


![]()
Multiple AI reviewers independently evaluate your code, plans, or docs — then debate each other's findings. A judge renders the final verdict. You get a structured report with consensus, disagreements, and prioritized action items.
A Claude Code plugin that orchestrates multi-agent adversarial review panels backed by 9 research papers on multi-agent debate.
Packaged as a Claude Code plugin (containing the
agent-review-panelskill). Install once via marketplace; it activates automatically on slash command or natural-language request. Requires Claude Code — the CLI, an IDE extension, or the Code tab inside the Claude Desktop app. Does not work with the regular claude.ai web chat or Claude API direct (details below).


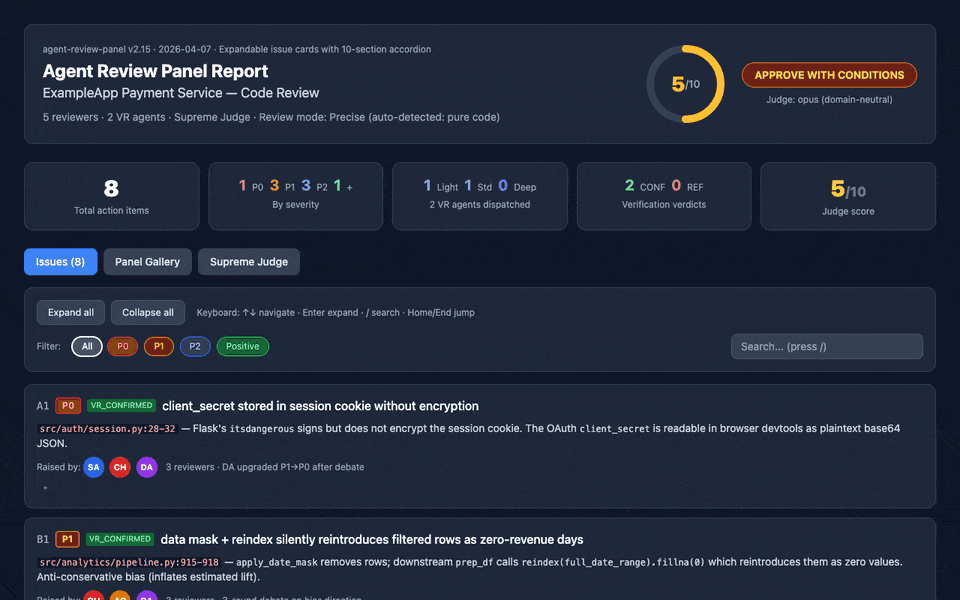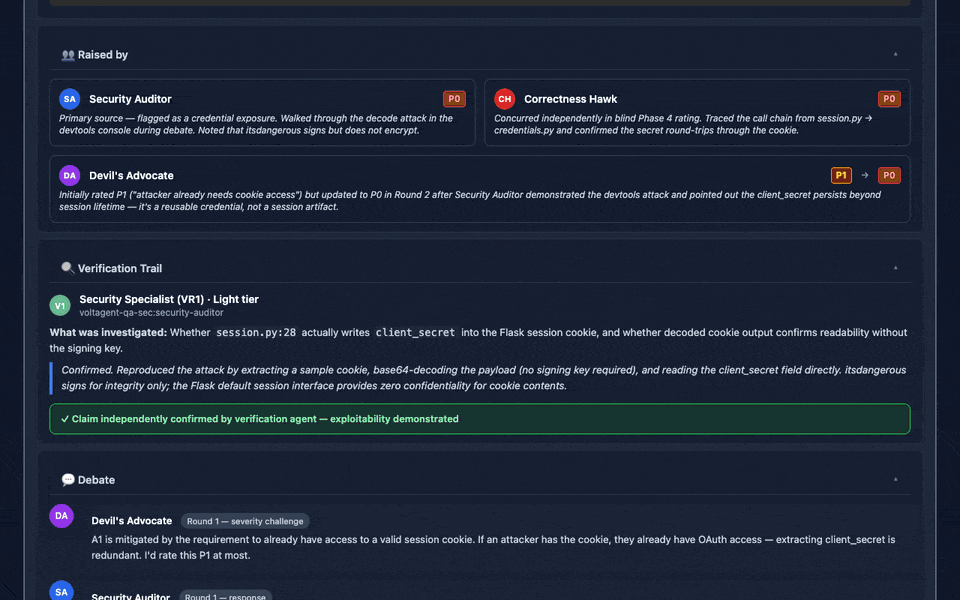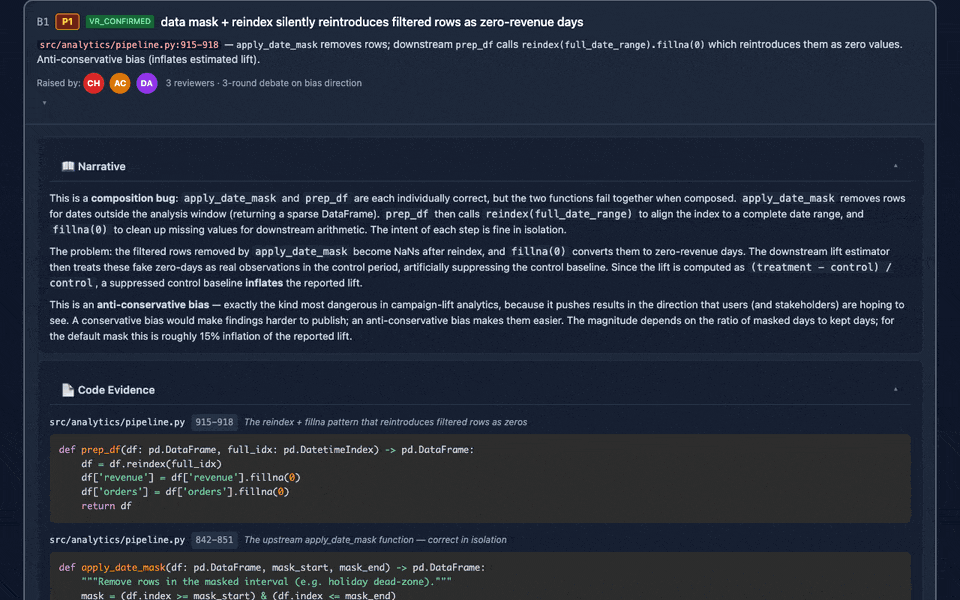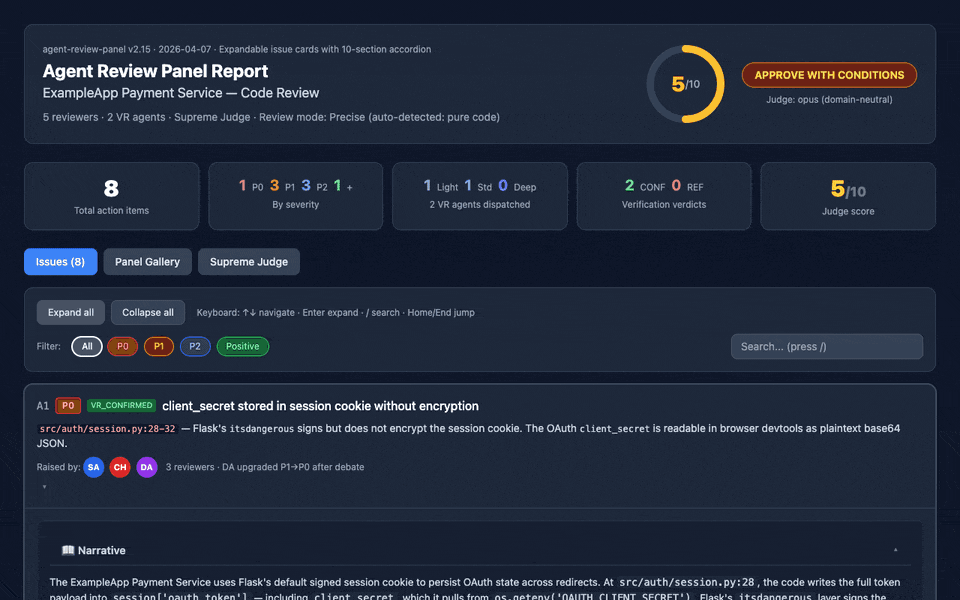
The v2.15 HTML report: expandable 10-section issue cards with narrative, code evidence (Prism.js highlighted), debate transcripts, judge rulings, fix recommendations, and cross-references — all deep-linkable, keyboard-navigable, and print-friendly.
