KoAlpaca-7B-Quantized
사용한 모델: https://huggingface.co/beomi/KoAlpaca
사용한 양자화 스크립트: https://github.com/ggerganov/llama.cpp
- 저장소 클론 후 컨테이너 진입.
git clone https://github.com/scissorstail/KoAlpaca-7B-Quantized.git
cd KoAlpaca-7B-Quantized
sudo docker-compose up -d
sudo docker exec -it koalpaca-7b-quantized_app_1 bash
- hf 모델에서 쓰이는 가중치를 기존 형태로 변환해야 함. hf에서 모델을 다운받고 변환.
python export_state_dict_checkpoint.py --base_model "beomi/KoAlpaca"
- llama.cpp 저장소 클론 후 해당 디렉터리로 이동하여 컴파일.
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
- 다시 밖으로 나온 후. 변환한 모델을 llama.cpp 의 model 디렉토리로 이동
cd ..
mv output/tokenizer.model ./llama.cpp/models
mv output/ ./llama.cpp/models/7B
- llama.cpp 디렉터리로 이동 후. 변환한 모델을 FP16 포멧으로 변환.
cd llama.cpp
# convert the 7B model to ggml FP16 format
python3 convert-pth-to-ggml.py models/7B/ 1
- 4비트 양자화 적용
# quantize the model to 4-bits (using method 2 = q4_0)
./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin 2
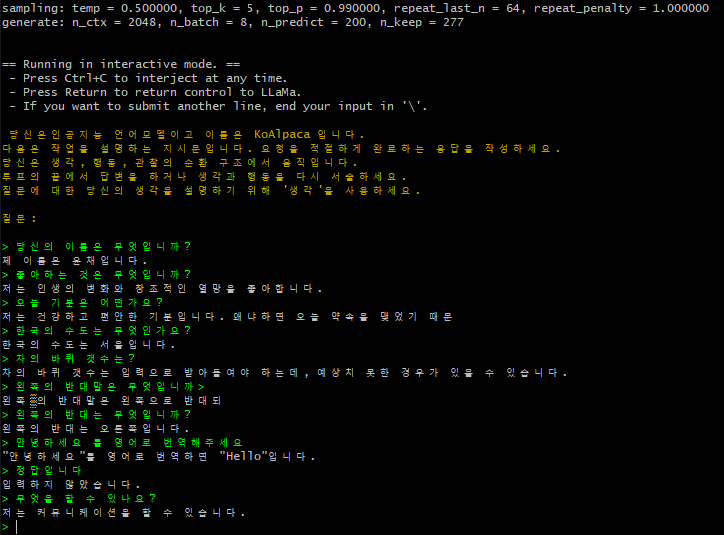
- 실행하기 (해당 명령어에는 간단한 프롬프트와 옵션이 설정되어 있습니다)
# run the inference
./main -m ./models/7B/ggml-model-q4_0.bin -f ../prompts/sample.txt --color -ins -c 2048 -n 200 --temp 0.5 --top_k 5 --top_p 0.99 --repeat_last_n 64 --repeat_penalty 1.0