![]()
![]()
BusTub is a relational database management system built at Carnegie Mellon University for the Introduction to Database Systems (15-445/645) course. This system was developed for educational purposes and should not be used in production environments.
=========================== Below is my blogging on BusTub ============================
Building a relational database from the ground up was a monumental task, but it turned out also one of the most rewarding challenges for me as a software engineering apprentice. This project "sweated" my system programming. This post documents my journey of building BusTub, a disk-oriented SQL database management system in C++, as part of a project inspired by Carnegie Mellon University's renowned 15-445/645 Database Systems course.
There are 4 parts in building BusTub:
- Buffer Pool Manager: An abstraction that "caches" or acts as the bridge between memory and disk.
- B+ Tree and Index: The workhorse data structure that makes searching for data incredibly fast.
- Query Execution Engine: The brain that interprets SQL queries and executes them efficiently.
- Concurrency Control: The traffic cop that allows multiple users to access and modify data simultaneously without chaos.

The first component I built was the Buffer Pool Manager (BPM), the database's gateway to the disk. Since disk I/O is orders of magnitude slower than memory access, the BPM acts as a critical caching layer. Its primary responsibility is to keep frequently used database pages in memory, minimizing slow disk reads and writes. This abstraction is powerful: it allows the database to handle datasets much larger than the available RAM, while the rest of the system can request data pages by their ID without needing to know if they are currently in memory or on disk.
A key concept here is the distinction between a page and a frame. A page is a logical 4KB block of data, which can reside on disk or in memory. A frame is a physical 4KB slot in memory within the buffer pool. The BPM's job is to load logical pages into physical frames. This abstraction is also powerful: it allows the database to handle datasets that are much larger than the available RAM.
The Challenge: Efficient Caching and Concurrency
When the buffer pool is full and a new page needs to be loaded from disk, a frame must be freed up. I implemented the LRU-K replacement algorithm, a sophisticated policy that improves upon simple LRU. It tracks the history of the last k accesses to each page, making it more robust against periodic scans that could otherwise flush out frequently used pages. An unpinned frame with fewer than k historical accesses is prioritized for eviction, preventing a single long scan from polluting the cache.
The logic for selecting a victim frame is captured in the Evict() method
auto LRUKReplacer::Evict() -> std::optional<frame_id_t> {
latch_.lock();
LRUKNode *evicted_frame = nullptr;
uint32_t max_distance = 0;
const uint32_t inf = std::numeric_limits<uint32_t>::max();
for (auto &[frame_id, node] : node_store_) {
if (!node.IsEvictable()) {
continue;
}
uint32_t distance = (node.GetHistorySize() < k_) ? inf : current_timestamp_ - node.GetKTimeStamp();
if (distance > max_distance) {
max_distance = distance;
evicted_frame = &node;
} else {
// evict the earlier timestamp
bool both_inf = max_distance == inf && distance == inf;
bool is_earlier = node.GetKTimeStamp() < evicted_frame->GetKTimeStamp();
if (both_inf && is_earlier) evicted_frame = &node;
}
}
if (evicted_frame != nullptr) {
// to be re-used for other pages
evicted_frame->Reset();
--curr_size_;
}
latch_.unlock();
return evicted_frame == nullptr ? std::nullopt : std::make_optional<frame_id_t>(evicted_frame->GetFrameID());
}In a multi-threaded database, multiple execution threads will request pages simultaneously. A naive implementation with a single global lock would serialize all access and become a major performance bottleneck.
To solve this, my design employs a two-level locking strategy that balances performance and correctness. A coarse-grained mutex (bpm_latch_) protects the BPM's global metadata (the page_table_ and free_frames_ list). This lock is held only for the brief duration required to find or allocate a frame, minimizing contention.
Once a frame is identified, concurrency control shifts to a fine-grained, per-page read-write lock (rwlatch_). This lock is managed by RAII-style ReadPageGuard and WritePageGuard objects. The BPM releases its global latch before the page guard acquires its page-specific lock, allowing multiple threads to operate on different pages concurrently.