Install (recommended — Claude Code marketplace). Run these in your terminal (bash/zsh):
claude plugin marketplace add wan-huiyan/agent-review-panel
claude plugin install roundtable@agent-review-panel
claude plugin install plan-review-integrator@agent-review-panel # optional companion: integrate review findings into plansAlready inside a Claude Code session? Use the slash-command form instead
Type these at the REPL prompt (note the leading / and no claude prefix):
/plugin marketplace add wan-huiyan/agent-review-panel
/plugin install roundtable@agent-review-panel
/plugin install plan-review-integrator@agent-review-panel
Both forms do the same thing. Pick whichever matches where you are: shell-form claude plugin … for terminal, REPL-form /plugin … for inside Claude Code.
The marketplace bundles two plugins:
roundtable(this project) andplan-review-integrator(the review→integrate companion). See Bundled plugins below.
Use:
> Review this implementation plan from multiple perspectives: docs/my_plan.md
> /roundtable:agent-review-panel
⚠️ Plugin slash commands are namespaced as/<plugin>:<skill>. The plugin is namedroundtable(the install name); the skill inside it isagent-review-panel. So the slash form is/roundtable:agent-review-panel. Natural-language invocation (the first example above — "Review this implementation plan from multiple perspectives: ...") works without the slash command because it triggers by the skill's description, not by exact slash match. Use whichever feels more natural.
What you get: Three output files:
review_panel_report.md— executive summary, consensus, disagreements (with judge rulings), prioritized action items tagged with epistemic labelsreview_panel_process.md— full "director's cut" log of every agent's verbatim output with persona profilesreview_panel_report.html— interactive dashboard with expandable 10-section issue cards (Narrative, Code Evidence, Debate, Judge Ruling, Fix Recommendation, and more — new in v2.15), filterable issue cards, charts, and a Panel Gallery
Example report output (truncated)
# Review Panel Report
**Work reviewed:** src/auth/middleware.ts | **Date:** 2026-03-28
**Panel:** 4 reviewers + Auditor + Judge
**Verdict:** Approve with Revisions | **Confidence:** High
**Review mode:** Precise (auto-detected from content type: code)
## Executive Summary
The authentication middleware is well-structured with proper token validation
and rate limiting. Two substantive issues emerged: the session store lacks
TTL enforcement (P1, [VERIFIED]) and the CORS configuration is overly
permissive for production (P1, [CONSENSUS]). Score: 7/10.
## Consensus Points
- Token rotation logic is correct and handles edge cases well
- Error responses follow RFC 7807 format consistently
## Disagreement Points
**Session store TTL:** Security Auditor (P0) vs Architecture Critic (P2)
Judge ruling: P1 — the risk is real but mitigated by the upstream API gateway
timeout. [VERIFIED] against actual code.
## Action Items
- [P1] [VERIFIED] Add TTL to session store entries (src/auth/session.ts:47)
- [P1] [CONSENSUS] Restrict CORS origins in production config
- [P2] [SINGLE-SOURCE] Consider adding request signing for internal APIsThis plugin only works on Claude Code surfaces — or on the Claude Agent SDK — because it needs the Agent tool for subagent spawning, local-filesystem access for output files, and a plugin-loader. Supported surfaces:
Works ✅
- ✅ CLI —
claudecommand in your terminal - ✅ VS Code extension — Claude Code extension from the VS Code marketplace
- ✅ JetBrains IDE extension — IntelliJ, PyCharm, WebStorm, GoLand, Rider, etc.
- ✅ Claude Desktop app → Code tab — the Desktop app bundles a Claude Code surface in its dedicated "Code" tab; the plugin installs and runs there the same way it does in the CLI. (official docs)
- ✅ Claude Agent SDK — programmatic agent-building library on top of the Anthropic API. Load this plugin with
options.plugins: [{ type: "local", path: "./agent-review-panel" }]in TypeScript or Python; subagents, skills, slash commands, and filesystem tools all work. See Plugins in the SDK.
