Project plan
The aim of this project is to recive a sequenced genome of a Durian (Durian zibethinus Musang King) fruit, as neither the fruit itself or any species in its subfamily Helicteroidae has been sequenced before. Two other species in the same order, Malvales, have been sequenced before though, these are cotton and cacao. Durian fruit has both an interesting odor, an economic value and popular as food in some countries in the world. This makes the fruit interesting to investigate more. Something that can be tried to answer during this project is what genes causes the special odor of the fruit as well as how the processes of for example ripening works.
The analyses that will be performed, and in what order, can be seen in the figure below. Each left box represents the performed analysis in that step, and the right box beside reference to which software will be used for this. Also, there is a hourglass in those steps that takes a lot of time (takes one hour or more) to perform and therefore might be a bottleneck during the project. The trimming and second quality check of Illumina DNA will be skipped as it already has been done, these steps are marked with parenthesis. The output and input format of some specific steps are also stated between the analysis steps.
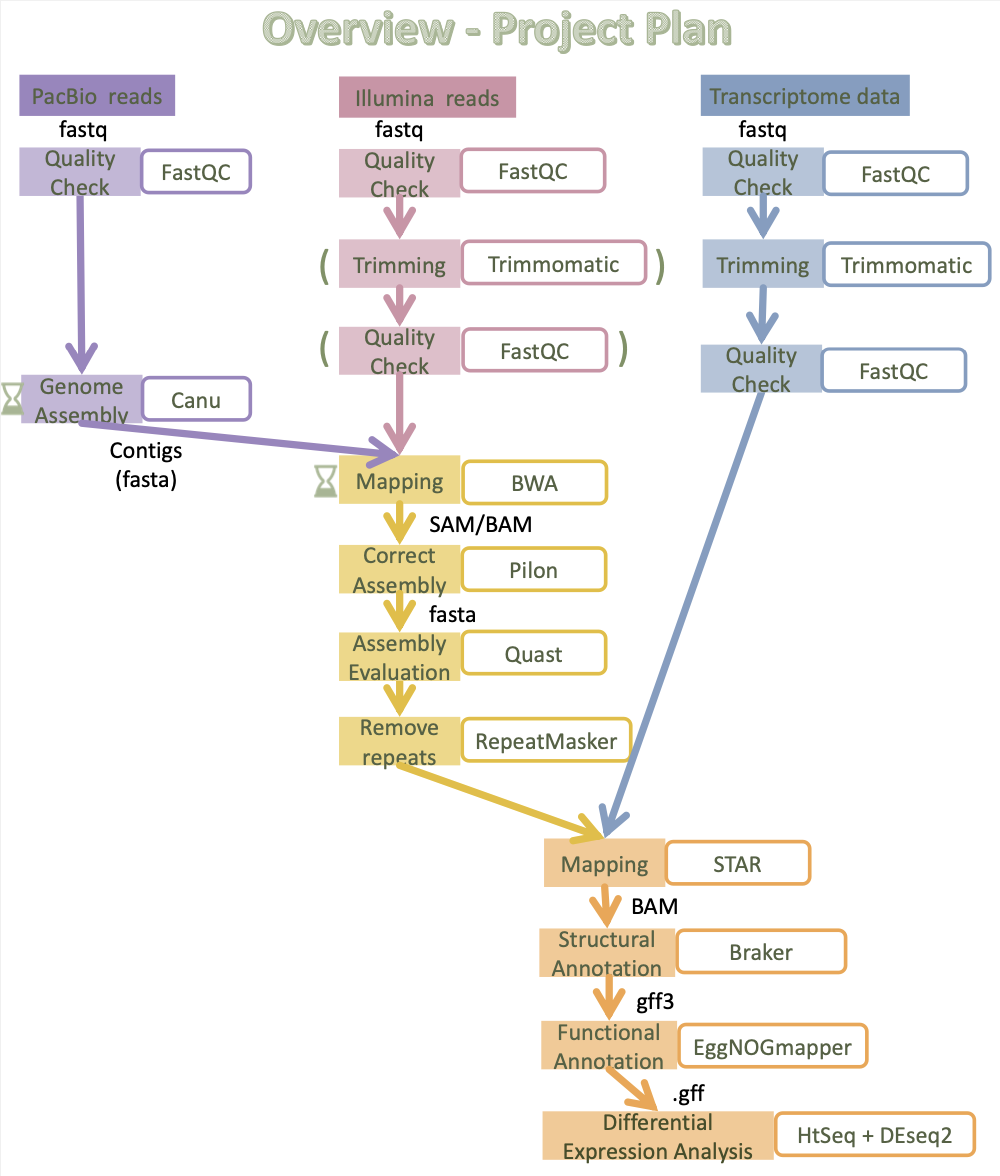
Figure 1. Workflow of the analysis steps in the project with the used software to the right.