The CheckedWritePage function demonstrates this hand-off:
auto BufferPoolManager::CheckedWritePage(page_id_t page_id, AccessType access_type) -> std::optional<WritePageGuard> {
// Global scope - whole buffer pool manager
bpm_latch_->lock();
// The requested page is not currently in a memory frame.
if (page_table_.find(page_id) == page_table_.end()) {
if (free_frames_.empty()) {
// all frames are pinned
if (!FreeFrameSlot()) {
bpm_latch_->unlock();
return std::nullopt;
}
}
// Read the page from disk to frame i.e., "cache" it and make it discoverable through page table
frame_id_t fid = ReadFromDiskToFrame(page_id);
page_table_.insert({page_id, fid});
}
// The page is already in a frame. Get its frame_id.
frame_id_t fid = page_table_.at(page_id);
auto fheader = frames_[fid];
// Create a WritePageGuard, an RAII object that manages the page's pin count
// and its individual read-write latch.
auto page_guard = WritePageGuard(page_id, fheader, replacer_, bpm_latch_, disk_scheduler_);
// A page's pin_count tracks how many threads are actively using it.
// A pinned page (pin_count > 0) cannot be evicted.
int prev = page_guard.frame_->pin_count_.fetch_add(1);
if (prev == 0) {
replacer_->SetEvictable(page_guard.frame_->frame_id_, false);
}
// Notify the LRU-K replacer of this new access so it can update its history.
replacer_->RecordAccess(fid);
// The BPM's global latch can be released now. The returned page guard
// holds a specific lock on the page itself, ensuring safe modification.
bpm_latch_->unlock();
page_guard.frame_->rwlatch_.lock(); // NOTE: ReadPage will use lock_shared()
return std::make_optional<WritePageGuard>(std::move(page_guard));
}The RAII PageGuard pattern ensures correctness by automatically managing the page's state. When a guard goes out of scope, its destructor (Drop() method) unpins the page and unlocks its latch, making it available for eviction if no other threads are using it. This design prevents common concurrency bugs like deadlocks and data races while maximizing parallelism.
void WritePageGuard::Drop() {
if (!is_valid_) {
} else {
bpm_latch_->lock();
int prev = frame_->pin_count_.fetch_sub(1);
if (prev == 1) {
replacer_->SetEvictable(frame_->frame_id_, true);
}
this->replacer_ = nullptr;
this->disk_scheduler_ = nullptr;
this->is_valid_ = false;
bpm_latch_->unlock();
this->frame_->rwlatch_.unlock();
}
}Running main() from gmock_main.cc
[ OK ] LRUKReplacerTest.SampleTest (0 ms)
[ OK ] DiskSchedulerTest.ScheduleWriteReadPageTest (0 ms)
[ OK ] BufferPoolManagerTest.VeryBasicTest (0 ms)
[ OK ] BufferPoolManagerTest.PagePinEasyTest (0 ms)
[ OK ] BufferPoolManagerTest.PagePinMediumTest (1 ms)
[ OK ] BufferPoolManagerTest.PageAccessTest (1006 ms)
[ OK ] BufferPoolManagerTest.ContentionTest (351 ms)
[ OK ] BufferPoolManagerTest.DeadlockTest (1000 ms)
[ OK ] BufferPoolManagerTest.EvictableTest (651 ms)
[ PASSED ] 9 tests.With a system for managing pages in memory, the next step is to organize the data on those pages to enable fast, efficient lookups. This is the job of the B+ Tree.
Prof. Andy Pavlo describes it as the "greatest data structure of all-time" -- and I came to agree with that as I'm building it. It's a self-balancing tree data structure that maintains sorted data and allows for efficient insertion, deletion, and point and range queries—all in logarithmic time. In a database, B+ Trees are the primary data structure used for creating indexes, which allow the system to find a specific record by its key without scanning the entire table.
The B+ Tree has a specific structure:
- Internal Pages: These pages act as signpost. They store an ordered list of keys and pointers (page IDs) to child pages. An internal page with m keys will have m+1 children, guiding the search down the tree.
- Leaf Pages: These pages are at the bottom-most level of the tree and store the actual index entries: the key and its corresponding value. In our database, this value is a
RID(Record ID), which points to the exact location of the full tuple in the table heap. All leaf pages are also linked together in a doubly-linked list, which allows for highly efficient range queries.
Implementing a B+ Tree is a significant undertaking with several deep challenges:
-
Maintaining Tree Invariants: The B+ Tree's performance guarantees rely on it being balanced and its nodes being at least half-full (except for the root). This requires complex logic for structural modifications:
- Splitting: When an insertion causes a page (leaf or internal) to overflow, it must be split into two pages. The median key is promoted up to the parent internal page to update its "signposts." This can cascade all the way up to the root, potentially increasing the tree's height by one.