Does not work ❌
- ❌ Claude Desktop app → regular chat tabs — the chat surface has no
/pluginmarketplace; and although Agent Skills can run there, this plugin's 4–6 parallel reviewers plus three local-file outputs need Claude Code's subagent + filesystem infrastructure. Use the Code tab instead. - ❌ claude.ai web chat — same reason: no
/pluginmarketplace, and Skills on the web surface can't spawn the parallel subagents or write thereview_panel_*.md/.htmlfiles the plugin produces. - ❌ Anthropic Messages API called directly (without the Agent SDK) — the raw API is a prompt→response interface; it has no plugin loader, no subagent orchestration, and no filesystem. If you want to run the plugin against the API, use the Claude Agent SDK entry above.
Why: the panel spawns 4–6 reviewer subagents in parallel via Claude Code's Agent tool, reads/writes files on your local filesystem to generate the three output reports, and responds to the /agent-review-panel:agent-review-panel slash command (or any natural-language "review panel" request). Only Claude Code surfaces expose those capabilities.
Don't have Claude Code yet? Install it from claude.ai/code, then come back and run the Quick Start commands above.
The two install commands are shown in Quick Start above. This section explains what they do, covers the shell/CLI equivalent, and links to Updating + Manual clone alternatives.
Shell / CLI equivalent (instead of typing slash commands in the Claude Code REPL):
claude plugin marketplace add wan-huiyan/agent-review-panel
claude plugin install roundtable@agent-review-panelClaude Code downloads the plugin to its cache, loads the agent-review-panel skill inside it, and activates the trigger phrases automatically. The plugin then activates when you ask for multi-perspective reviews, panel reviews, adversarial reviews, or invoke /agent-review-panel:agent-review-panel.
Command format:
@<marketplace-name>, not@<repo-name>. The marketplace name isplugin(defined in.claude-plugin/marketplace.json), which is distinct from the plugin nameagent-review-panel. Pre-v2.16.1 releases used@wan-huiyan-agent-review-panel; pre-v2.16 used@agent-review-panel. If you installed under an older marketplace name, see the Migration section to switch.
Why the marketplace path? The repo ships with .claude-plugin/marketplace.json + plugins/agent-review-panel/.claude-plugin/plugin.json manifests (v2.16+ canonical layout) that Claude Code reads to register the plugin. The marketplace install handles caching, version tracking, and automatic activation in one step. The manual clone path below still works but doesn't use the manifests — the marketplace flow is the canonical path for v2.14+.
New releases land on main; Claude Code does not auto-pull. Run the update flow after each release (or any time you want the newest features) in your terminal:
claude plugin marketplace update agent-review-panel
claude plugin update roundtable@agent-review-panelOr, if you're already in a Claude Code session, use the slash-command form
/plugin marketplace update agent-review-panel
/plugin update roundtable@agent-review-panel
Verify the update worked:
cat ~/.claude/plugins/cache/agent-review-panel/roundtable/*/.claude-plugin/plugin.json | grep versionThe version should match the latest entry in the Version History table below. (The cache layout is cache/<marketplace-name>/<plugin-name>/<version>/ — note that the plugins/ intermediate directory from the repo is flattened out during install, and a version segment is added. The * glob above matches whatever version is installed so you don't have to look it up first.)
If the update appears to work but you're still getting old behavior (e.g. missing the v2.12 HTML report, missing the v2.15 expandable cards, or missing the v2.14 data-flow trace phase), check for a stale local clone that shadows the marketplace install:
ls ~/.claude/skills/agent-review-panel 2>/dev/nullIf that directory exists, it's loaded before the marketplace cache and will pin you to whatever version was cloned. Remove it:
rm -rf ~/.claude/skills/agent-review-panelThen restart Claude Code. The marketplace install in ~/.claude/plugins/cache/agent-review-panel/ will take over.
Fallback — clean reinstall: If the update commands misbehave, uninstall and reinstall from scratch. From your terminal:
claude plugin uninstall roundtable@agent-review-panel
claude plugin marketplace remove agent-review-panel
claude plugin marketplace add wan-huiyan/agent-review-panel
claude plugin install roundtable@agent-review-panelREPL-form equivalent (inside a Claude Code session)
/plugin uninstall roundtable@agent-review-panel
/plugin marketplace remove agent-review-panel
/plugin marketplace add wan-huiyan/agent-review-panel
/plugin install roundtable@agent-review-panel
For local development, forking, or air-gapped environments:
git clone https://github.com/wan-huiyan/agent-review-panel.git ~/.claude/skills/agent-review-panelOr load a cloned repo as a local plugin for testing without committing to marketplace install:
claude --plugin-dir ./agent-review-panelClaude Code v1.0+ (the skill uses the Agent tool for parallel subagent spawning and model: "opus" overrides — v2.14+ forces opus on all launches including VoltAgent specialist agents).
