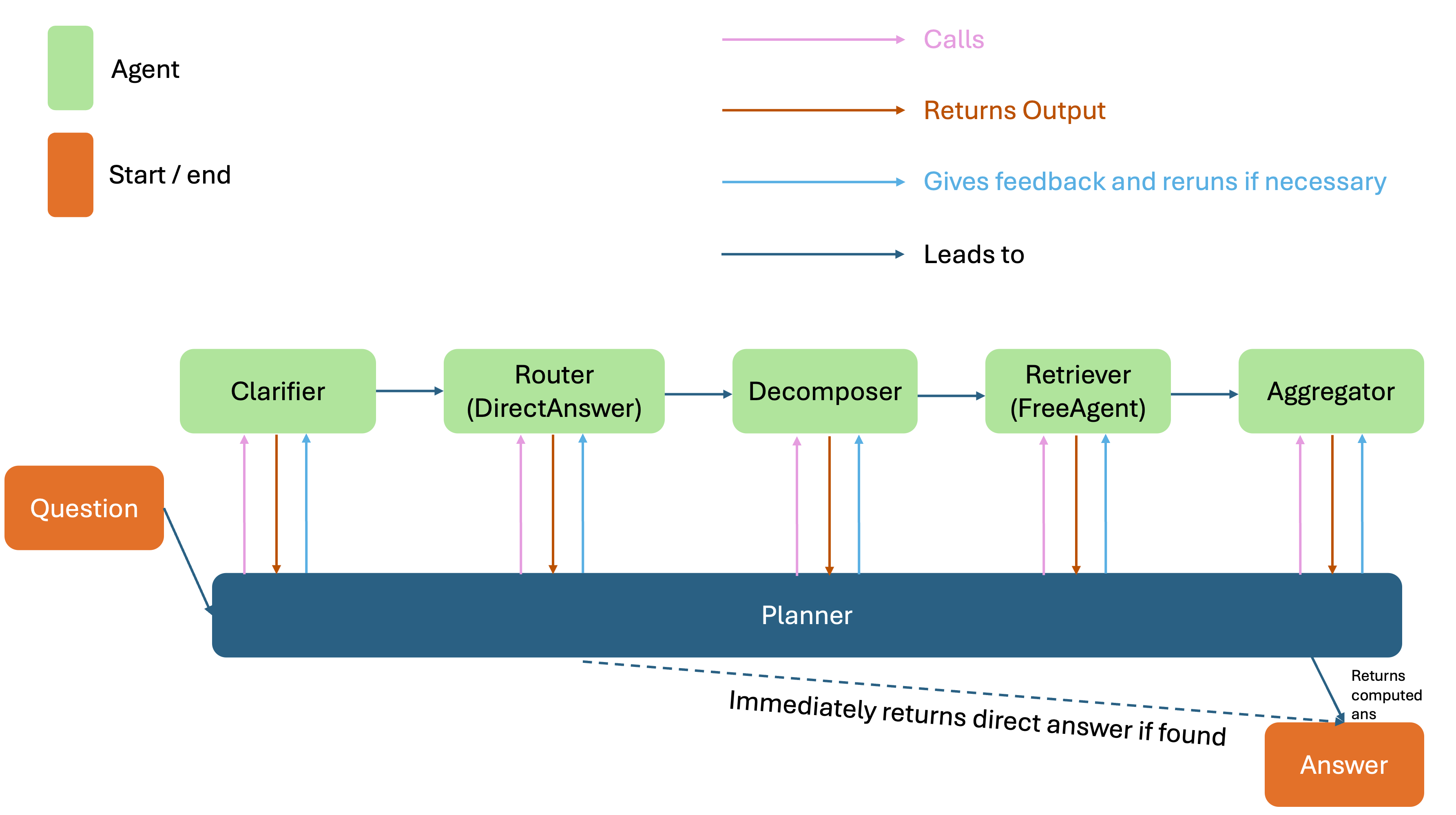
Detects ambiguity and reformulates vague user questions into precise, self-contained forms using conversation history.
Implements a “short-circuit” mechanism to directly answer questions when sufficient context is already available, reducing latency.
Breaks complex queries into subproblems and runs parallel retrieval agents to gather supporting facts.
Generates a deterministic Python function to compute the final answer, ensuring reproducibility and auditability.
A planner agent monitors outputs and injects immediate feedback for retries if needed, ending the pipeline when a direct or aggregated answer is produced.
- The first metric used is the 'correctness' of answer - be it via direct matching or tolerance-based evaluation.
- The second metric used modulates the 'Quality of Reasoning' with 'Efficiency of Reasoning'. 'Quality of Reasoning' is defined to be the number of agents used in the pipeline that had successfully completed their tasks (therefore it is a binary number of either 0 or 1). 'Efficiency of Reasoning' is defined to be the number of attempts each agent takes to complete its task. Therefore, the afore-mentioned can be formalized as such:
$$\text{SQ\_METRIC} = \frac{\sum_{i=1}^{N} q_i}{\sum_{i=1}^{N} a_i}$$
where:
-
$q_i \in {0, 1}$ is the quality indicator of agent$i$ (1 if successful, 0 otherwise). -
$a_i \in \mathbb{N}^+$ is the number of attempts made by agent$i$ . -
$N$ is the total number of agents in the pipeline.
The pipeline was run on the top 8 records of the ConvFinQA dataset to get the agent outputs, before being scored by the scorer. The scores are as follows:
| Agent/Metric | Score |
|---|---|
| ClarifierAgent_score | 0.862069 |
| DirectQAAgent_score | 0.890805 |
| DecomposerAgent_score | 0.947368 |
| FreeAgent_score | 0.645833 |
| AggregatorAgent_score | 0.312500 |
SQ_METRIC |
0.583908 |
| Correctness | 0.689655 |
- This system was developed on mac using pycharm, compatibility with Windows systems cannot be guaranteed
- If I had missed out any packages in
requirements.txt, please let me know :) - The system might get stuck in "reflection" loops, especially at the aggregation stage. If that happens, just re-run the system. An
agent_retry_limithas already been set (defaults to 5). - Each 'agent' file can be run independently, I developed it as such to test out the pipeline incrementally
- Currently, 'gpt-5-mini' is being used as the LLM for all agents. It works fairly well