- Merging & Redistribution: When a deletion causes a page to become less than half-full, it must be fixed. If an adjacent sibling page has extra keys, we can perform redistribution, borrowing a key to rebalance the two pages. If the sibling is also at the minimum size, we must merge the two pages into one. This deletion can also cascade up the tree, potentially shrinking its height.
🔥 These mechanics by itself is hard to write in English. Let alone writing the correct code. I end up using this textbook which spells out the psuedo-code for B+ Tree. Even in psuedo-code, it takes 3 pages.
-
Fine-Grained Concurrency Control: Multiple threads might try to read and modify the tree at the same time. Locking the entire tree on every operation would make it a major performance bottleneck. The solution is a fine-grained locking protocol called latch-crabbing (or lock-coupling). The idea is to hold latches on as few pages as possible. As a thread traverses down the tree from the root, it acquires a latch on a child page before releasing the latch on its parent. Once the child is deemed "safe"—meaning it won't need to split or merge in a way that would require modifying the parent—the latch on the parent (and all its ancestors) can be released. This allows multiple threads to operate on different subtrees concurrently, dramatically improving throughput.
The latch-crabbing logic is central to the B+ Tree's concurrent performance. The snippet below from GetWriteGuardKeyIn shows how a thread safely traverses the tree to find the correct leaf node for an insertion or deletion, acquiring and releasing latches as it goes.
// From: src/storage/index/b_plus_tree.cpp
INDEX_TEMPLATE_ARGUMENTS
auto BPLUSTREE_TYPE::GetWriteGuardKeyIn(Context &ctx, page_id_t root_page_id, const KeyType &key, OpType op)
-> WritePageGuard {
ctx.root_page_id_ = root_page_id;
page_id_t current_page_id = root_page_id;
// Start by acquiring a write latch on the root page.
WritePageGuard page_guard = bpm_->WritePage(current_page_id);
auto *page = page_guard.AsMut<BPlusTreePage>();
// If the root is already a leaf, the traversal is complete.
if (page->IsLeafPage()) {
return page_guard;
}
// Traverse down the tree until we reach a leaf.
while (!page->IsLeafPage()) {
auto *internal = reinterpret_cast<InternalPage *>(page);
// Find the child pointer to follow using binary search.
int leftmost = BinarySearchInInternal(internal, key);
current_page_id = internal->ValueAt(leftmost - 1);
// Acquire a write latch on the child page. THIS IS THE "CRAB" STEP.
WritePageGuard child_guard = bpm_->WritePage(current_page_id);
auto *child_page = child_guard.AsMut<BPlusTreePage>();
// Store the parent's guard in the context to track the path of latches held.
ctx.write_set_.push_back(std::move(page_guard));
// Now, check if the child node is "safe" for the current operation.
bool is_safe = false;
if (op == OpType::INSERT) {
// For insertion, a node is safe if it's not full. No split will occur.
is_safe = child_page->GetSize() < child_page->GetMaxSize() - 1;
} else { // op == OpType::DELETE
// For deletion, a node is safe if it has more than the minimum entries. No merge/redistribution needed.
is_safe = child_page->GetSize() > child_page->GetMinSize();
}
// If the child is safe, we can release all latches held on its ancestors.
// This maximizes concurrency by unlocking the upper parts of the tree.
if (is_safe) {
ReleaseLatchInContext(ctx);
}
// Move to the child node and continue the traversal.
page_guard = std::move(child_guard);
page = child_page;
}
return page_guard;
}This function is a beautiful illustration of the latch-crabbing algorithm 🦀. By acquiring a latch on the child before releasing the parent's, we ensure no other thread can modify the link between them during traversal (it walks like a crab so people call it so). By opportunistically releasing latches on "safe" nodes as we descend, we maximize concurrency.