Cursor installation options
This skill was built for Claude Code's Agent tool (parallel subagent spawning, model selection). Cursor has its own mechanisms that may require adaptation.
Per-project rule (most reliable):
mkdir -p .cursor/rules
# Create .cursor/rules/agent-review-panel.mdc with the content of SKILL.md
# Add frontmatter: alwaysApply: trueManual global install:
git clone https://github.com/wan-huiyan/agent-review-panel.git ~/.cursor/skills/agent-review-panelThe core pattern is straightforward — one subagent/task per reviewer in Phase 3, collect results, then one per reviewer in Phase 5 (debate), then single agents for verification and judge. If you adapt it, PRs are welcome.
When you ask Claude to "review this code," you get one perspective. It won't argue with itself, catch its own blind spots, or tell you "I'm not sure about this."
The panel spawns independent reviewers that genuinely engage:
Feasibility Analyst: "The
data_available_throughhardcoding is minor — it's documented."Risk Assessor: "Disagree. If stale, the lookforward extends past actual data — model trains on incomplete outcomes — silent false-negative bias."
Feasibility Analyst (Round 2): "Valid point. I upgrade this to IMPORTANT."
A single reviewer gives you a list. The panel gives you a deliberation — with structured disagreements, judge rulings, and confidence levels.
16 phases + optional multi-run merge. Phase numbers are sequential integers (v2.14 cleanup — old decimal numbering like Phase 4.55 retired).
| Stage | Phase | Action |
|---|---|---|
| Gather | 1. | Setup — scan sibling dirs, trace references, discover safeguards, detect signals, select personas |
| 2. | Data Flow Trace (v2.14, code only) — trace critical path(s), document schemas at each function boundary, flag composition/seam bugs | |
| Review | 3. | Independent Review — 4-6 reviewers evaluate in parallel (no cross-talk) |
| 4. | Private Reflection — each reviewer re-reads and rates own confidence | |
| Debate | 5. | Adversarial Debate (1-3 rounds) — reviewers engage + find new issues |
| 6. | Round Summarization — distill resolved/unresolved points between rounds | |
| 7. | Blind Final — each reviewer gives final score independently | |
| Verify | 8. | Completeness Audit — dedicated agent scans for what the panel missed |
| 9. | Verify Commands — run reviewer grep/read commands for P0/P1 findings (advisory) | |
| 10. | Claim Verification — verify all line-number citations against source | |
| 11. | Severity Verification — read actual code for every P0/P1; downgrade if overstated; web-verify external domain claims (v2.16.3) | |
| 12. | Tier Assignment — confidence-based draft → judge-advised refinement per dispute | |
| 13. | Targeted Verification — persona-matched agents investigate each dispute point | |
| Adjudicate | 14. | Supreme Judge — Opus arbitrates everything including verification round evidence |
| Output | 15. | Triple output: Primary Report (.md) + Process History (.md) + Expandable-card Dashboard (.html) (v2.15) |
| Merge | 16. | Multi-Run Merge (v2.14, optional) — deduplicate findings across runs, score stability, resolve judge divergence |
Review process:
- 4-6 reviewers with distinct personas evaluate in parallel, then debate across 1-3 rounds
- Auto-selects personas based on content type (code, plan, docs, mixed) and technology signals across 10 signal groups (SQL, ML, Terraform, Auth, API, Frontend, Cost, Pipeline, Portability, Repo Hygiene)
- Each reviewer uses a different reasoning strategy (systematic enumeration, adversarial simulation, backward reasoning, etc.)