The steps that might be bottlenecks are the genome assembly with the software Cane that can take 17 hours, also the mapping with BWA which can take one hour.
Below the checkpoints that will be followed during the project are presented. From the start of this project plan, to the end of the presentation of the project.
- 29/3: Project plan
- 8/4: Compulsory computer lab, finished organizing repository + started running software
- 19/4: Genome assembly
- 28/4: RNA mapping
- 11/5: Annotation + finished with running softwares
- 13/5: Compulsory computer lab, be as finished as possible
- 18/5: Hand in presentation + GitHub
- 24/5: Give the presentation
The data consist of DNA samples taken from the the fruit stalk of Durian zibethinus Musang King, which has been analysed with Illumina producing short reads, and also with PacBio producing long reads. Above this samples has been taken from the leaf, root, stem and aril were transcriptome data (RNA) were collected and analysed with Illumina. Some aril samples were also taken from Durian zibethinus Monthong for transcriptome data. This is presented in the table below.
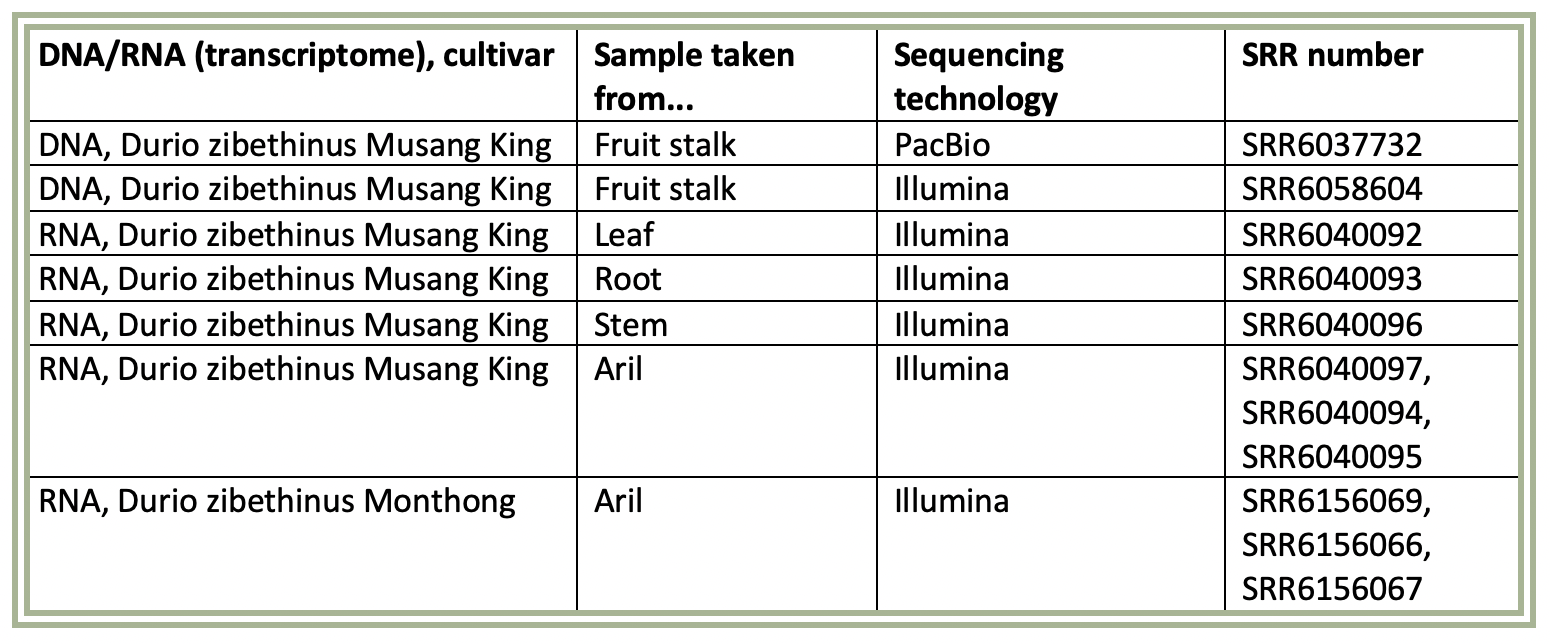