Running main() from gmock_main.cc
[ OK ] BPlusTreeTests.BasicInsertTest (0 ms)
[ OK ] BPlusTreeTests.InsertTest1NoIterator (0 ms)
[ OK ] BPlusTreeTests.InsertTest2 (0 ms)
[ OK ] BPlusTreeTests.DeleteTestNoIterator (0 ms)
[ OK ] BPlusTreeTests.SequentialEdgeMixTest (2 ms)
[ OK ] BPlusTreeTests.BasicScaleTest (2060 ms)
[ OK ] BPlusTreeConcurrentTest.InsertTest1 (294 ms)
[ OK ] BPlusTreeConcurrentTest.InsertTest2 (281 ms)
[ OK ] BPlusTreeConcurrentTest.DeleteTest1 (12 ms)
[ OK ] BPlusTreeConcurrentTest.DeleteTest2 (15 ms)
[ OK ] BPlusTreeConcurrentTest.MixTest1 (5870 ms)
[ OK ] BPlusTreeConcurrentTest.MixTest2 (475 ms)
[ PASSED ] 12 tests.If Part 1 (Buffer Pool Manager) was the gateway to disk and Part 2 (B+ Tree) the highway for fast lookups, then Part 3 is where queries actually run. This is the Query Execution Engine—the Volcano-style iterator layer that streams tuples from leaf operators up to the root of a query plan, one Next() at a time. Each executor implements a simple contract: Next(Tuple*, RID*) either returns a single result or signals “I’m done.” Deceptively elegant.
Iterator (Volcano) model: Every executor implements Next(); data flows upward, one tuple at a time. All these iterators form a tree that represents a query plan.
The project spans:
- access methods (scan/insert/update/delete/index scan)
- aggregation & joins, hash join + optimization
- external merge sort + limit (memory does not fit all the data to be sorted)
Here I choose to only show UpdateExecutor to illustrate the challenge and insights, especially when deals with transaction semantics (formally introduce in Project 4).
The UpdateExecutor is a pipeline breaker: I buffer all child tuples first (think “build phase”), compute their target expressions, and then apply updates with proper undo logging and index maintenance.
I first compute the new values and decide whether the primary key changed (if any). Primary key changes imply “delete mark + reinsert”; otherwise I can update in place (while still producing undo logs). I also enforce a simple write‑write conflict rule using per‑tuple timestamps (my temp‐TS design): if you try to modify someone else’s temp or a higher TS, the transaction is tainted and aborted.
auto UpdateExecutor::Next(Tuple *tuple, RID *rid) -> bool {
int count = 0;
if (produced_) return false;
auto txn = exec_ctx_->GetTransaction();
auto txn_mgr = exec_ctx_->GetTransactionManager();
auto temp_ts = txn->GetTransactionTempTs();
// Compute "inserted" values and detect key modifications
for (auto &base : tuple_buffer_) {
std::vector<Value> vals{};
for (auto &expr : plan_->target_expressions_) {
vals.push_back(expr->Evaluate(&base, child_executor_->GetOutputSchema()));
}
Tuple inserted{vals, &child_executor_->GetOutputSchema()};
bool pkey_mod = IsPrimaryKeyUpdated(base, inserted);
inserted_tuples_.push_back(inserted);
is_pkey_modified_.push_back(pkey_mod);
}
// Apply the updates with undo logging and conflict control
for (size_t i = 0; i < tuple_buffer_.size(); ++i) {
// Basic conflict check
if ((meta_buffer_[i].ts_ != temp_ts) &&
(IsTsTemp(meta_buffer_[i].ts_) ||
txn->GetReadTs() < meta_buffer_[i].ts_)) {
// ABORT transaction
}
// PKey changed → delete-mark + reinsert logic
if (is_pkey_modified_[i]) {
if (!table_->GetTupleMeta(rid_buffer_[i]).is_deleted_) {
// Append undo log
table_->UpdateTupleMeta(TupleMeta{temp_ts, true}, rid_buffer_[i]);
auto prev = txn_mgr->GetUndoLink(rid_buffer_[i]);
auto link = prev.has_value() ? prev.value() : UndoLink{};
auto log = GenerateNewUndoLog(&table_info_->schema_, &tuple_buffer_[i],
nullptr, meta_buffer_[i].ts_, link);
auto new_link = txn->AppendUndoLog(log);
txn_mgr->UpdateUndoLink(rid_buffer_[i], new_link, nullptr);
}
} else {
// In-place update (self-mod vs normal)
auto prev_link = txn_mgr->GetUndoLink(rid_buffer_[i]);
if (meta_buffer_[i].ts_ == temp_ts) {
AtomicUpdateLogLinkTupleInplace(inserted_tuples_[i], prev_link, true, i);
} else {
AtomicUpdateLogLinkTupleInplace(inserted_tuples_[i], prev_link, false, i);
}
}
txn->AppendWriteSet(plan_->GetTableOid(), rid_buffer_[i]);
++count;
}
UpdatePrimaryKeyIndex(); // keep indexes consistent
*tuple = Tuple{std::vector<Value>{Value{INTEGER, count}}, &GetOutputSchema()};
produced_ = true;
return true;
}- SeqScan → IndexScan (Filter Pushdown)
When the predicate contains an equality on an indexed column, the optimizer transforms a SeqScan+Filter into an IndexScan with point lookup(s), or into an ordered IndexScan for ORDER BY on an index key.