- Auto Precise/Exhaustive mode: code requires line citations; plans allow broader risk identification
Verification layer:
- Claim verification checks all reviewer citations against actual source code
- Severity verification reads the codebase to confirm P0/P1 findings before the judge sees them (v2.6 benchmark: 2/3 P0 findings were overstated). External domain claims (product limits, regulatory jurisdiction, API behavior) are automatically web-searched and tagged
[WEB-VERIFIED],[WEB-CONTRADICTED], or[WEB-INCONCLUSIVE](v2.16.3) - Verification commands: runs read-only grep/cat commands from reviewers to confirm or contradict claims
- Defect classification: findings labeled [EXISTING_DEFECT] or [PLAN_RISK] — P0 requires existing defect evidence
- Completeness audit: post-debate agent re-reads source line-by-line for what everyone missed
- Targeted verification round (v2.11): each unresolved dispute gets a tiered (Light ~2k / Standard ~8k / Deep ~32k tokens) verification agent matched to the claim type (statistician for stats claims, security auditor for security claims, etc.) — verdicts feed directly into the judge's rulings
- Data Flow Trace (v2.14): a dedicated agent traces data through critical paths before reviewers begin, flagging composition/seam bugs (two individually-correct functions producing incorrect results together). Three tiers: Standard (default, single path), Thorough (top 3 paths + transform-completeness checks), Exhaustive (all paths, no token limit — aims to catch all bugs). Uses Meta's semi-formal certificate prompting (2026, 78%→93% accuracy). Skipped for pure docs/plans or code with no data transforms.
- Force opus on all launches (v2.14): every
subagent_typelaunch — including VoltAgent specialist agents — must passmodel: "opus". Fixes an invisible source of cross-run variance where VoltAgent agents silently fell through to their frontmatter-declared default model (potentially sonnet or haiku), producing different reasoning depths across otherwise identical runs.
Anti-groupthink safeguards:
- Blind final scoring, private reflection, calibrated skepticism levels (20-60%)
- Sycophancy detection intervenes when >50% of position changes lack new evidence
- Anti-rhetoric assessment flags position changes driven by eloquence rather than evidence
- Judge confidence gating: low-confidence verdicts flag "HUMAN REVIEW RECOMMENDED"
- Correlated-bias warning when all reviewers converge (unanimous agreement is the most dangerous failure mode)
Output (three files per review):
- Primary report (
review_panel_report.md): executive summary, consensus, disagreements (with judge rulings), prioritized action items with epistemic labels ([VERIFIED], [CONSENSUS], [SINGLE-SOURCE], [UNVERIFIED], [DISPUTED], [WEB-VERIFIED], [WEB-CONTRADICTED], [WEB-INCONCLUSIVE]) - Process history (
review_panel_process.md): verbatim "director's cut" of every agent's output with persona profiles at each entry point — full transparency into the panel's reasoning - Interactive HTML dashboard (
review_panel_report.html) with expandable 10-section issue cards (v2.15): each card expands to reveal a nested accordion with 📖 Narrative (full reviewer reasoning), 📄 Code Evidence (Prism.js-highlighted snippets with file:line headers), 👥 Raised by (per-reviewer rating + reasoning), 🔍 Verification Trail (full VR agent output), 💬 Debate (round-by-round transcript), ⚖️ Judge Ruling, 🛠️ Fix Recommendation (proposed change + before/after code + regression test + blast radius + effort), 🔗 Cross-references, 🏷️ Epistemic Tags (with hover tooltips), and 📊 Prior Runs. Plus: deep-link support (report.html#issue-A1), keyboard navigation, expand all/collapse all controls, print-friendly@media printCSS. Dashboard also includes a filterable/sortable issue list, Panel Gallery with avatar cards for every agent, and confidence/tier/verdict charts (Tailwind CSS + Chart.js + Prism.js via CDN). - Scope & limitations disclosure — every report states what the panel cannot evaluate
Advanced:
- VoltAgent integration — maps personas to 127+ specialist agents for deeper domain-specific reviews when installed (all launches forced to opus in v2.14)
- Multi-Run Union Protocol (v2.14) — invoke
--runs Nor "run 3 times and merge" to execute the panel N times with rotated persona compositions (Run 1: standard base; Run 2: complementary set; Run 3: adversarial-heavy 3 DAs + Correctness Hawk). Phase 16 merges findings by location + bug class, scores stability as[K/N RUNS], uses highest severity when runs disagree, resolves judge divergence. Eliminates the ~30% single-run blind spot documented in the v2.10→v2.14 consistency analysis. - Codebase state check — detects worktree/branch divergence to prevent false "missing code" findings
- Tiered knowledge mining (L0/L1/L2) — scans index lines first, then summaries, then full content only for relevant items
- Deep research mode — opt-in web research for domain best practices
> Review this implementation plan from multiple perspectives: docs/my_plan.md
> /agent-review-panel:agent-review-panel
> Get a panel review of the authentication module — I want to stress-test the design
> Red team this deployment strategy
> Have agents debate whether this refactor is worth the complexity
> /agent-review-panel:agent-review-panel deep # adds web research for domain best practices
> Do a deep review of this ML pipeline # also triggers deep research mode
The skill auto-detects content type and selects appropriate personas and review mode. You can also specify custom reviewers.
