This project implements a modern data engineering pipeline on Azure using the Medallion Architecture (Bronze → Silver → Gold) to process NYC taxi trip data.
The pipeline ingests raw trip data, cleans and enriches it, and produces aggregated insights for analytics. It is designed to be incremental, scalable, and production-ready using Azure Databricks, Delta Lake, and Unity Catalog.
- Build an end-to-end data pipeline using Databricks
- Implement incremental data processing
- Apply data quality checks and transformations
- Design Slowly Changing Dimension (SCD Type 2) logic
- Deliver analytics-ready datasets and external exports
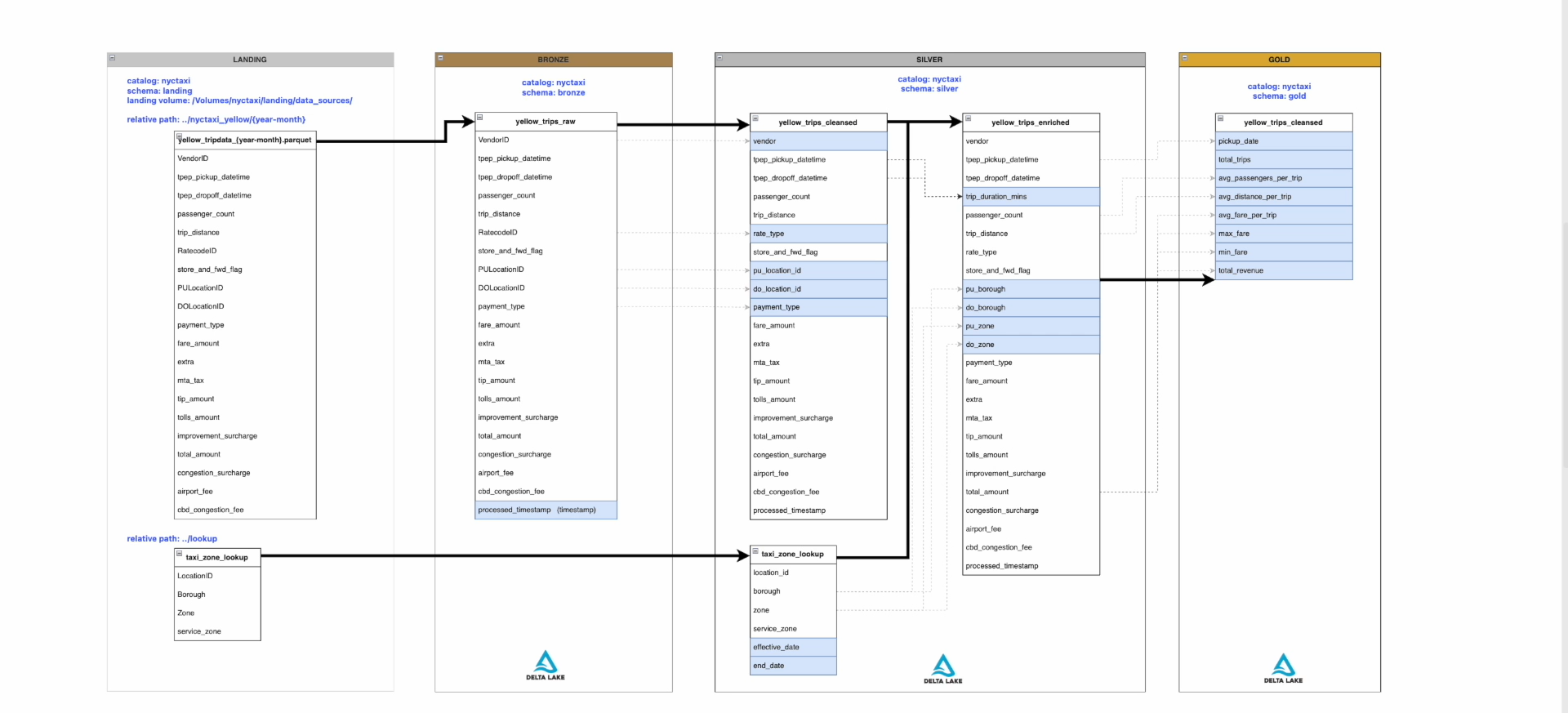
- Stores raw ingested data from source files
- Source: yellow_tripdata_YYYY-MM.parquet
- Minimal transformation (schema enforcement, metadata columns)
- Table: yellow_trips_raw
Purpose: Data cleansing + enrichment
- yellow_trips_cleansed
- Cleaned data (null handling, type casting, filtering invalid records)
- yellow_trips_enriched
- Trip duration
- Pickup & dropoff zones
- Borough mapping
- taxi_zone_lookup
- Implemented as SCD Type 2
- Tracks historical changes using:
- effective_date
- end_date
Purpose: Business-level aggregations
- daily_trip_summary
- total trips
- avg passengers per trip
- avg distance
- avg fare
- min/max fare
- total revenue
- Processes one month at a time
- Always processes data from 2 months prior (due to vendor delay)
- Skips:
- Already processed data
- Missing data
- Uses append-only strategy with Delta Lake
- Trip duration calculation
- Data validation (remove invalid trips)
- Joins with taxi zone lookup
- Partitioning by vendor + month
A Databricks Job orchestrates notebook tasks:
- Load raw data → Bronze
- Cleanse data → Silver (cleansed)
- Enrich data → Silver (enriched)
- Aggregate data → Gold
✔ Handles dependencies between tasks
✔ Runs on a schedule (monthly)
✔ Supports retry & failure handling
Export processed data for external data teams.
- Export yellow_trips_enriched as partitioned JSON
- Destination: Azure Data Lake Storage Gen2
- Path:
nyctaxi_yellow_export/
- Created Storage Account + Container
- Unity Catalog External Location
- External Table (nyctaxi.04_export)
- Data is:
- Partitioned by vendor and month
- Appended monthly
- Azure Databricks
- Delta Lake
- Unity Catalog
- Azure Data Lake Storage Gen2 (ADLS)
- PySpark / Spark SQL
- Databricks Workflows (Jobs)
- Medallion architecture implementation
- Incremental & idempotent pipeline
- SCD Type 2 dimension handling
- External data sharing via ADLS
- Partitioned data for performance
- Production-style orchestration
- Upload source files (yellow_tripdata_YYYY-MM.parquet)
- Configure storage & Unity Catalog
- Run Databricks Job
- Monitor pipeline execution
- Validate output in Gold & Export layers
- Designing scalable data lakehouse architectures
- Handling incremental ETL pipelines
- Implementing SCD Type 2 in Spark
- Managing data governance with Unity Catalog
- Building production-ready pipelines in Databricks
“I built an end-to-end data pipeline on Azure Databricks using the Medallion architecture. I ingest raw NYC taxi data into Bronze, clean and enrich it in Silver—including implementing an SCD Type 2 dimension for taxi zones—and aggregate it into Gold for analytics.
The pipeline is incremental, processes one month at a time with a 2-month lag, and avoids reprocessing. I orchestrated everything using Databricks Jobs and also built an external data export pipeline to ADLS in partitioned JSON format for downstream teams.”