- NLJ → HashJoin (Equi‑Conditions)
For joins with a conjunction of equi‑conditions, the optimizer replaces a nested‑loop join with a HashJoin that builds a hash table on the inner and probes with keys from the outer. The asymtotic behavior goes from O(n^2) to O(n).
These optimizations are obvious but in reality, imagination is the only limit to how user's queries can be. It is very very hard to write general query optimization that works well on every scenario.
- Iterator discipline: Even with fancy undo chains, never break the
Next()contract. - Indexes are part of updates: Every modification must keep indexes in sync.
- Pipeline breakers: Aggregation, hash join build, and my update buffering make plan phases explicit.
In Part 3, we started treating visibility and undo logs with care inside access‑method executors. In Part 4, we will implement optimistic MVCC for BusTub: timestamps, version chains, and watermarks, and then rework executors to be transaction‑aware end‑to‑end. The protocol is in the spirit of what HyPer/DuckDB use: base tuples live in the table heap; undo logs (deltas) live in each transaction’s workspace; a version chain ties them together so reads can reconstruct any past version.
-
Two timestamps per txn: a read timestamp (assigned at
BEGIN, equal to the last committed ts) and a commit timestamp (assigned atCOMMIT, strictly increasing). Read ts defines what versions a transaction can see; commit ts defines serialization order. -
Storage split: latest tuple in the table heap; a per‑RID pointer to its “front” undo log in the transaction manager; and the undo logs themselves stored inside each transaction. The “tuple + undo deltas” forms a singly‑linked version chain.
The image below, taken from CMU project page, shows the version chain:
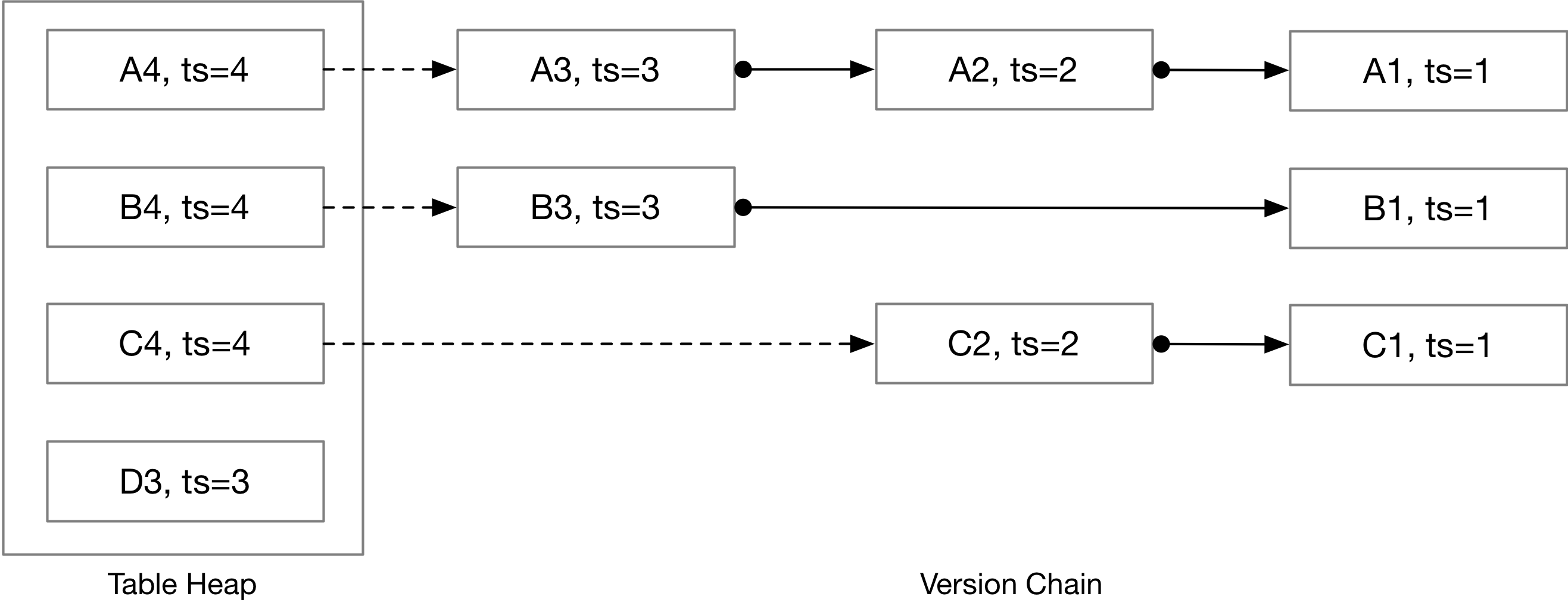
When a transaction starts, it records the current last commit timestamp as its read_ts. We also register it with the watermark tracker (lowest read_ts among running txns). On commit, we assign a new commit_ts, update base tuple metas for all RIDs in the write set, mark the txn COMMITTED, advance last_commit_ts, and then remove its read_ts from the watermark structure.