The used data will probably take a lot memory to store as it is from an eukaryot organism and is whole genome sequenced. To make this possible to use without exceeding the 32 GB memory available symbolic links to the data will be used to avoid copying the raw data. Large files will also be compressed. In case the available space is allocated anyway, an extra folder will be created in the project directory to store some of my data in.
The metadata will be stored in an excel spreadsheet. The spreadsheet will be well structured a way such that it will be possible for a computer to read the table.
The organisation of the project directory will be divided into three main folders. One folder, Data, for larger data were there is no possibility to edit the files. Another folder, Analyses, will contain code and smaller files such as figures and results. A third folder, Code, which will contain code scripts used in the project. Subfolders will be created to structure the data in each of the main folders.
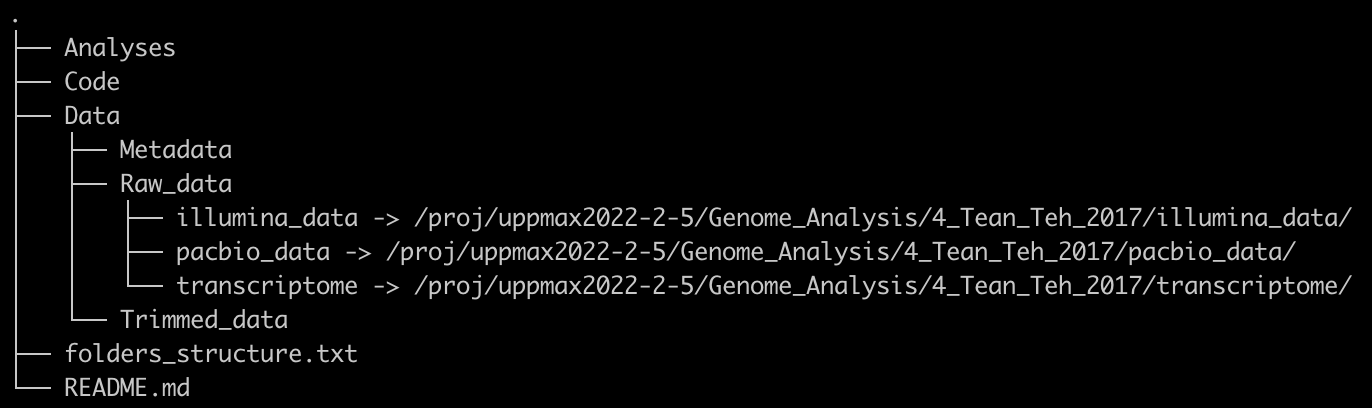
Some things will be keept in mind to keep a good organisation, that is...
- to use informative names.
- to begin figures with prefix "figXX" and outfiles with prefix "resXX" to keep the files in the order they are produced.
- The names will be structured in the way that symbolic links will be prefixed "->". Original files will stay with original names.
- SAM and FASTQ files will be compressed to save space. Compressed files will have the ending ".gz".