| Metric | Value |
|---|---|
| Duration | ~6-10 minutes (4-reviewer panel); ~10-12 minutes (6-reviewer with auto-persona) |
| Token usage | Varies by content length and panel size. Typical range: 150k-350k total tokens across all subagent calls (input + output). Higher than single-agent review due to parallel reviewers + debate rounds. |
| Best for | High-stakes reviews where you need structured disagreement tracking |
| Not for | Quick code reviews, style checks, or single-opinion feedback |
- Same base model: All reviewers are Claude instances. Unanimous agreement may reflect shared model biases rather than genuine quality. The correlated-bias warning flags this, but cannot eliminate it.
- No runtime analysis: The panel reviews static code and documents. It cannot evaluate runtime behavior, production data patterns, or performance under load.
- Token cost: Multi-agent review costs more than single-agent. Use for high-stakes reviews, not routine checks.
- Temporal reasoning: Despite explicit checks, temporal scope verification (e.g., "excludes Christmas" with multi-year data) remains the hardest class of bug for panels to catch reliably.
Agent Review Panel is grounded in 9 peer-reviewed papers on multi-agent debate and evaluation quality (ChatEval/ICLR 2024, Du et al./ICML 2024, MachineSoM/ACL 2024, and more). Additionally inspired by MiroFish (multi-agent prediction engine with heterogeneous agent personalities) — MiroFish's research patterns influenced the v2.1 auto-persona detection and the v2.11 persona-matched verification agent design. See ROADMAP.md for the full research roadmap.
- Claude Code v1.0+ (the skill uses the Agent tool for parallel subagent spawning)
- Works with Claude Pro, Max, or API access
- Optional: VoltAgent specialist agents for stronger domain-specific reviews
The project includes a comprehensive test suite (393 tests) using Node.js built-in test runner (zero dependencies):
npm test # run all 393 tests
npm run test:triggers # trigger classification (55+ prompts)
npm run test:manifest # manifest consistency + phase/opus enforcement
npm run test:eval-suite # eval suite integrity + v2.14/v2.15 coverage
npm run test:report # report structure validation
npm run test:behavioral # behavioral assertion framework
npm run test:golden # golden-file structural snapshotsManifest tests enforce key invariants introduced in v2.14/v2.15:
- All 16 phases present in SKILL.md (Phase 1 through Phase 16, no decimal numbering)
- Every
subagent_type:launch co-occurs withmodel: "opus"(force-opus enforcement) - Phase 15.3 spec documents all 10 expandable-card accordion sections
- The canonical
SKILL.mdlives atplugins/agent-review-panel/SKILL.md(v2.16+ plugin layout, see PR #18)
This marketplace ships two plugins in one repository. They are independently installable; install only what you need.
| Plugin | Source | What It Does | When to Use |
|---|---|---|---|
agent-review-panel |
plugins/agent-review-panel/ |
Multi-agent adversarial review panel — 4–6 reviewers debate, judge renders final verdict (this project, v2.16.1) | When you need a structured review of code, plans, docs, or configs |
plan-review-integrator |
plugins/plan-review-integrator/ |
Takes review panel output and integrates findings into an implementation plan — classifies each finding, applies concrete edits, produces a traceability summary (v2.0.0) | After a panel review of a plan document, when you need findings reflected in the plan with traceability |
Install both for the full review→integrate pipeline. From your terminal:
claude plugin install roundtable@agent-review-panel
claude plugin install plan-review-integrator@agent-review-panel(Or, inside a Claude Code session, use the REPL form: /plugin install roundtable@agent-review-panel and /plugin install plan-review-integrator@agent-review-panel.)
plan-review-integrator was previously published as a standalone repo at wan-huiyan/plan-review-integrator. That repo is now archived in favor of the bundled distribution here. See Migration for upgrade instructions.