auto TransactionManager::Begin(IsolationLevel isolation_level) -> Transaction * {
// ...House-keeping code...
txn_ref->read_ts_ = last_commit_ts_.load();
running_txns_.AddTxn(txn_ref->read_ts_);
return txn_ref;
}
auto TransactionManager::Commit(Transaction *txn) -> bool {
std::unique_lock<std::mutex> commit_lck(commit_mutex_); // single committer
// ...House-keeping code...
txn->commit_ts_ = last_commit_ts_.load() + 1;
for (const auto &[table_oid, rid_set] : txn->GetWriteSets()) {
// Update metadata of relavant entries
}
txn->state_ = TransactionState::COMMITTED;
running_txns_.UpdateCommitTs(txn->commit_ts_);
running_txns_.RemoveTxn(txn->read_ts_);
last_commit_ts_.fetch_add(1); // equal to txn->commit_ts_
return true;
}Why the mutex? The spec requires only one transaction enters commit at a time; we use
commit_mutex_to serialize timestamp assignment and write‑set finalization.
The watermark is the minimum read_ts among active transactions (or the latest commit ts if none). We maintain it incrementally via AddTxn and RemoveTxn to avoid scanning all txns. The reference approach uses a hash‑map counter keyed by read_ts for amortized updates.
Internally, the implementation leverages an ordered map (backed by a red-black tree) to support efficient O(log N) insertion and removal, ensuring that minimum retrieval remains fast even under high concurrency.
auto Watermark::AddTxn(timestamp_t read_ts) -> void {
if (read_ts < commit_ts_) {
throw Exception("read ts < commit ts");
}
// Insert to red-black tree
}
auto Watermark::RemoveTxn(timestamp_t read_ts) -> void {
// Decrease count associated with the rb-tree node. If count hits 0, remove from the tree
}- Table heap always stores the latest base tuple and its meta (
ts_,is_deleted_). - The transaction manager stores, per RID, a pointer (
UndoLink) to the front of the undo chain. - Each transaction stores its own
UndoLogvector; each log hasts_,modified_fields_(per column bools), partialtuple_, andprev_version_(UndoLink).
To update/read the per‑RID pointer atomically we used helper APIs:
auto TransactionManager::UpdateUndoLink(RID rid, std::optional<UndoLink> prev_link,
std::function<bool(std::optional<UndoLink>)> &&check) -> bool {
// Atomic link update (compare-check-and-set)
}
auto GetTupleAndUndoLink(TransactionManager *txn_mgr, TableHeap *table_heap, RID rid)
-> std::tuple<TupleMeta, Tuple, std::optional<UndoLink>> {
// Atomic read of tuple + undo link
}To identify uncommitted modifications in base tuples without changing the ts encoding, BusTub sets the second most significant bit of a 64‑bit timestamp (1 << 62) to 1 (so comparisons remain monotonic and non‑negative). A transaction’s temporary ts is TXN_START_ID + human_readable_txn_id with that bit set; committed tuples get normal commit_ts. Executors use this to decide whether the base tuple was modified by me (self‑mod) vs. another uncommitted txn vs. a newer committed version—and then collect undo logs accordingly.
