This repository contains the code and data used in the paper "Towards Efficient Benchmarking of Foundation Models in Remote Sensing: A Capabilities Encoding Approach".
Foundation models constitute a significant advancement in computer vision: after a single, albeit costly, training phase, they can address a wide array of tasks. In the field of Earth observation, over 75 remote sensing vision foundation models have been developed in the past four years. However, none has consistently outperformed the others across all available downstream tasks. To facilitate their comparison, we propose a cost-effective method for predicting a model’s performance on multiple downstream tasks without the need for fine-tuning on each one. This method is based on what we call “capabilities encoding.” The utility of this novel approach is twofold: we demonstrate its potential to simplify the selection of a foundation model for a given new task, and we employ it to offer a fresh perspective on the existing literature, suggesting avenues for future research.
- Clone the repository and install the required packages:
git clone git@github.com:pierreadorni/capabilities-encoding.git
cd capabilities-encoding- create a new virtual environment and install the requirements:
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt- Set the PYTHONPATH environment variable to the root of the repository:
export PYTHONPATH=$(pwd)You will find the scripts to reproduce the results of the paper in the scripts folder.
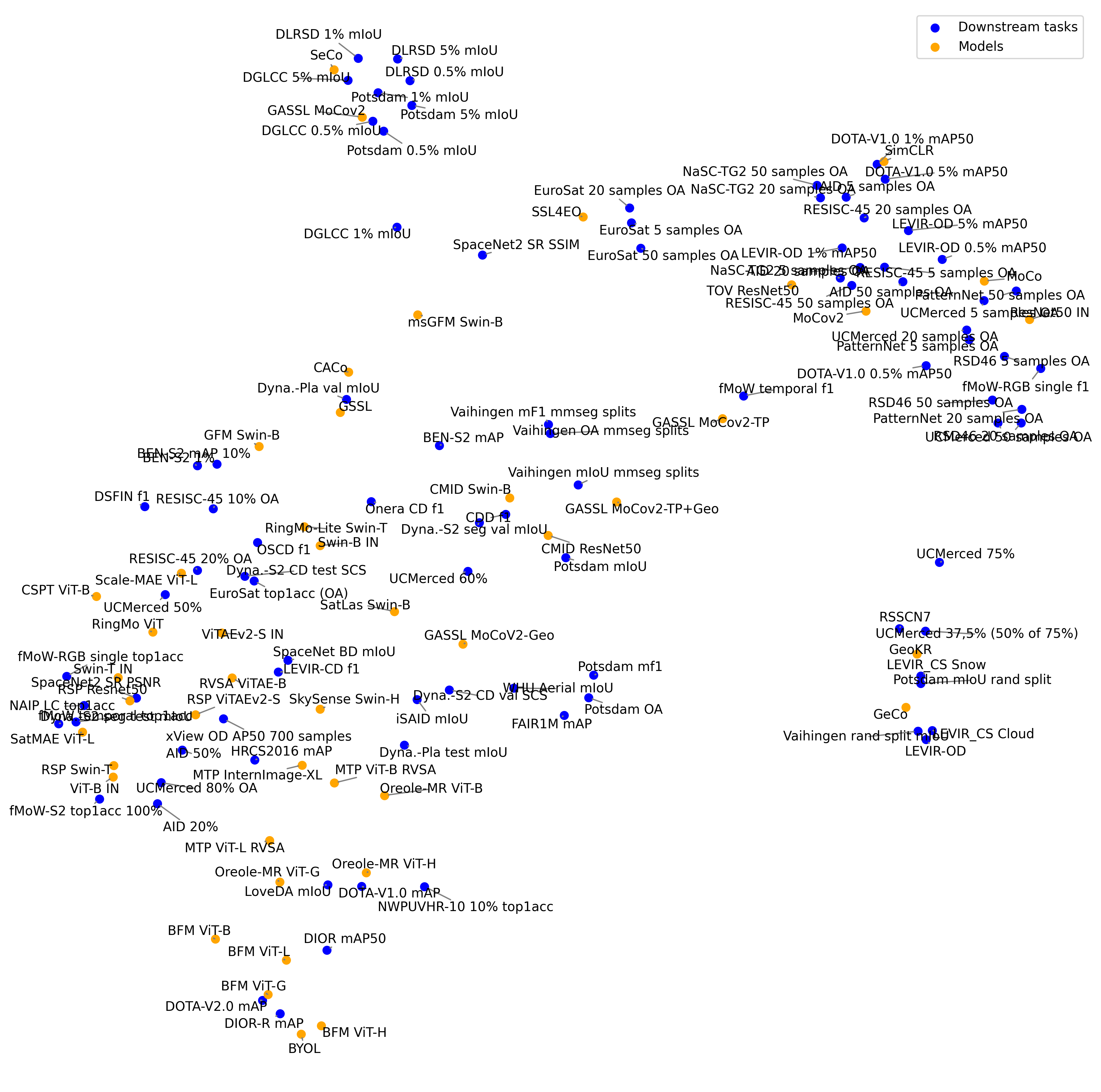
Generates the figure 3 of the paper.
Generates a heatmap of the validation error of the models on the downstream tasks. The heatmap is saved in the plots folder. This is useful to visualize possible bad data points and weaknesses of the prediction model.
Trains the latent space model. Parameters:
| Parameter | Description | Default value | Type |
|---|---|---|---|
--lr |
Learning rate | 5e-2 | float |
--n-iter |
Number of iterations | 5000 | int |
--dist |
Distance to use for the optimization | l2 | ['l2', 'cosine', 'mlp', 'minkowski', 'poincare'] |
--dims |
Number of dimensions for the embedding | 10 | int |
--no-umap |
Do not use UMAP to reduce the dimensionality of the embedding for visualization | bool (flag) | |
--val |
Number of values to mask in the ground truth for validation | 50 | int |
--normalize |
Use normalized distances instead of absolute distances. | bool (flag) | |
--cv-folds |
Number of folds for cross-validation. | 5 | int |
--init |
Initialization for the coordinates. | random | ['random', 'l2', 'cosine', 'mlp', 'minkowski', 'poincare'] |
--freeze-encoder |
Freeze the encoder (latent space coordinates) and only train the decoder (MLP). This is only relevant when using the MLP distance, and is recommended only with a non-random initialization. | bool (flag) |
Generate the latent space shown in the paper: train on the full dataset
python scripts/train.py data/data.csv --lr 0.05 --n-iter 500 --dist l2 --dims 5 --val 0 --normalize --cv-folds 1Try to predict the actual distance to best, not the relative distance to best normalized between 0 and 1:
python scripts/train.py data/data.csv --lr 0.05 --n-iter 500 --dist l2 --dims 5 --val 50 --cv-folds 50Change the dimension of the latent space:
python scripts/train.py data/data.csv --lr 0.05 --n-iter 500 --dist l2 --dims 2 --val 50 --cv-folds 50 --no-umap