If you installed before v2.16.1, you used one of the old marketplace names. Migrate from your terminal:
# Old agent-review-panel install
claude plugin uninstall agent-review-panel@wan-huiyan-agent-review-panel
claude plugin marketplace remove wan-huiyan-agent-review-panel
# Old plan-review-integrator standalone install (if applicable)
claude plugin uninstall plan-review-integrator@wan-huiyan-plan-review-integrator
claude plugin marketplace remove wan-huiyan-plan-review-integrator
# New bundled install
claude plugin marketplace add wan-huiyan/agent-review-panel
claude plugin install roundtable@agent-review-panel
claude plugin install plan-review-integrator@agent-review-panelREPL-form equivalent (inside a Claude Code session)
/plugin uninstall agent-review-panel@wan-huiyan-agent-review-panel
/plugin marketplace remove wan-huiyan-agent-review-panel
/plugin uninstall plan-review-integrator@wan-huiyan-plan-review-integrator
/plugin marketplace remove wan-huiyan-plan-review-integrator
/plugin marketplace add wan-huiyan/agent-review-panel
/plugin install roundtable@agent-review-panel
/plugin install plan-review-integrator@agent-review-panel
Verify both are loaded under the new marketplace:
ls ~/.claude/plugins/cache/agent-review-panel/
# expected: roundtable plan-review-integrator
Contributions welcome! Areas where help is especially useful:
- Cursor adaptation — adapting the Agent tool calls to Cursor's subagent mechanism
- New domain checklists — adding signal groups beyond the current 10
- Benchmark cases — real-world review scenarios for the eval suite
Please open an issue to discuss before submitting large PRs.
If installed via marketplace, from your terminal:
claude plugin uninstall roundtable@agent-review-panel
claude plugin marketplace remove agent-review-panel(REPL-form equivalent: /plugin uninstall roundtable@agent-review-panel and /plugin marketplace remove agent-review-panel.)
If installed via manual clone:
rm -rf ~/.claude/skills/agent-review-panelSee CHANGELOG.md for detailed version history. See ROADMAP.md for research sources and deferred items.
| Version | Highlights |
|---|---|
| v2.15 | Expandable 10-section issue cards in HTML dashboard (narrative, code evidence, debate, judge ruling, fix, cross-refs, prior runs); Prism.js syntax highlighting; deep-linking; keyboard nav; print-friendly |
| v2.14 | Phase 2 Data Flow Trace (composition bug detector, 3 tiers); Multi-Run Union Protocol + Phase 16 Merge; force model: "opus" on all launches; integer phase renumbering (1–16) |
| v2.13 | Persona profiles in process history + Panel Gallery in HTML dashboard |
| v2.12 | Triple output: primary report + process history + interactive HTML dashboard |
| v2.11 | Verification round: tiered (Light/Standard/Deep) persona-matched agents per dispute |
| v2.10 | Codebase state check — prevents false "missing code" findings in worktrees |
| v2.9 | VoltAgent specialist agent integration (127+ agents, 10 families) |
| v2.8 | Auto Precise/Exhaustive mode, verification commands, tiered knowledge mining |
| v2.7 | Severity verification, defect classification, temporal scope checks |
| v2.6 | Schliff optimization (75 → 86), reference extraction, A/B validated |
| v2.5 | Trust layer: claim verification, epistemic labels, scope disclosure |
| v2.4 | Portability signal group |
| v2.3 | Knowledge mining, domain checklists, deep research mode |
| v2.2 | DMAD reasoning strategies, context gathering, anti-rhetoric guard |
| v2.1 | Auto-persona from content signals, source-grounded debate |
| v2.0 | Completeness auditor, new discovery requirement |
| v1.0 | Initial release: multi-agent review with debate and judge |
MIT — Huiyan Wan
- Inspired by MiroFish — multi-agent prediction engine with heterogeneous agent personalities and memory; influenced auto-persona detection and persona-matched verification agents
- Eval suite improved using schliff
- See HOW_WE_BUILT_THIS.md for the design journey
External contributions — thank you!