
![]()
A free, open-source MCP server that gives any agent (Claude Code, Cursor, Windsurf, …) 55 production-grade tools for the full web-crawling stack: deep analysis, stealth, API discovery, session recording → runnable crawler, smart extraction. No proprietary API. No per-request fee.
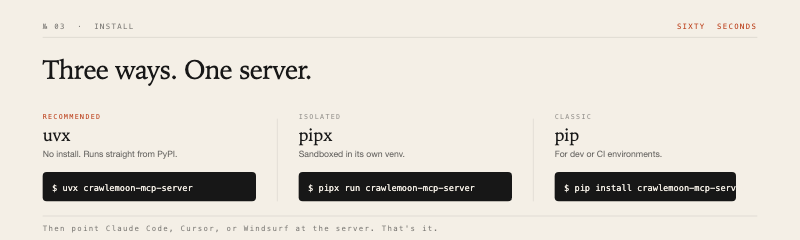
The recommended path needs no install — uvx runs straight from PyPI:
{
"mcpServers": {
"crawlemoon": {
"command": "uvx",
"args": ["crawlemoon"]
}
}
}Requires
uv. Install once:curl -LsSf https://astral.sh/uv/install.sh | sh. Or usepipx run crawlemoon/pip install crawlemooninstead.
Where to put that JSON: Cursor → Settings → MCP. Claude Code → ~/.config/claude/mcp_settings.json. Windsurf → Settings → MCP Servers.

Your agent talks to Crawlemoon over the Model Context Protocol. Crawlemoon owns a hardened browser pool, an HTTP stack with TLS fingerprinting, and a rotating proxy pool. While it fetches pages, it captures network traffic, reads scripts, and introspects schemas — so the agent gets clean structured data, not raw HTML.
A short list — see the source for the full set of 55 tools.
| Group | Tools |
|---|---|
| Deep analysis | deep_analyze, discover_apis, introspect_graphql, analyze_websocket, analyze_auth, detect_protection, detect_technology |
| Stealth | stealth_request, configure_proxies, configure_rate_limit, add_proxy, test_proxy |
| Record → crawler | record_session, stop_recording, export_recording, generate_crawler |
| Extraction | smart_extract, extract_article, extract_tables, extract_links, extract_forms, extract_metadata, convert_to_markdown |
| Page interaction | take_screenshot, fill_form, wait_and_extract, compare_pages, measure_performance, check_accessibility, get_dom_tree |
| Sessions & cache | save_session, load_session, get_cookies, get_storage, clear_cache, get_cache_stats |
| Advanced (opt-in) | execute_js, execute_cdp, deobfuscate_js, extract_from_js, solve_captcha |
smart_extract works without any API key using pattern matching. Plug in any OpenAI-compatible endpoint for higher accuracy — including FREE tiers:
# OpenRouter (free models exist)
CRAWLEMOON_LLM_PROVIDER=openrouter
CRAWLEMOON_LLM_API_KEY=sk-or-v1-xxx
CRAWLEMOON_LLM_MODEL=meta-llama/llama-3.2-3b-instruct:free
# Groq (free, very fast)
CRAWLEMOON_LLM_PROVIDER=groq
CRAWLEMOON_LLM_API_KEY=gsk_xxx
# Local Ollama (no key needed)
CRAWLEMOON_LLM_PROVIDER=ollama
CRAWLEMOON_LLM_MODEL=llama3.2Together, DeepSeek, Mistral, Fireworks, and standard OpenAI also work via CRAWLEMOON_LLM_BASE_URL.
| Variable | Default | Notes |
|---|---|---|
CRAWLEMOON_HEADLESS |
true |
Run browser without UI |
CRAWLEMOON_BROWSER |
chromium |
chromium / firefox / webkit |
CRAWLEMOON_POOL_SIZE |
5 |
Max concurrent browsers |
CRAWLEMOON_NAV_TIMEOUT |
30.0 |
Page-load timeout (s) |
CRAWLEMOON_API_KEY |
unset | If set, every tool call must include matching _api_key |
CRAWLEMOON_ALLOW_DANGEROUS_JS |
false |
Required for execute_js / execute_cdp / deobfuscate_js |
CRAWLEMOON_JS_MAX_LENGTH |
50000 |
Length cap for JS payloads |
CRAWLEMOON_JS_EXEC_TIMEOUT |
10.0 |
Per-script timeout (s) |
execute_js, execute_cdp, and deobfuscate_js are disabled by default — they execute or operate on arbitrary code in a real browser. Enable on trusted networks with CRAWLEMOON_ALLOW_DANGEROUS_JS=true. Even then, payloads are length-capped, time-bounded, and a denylist rejects eval, new Function, dynamic import(), document.write, importScripts, and WebAssembly.{compile,instantiate}. Set CRAWLEMOON_API_KEY so MCP clients must present a matching _api_key.
These are mitigations, not a sandbox: do not expose this server to untrusted clients.
git clone https://github.com/razavioo/crawlemoon.git
cd crawlemoon
make dev-install # editable install + dev/captcha/ocr extras + pre-commit
make test # pytest
make lint # ruff + mypyThis project uses Trusted Publishing (OIDC) via GitHub Actions to automate publishing releases directly to PyPI.
To release a new version:
- Bump the version number in
pyproject.toml. - Commit the change and create a git tag matching the version (e.g.
v1.1.8):git add pyproject.toml git commit -m "chore: bump version to 1.1.8" git tag v1.1.8 - Push your branch and the tag to GitHub:
git push origin main --tags
GitHub Actions will automatically run tests, build the package, and publish it securely to PyPI under the crawlemoon package space.
PRs welcome. Particularly interested in: distributed mode (Redis queue), result sinks (Postgres / S3), Prometheus metrics. See MIT License.
Made by emad.dev