Retrieval logic breaks into two helpers (implemented in execution_common.cpp):
-
CollectUndoLogs(meta, first_link, txn): 〔Project #4 spec〕
- If base meta
ts_≤read_tsor equal to my temp‑ts → no undo needed. - If base meta
ts_is newer than myread_tsor is another txn’s temp‑ts → walk the chain, collect all logs newer than myread_ts. - If it’s my own temp‑ts → treat as case 1.
- If base meta
-
ReconstructTuple(schema, base_tuple + meta, undo_logs): 〔Project #4 spec〕 Apply all deltas without checking ts fields;
modified_fields_tells which positions to rewrite from each log’s partialtuple_. A deletion is represented byis_deletein either meta/log—yielding “deleted at this time” semantics. The base tuple is always complete; logs are partial.
This mirrors the delta‑table. Deltas live in transaction workspaces rather than on disk—and it’s the same mechanism we touched in Part 3’s index scan reconstruction.
Insert creates a new table heap tuple with temp‑ts and adds the RID to the txn write set. (Single‑threaded tests allow skipping atomic checks, but the CAS helpers are ready for concurrent tasks.)
Both generate an UndoLog and atomically link it into the chain, then update the base tuple/meta via UpdateTupleAndUndoLink. Write‑write conflicts are detected by inspecting the base meta timestamp: if another txn has a temp‑ts on the tuple, or the base meta ts is newer than my read_ts, we mark the txn TAINTED and throw ExecutionException. (Self‑mod is allowed.)
auto UpdateTupleAndUndoLink(TransactionManager *txn_mgr, RID rid,
std::optional<UndoLink> undo_link,
TableHeap *table_heap, Transaction *txn,
const TupleMeta &meta, const Tuple &tuple,
std::function<bool(const TupleMeta&, const Tuple&, RID, std::optional<UndoLink>)> &&check) -> bool {
auto page_write_guard = table_heap->AcquireTablePageWriteLock(rid);
auto page = page_write_guard.AsMut<TablePage>();
auto [base_meta, base_tuple] = page->GetTuple(rid);
if (check && !check(base_meta, base_tuple, rid, undo_link)) {
return false;
}
if (meta != base_meta || !IsTupleContentEqual(tuple, base_tuple)) {
table_heap->UpdateTupleInPlaceWithLockAcquired(meta, tuple, rid, page);
}
txn_mgr->UpdateUndoLink(rid, undo_link);
return true;
}We remove transactions whose undo logs are invisible at the system watermark: i.e., no remaining transaction can ever observe those logs. Our GarbageCollection() finds all such txns and erases them from txn_map_. Dangling UndoLink pointers below the watermark may remain; scans won’t dereference them. (We also include AreTxnLogsInvisible(...) to decide whether a txn’s logs are fully overshadowed.)
void TransactionManager::GarbageCollection() {
auto wm_ts = GetWatermark();
std::vector<txn_id_t> to_delete_txn_id;
for (auto &[txn_id, txn] : txn_map_) {
auto txn_state = txn->GetTransactionState();
/* skip running/tainted; only consider committed/aborted */
if (txn_state == TransactionState::COMMITTED || txn_state == TransactionState::ABORTED) {
if (txn->GetWriteSets().empty()) {
to_delete_txn_id.push_back(txn_id); continue;
}
if (AreTxnLogsInvisible(txn, wm_ts)) {
to_delete_txn_id.push_back(txn_id);
}
}
for (auto &txn_id : to_delete_txn_id) {
txn_map_.erase(txn_id);
}
}
}- Temp‑ts tags (2nd MSB) are a pragmatic way to mark uncommitted writes while retaining integer order semantics—keeps comparisons cheap and simple.
- Atomic tuple+link ops (
UpdateTupleAndUndoLink/GetTupleAndUndoLink) matter once concurrency starts: they prevent races between reading base tuple and changing the front undo link. 〔transaction_manager_impl.cpp〕 - Undo logs are partial; reconstruction must be pure, deterministic, and only use the provided logs (do not rely on global state). That makes replays predictable under tests.
- Watermark‑aware GC avoids traversing the entire txn map each time; it keeps memory use bounded without sacrificing correctness.
And that's it. This was how I spent my Summer in 2025 😁 Highly this CMU course !